4.13. Exercises¶
Question 1
Use the distillation column data set and choose any two variables, one for \(\mathrm{x}\) and one as \(\mathrm{y}\). Then fit the following models by least squares in any software package you prefer:
Solution Click to show answer
\(y_i = b_0 + b_1 x_i\)
\(y_i = b_0 + b_1 (x_i - \overline{x})\) (what does the \(b_0\) coefficient represent in this case?)
\((y_i - \overline{y}) = b_0 + b_1 (x_i - \overline{x})\)
Prove to yourself that centering the \(\mathrm{x}\) and \(\mathrm{y}\) variables gives the same model for the 3 cases in terms of the \(b_1\) slope coefficient, standard errors and other model outputs.
Question 2
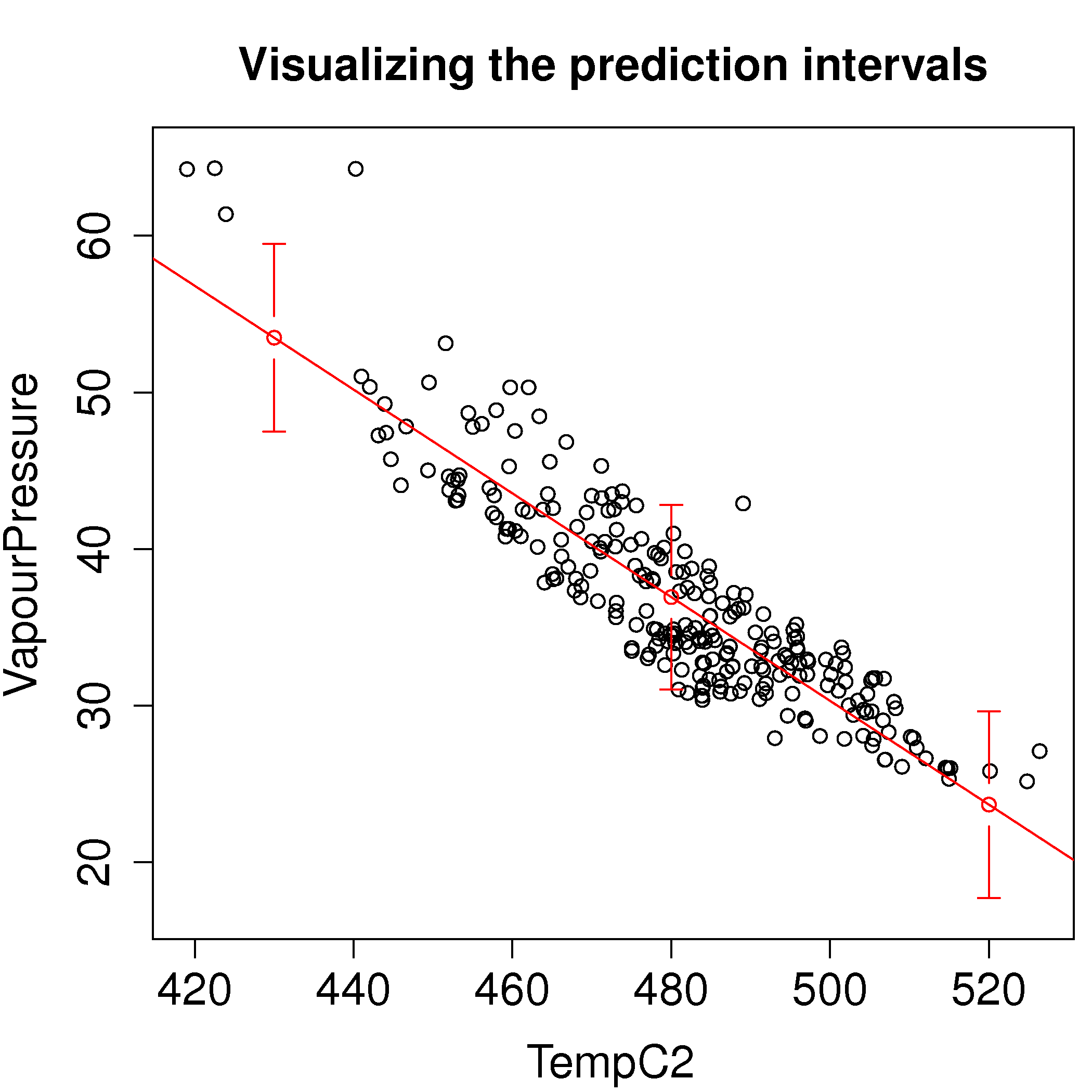
For a \(x_{\text{new}}\) value and the linear model \(y = b_0 + b_1 x\) the prediction interval for \(\hat{y}_\text{new}\) is:
\[\hat{y}_i \pm c_t \sqrt{V\{\hat{y}_i\}}\]where \(c_t\) is the critical t-value, for example at the 95% confidence level.
Use the distillation column data set and with \(\mathrm{y}\) as VapourPressure (units are kPa) and \(\mathrm{x}\) as TempC2 (units of degrees Farenheit) fit a linear model. Calculate the prediction interval for vapour pressure at these 3 temperatures: 430, 480, 520 °F.
Question 3
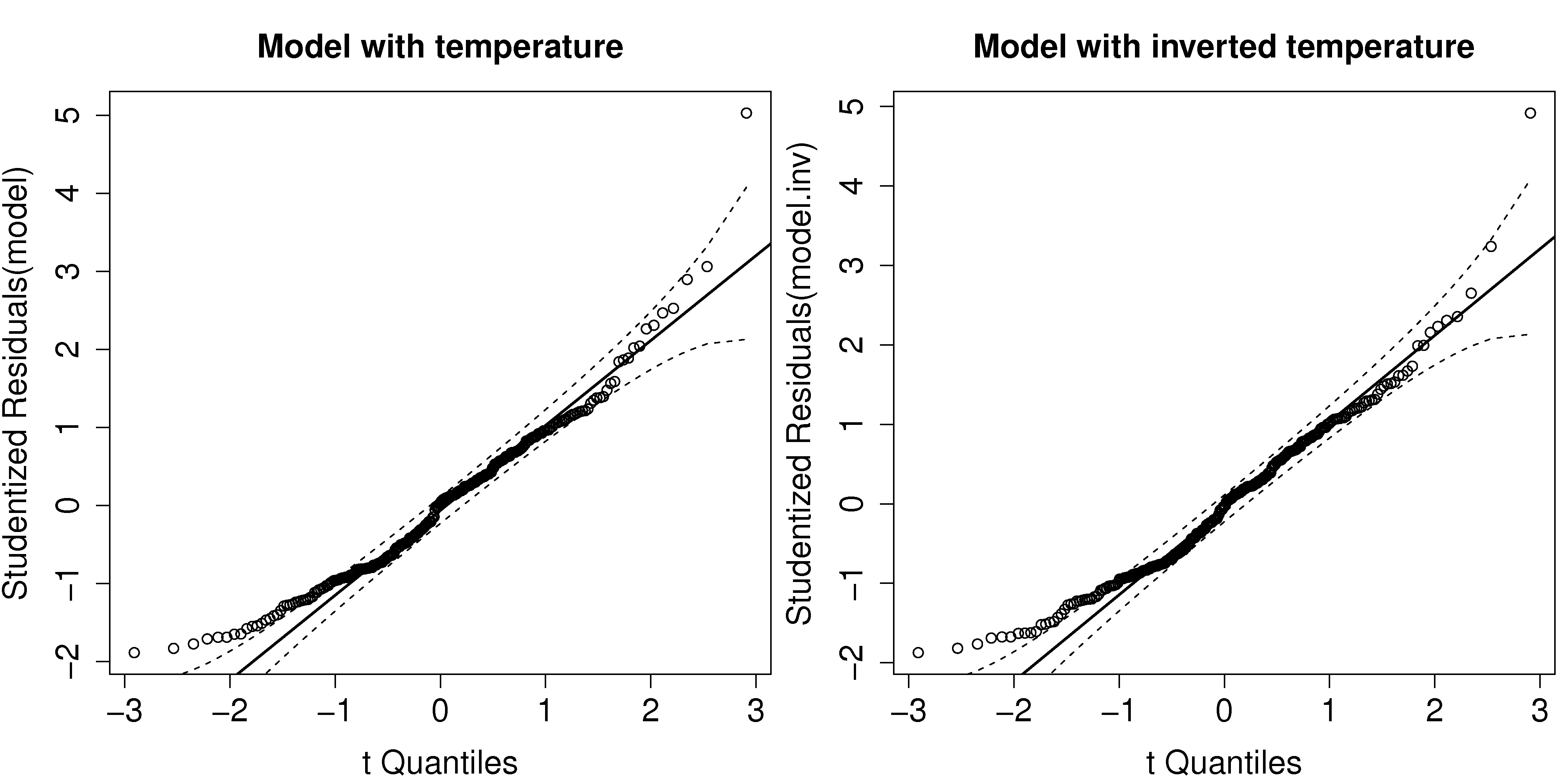
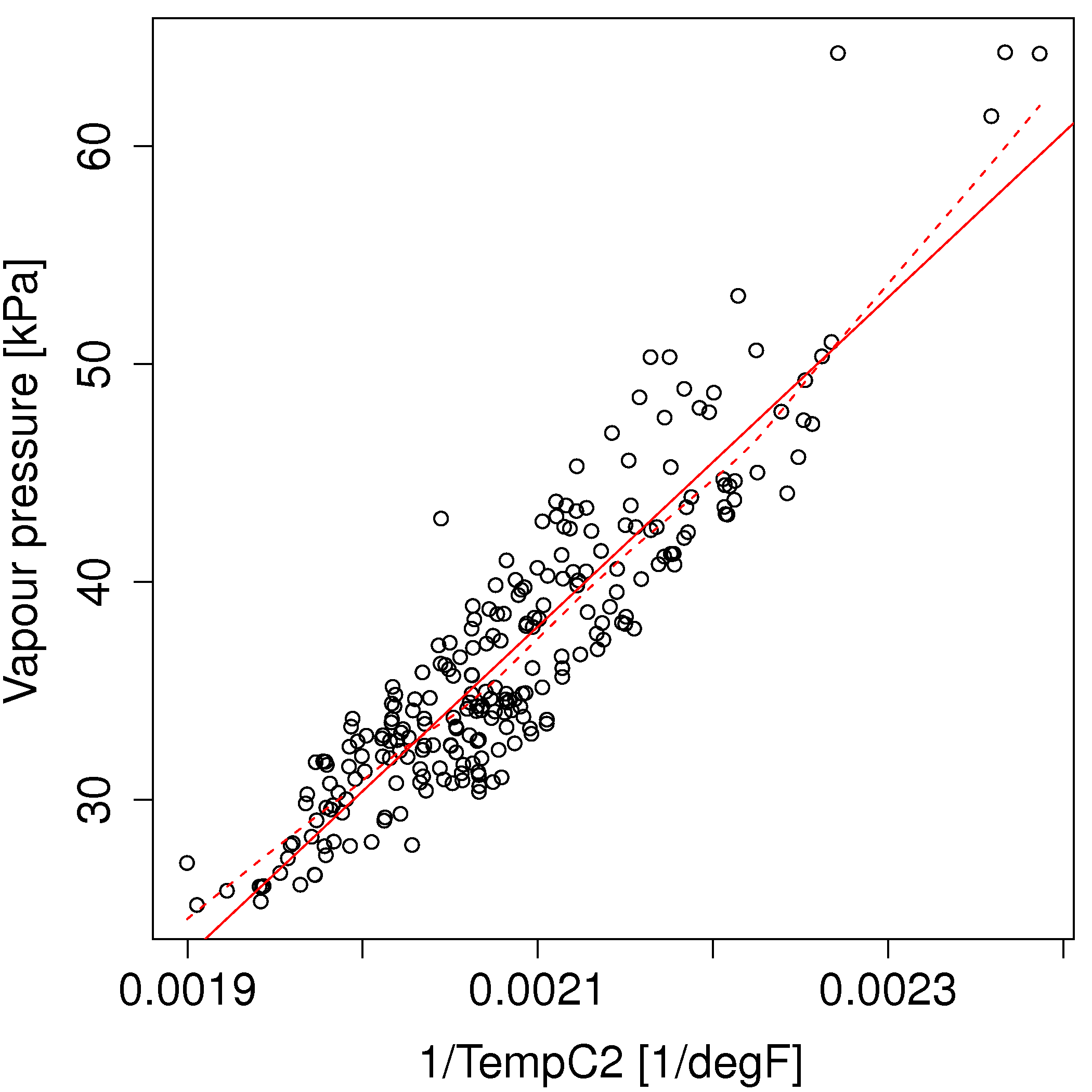
Refit the distillation model from the previous question with a transformed temperature variable. Use \(1/T\) instead of the actual temperature.
Solution Click to show answer
Does the model fit improve?
Are the residuals more normally distributed with the untransformed or transformed temperature variable?
How do you interpret the slope coefficient for the transformed temperature variable?
Use the model to compute the predicted vapour pressure at a temperature of 480 °F, and also calculate the corresponding prediction interval at that new temperature.
Question 4
Again, for the distillation model, use the data from 2000 and 2001 to build the model (the first column in the data set contains the dates). Then use the remaining data to test the model. Use \(\mathrm{x}\) = TempC2 and \(\mathrm{y}\) = VapourPressure in your model.
Short answer: Click to show answer
Calculate the RMSEP for the testing data. How does it compare to the standard error from the model?
Now use the
influencePlot(...)function from thecarlibrary, to highlight the influential observations in the model building data (2000 and 2001). Show your plot with observation labels (observation numbers are OK). See part 5 of the R tutorial for some help.Explain how the points you selected are influential on the model?
Remove these influential points, and refit the model on the training data. How has the model’s slope and standard error changed?
Recalculate the RMSEP for the testing data; how has it changed?
Question 5
The Kappa number data set was used in an earlier question to construct a Shewhart chart. The “Mistakes to avoid” section (Process Monitoring), warns that the subgroups for a Shewhart chart must be independent to satisfy the assumptions used to derived the Shewhart limits. If the subgroups are not independent, then it will increase the type I (false alarm) rate.
This is no different to the independence required for least squares models. Use the autocorrelation tool to determine a subgroup size for the Kappa variable that will satisfy the Shewhart chart assumptions. Show your autocorrelation plot and interpret it as well.
Question 6
You presume the yield from your lab-scale bioreactor, \(y\), is a function of reactor temperature, batch duration, impeller speed and reactor type (one with with baffles and one without). You have collected these data from various experiments.
Temp = \(T\) [°C] |
Duration = \(d\) [minutes] |
Speed = \(s\) [RPM] |
Baffles = \(b\) [Yes/No] |
Yield = \(y\) [g] |
|---|---|---|---|---|
82 |
260 |
4300 |
No |
51 |
90 |
260 |
3700 |
Yes |
30 |
88 |
260 |
4200 |
Yes |
40 |
86 |
260 |
3300 |
Yes |
28 |
80 |
260 |
4300 |
No |
49 |
78 |
260 |
4300 |
Yes |
49 |
82 |
260 |
3900 |
Yes |
44 |
83 |
260 |
4300 |
No |
59 |
64 |
260 |
4300 |
No |
60 |
73 |
260 |
4400 |
No |
59 |
60 |
260 |
4400 |
No |
57 |
60 |
260 |
4400 |
No |
62 |
101 |
260 |
4400 |
No |
42 |
92 |
260 |
4900 |
Yes |
38 |
Use software to fit a linear model that predicts the yield from these variables (the data set is available from the website). See the R tutorial for building linear models with integer variables in R.
Interpret the meaning of each effect in the model. If you are using R, then the
confint(...)function will be helpful as well. Show plots of each \(\mathrm{x}\) variable in the model against yield. Use a box plot for the baffles indicator variable.Now calculate the \(\mathbf{X}^T\mathbf{X}\) and \(\mathbf{X}^T\mathbf{y}\) matrices; include a column in the \(\mathbf{X}\) matrix for the intercept. Since you haven’t mean centered the data to create these matrices, it would be misleading to try interpret them.
Calculate the least squares model estimates from these two matrices. See the R tutorial for doing matrix operations in R, but you might prefer to use MATLAB for this step. Either way, you should get the same answer here as in the first part of this question.
Question 7
In the section on comparing differences between two groups we used, without proof, the fact that:
Prove this statement, and clearly explain all steps in your proof.
Question 8
The production of low density polyethylene is carried out in long, thin pipes at high temperature and pressure (1.5 kilometres long, 50mm in diameter, 500 K, 2500 atmospheres). One quality measurement of the LDPE is its melt index. Laboratory measurements of the melt index can take between 2 to 4 hours. Being able to predict this melt index, in real time, allows for faster adjustment to process upsets, reducing the product’s variability. There are many variables that are predictive of the melt index, but in this example we only use a temperature measurement that is measured along the reactor’s length.
These are the data of temperature (K) and melt index (units of melt index are “grams per 10 minutes”).
Temperature = \(T\) [Kelvin] |
441 |
453 |
461 |
470 |
478 |
481 |
483 |
485 |
499 |
500 |
506 |
516 |
Melt index = \(m\) [g per 10 mins] |
9.3 |
6.6 |
6.6 |
7.0 |
6.1 |
3.5 |
2.2 |
3.6 |
2.9 |
3.6 |
4.2 |
3.5 |
The following calculations have already been performed:
Number of samples, \(n = 12\)
Average temperature = \(\overline{T} = 481\) K
Average melt index, \(\overline{m} = 4.925\) g per 10 minutes.
The summed product, \(\sum_i{\left(T_i-\overline{T}\right)\left(m_i - \overline{m}\right)} = -422.1\)
The sum of squares, \(\sum_i{\left(T_i-\overline{T}\right)^2} = 5469.0\)
Use this information to build a predictive linear model for melt index from the reactor temperature.
What is the model’s standard error and how do you interpret it in the context of this model? You might find the following software software output helpful, but it is not required to answer the question.
Call: lm(formula = Melt.Index ~ Temperature) Residuals: Min 1Q Median 3Q Max -2.5771 -0.7372 0.1300 1.2035 1.2811 Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) -------- 8.60936 4.885 0.000637 Temperature -------- 0.01788 -4.317 0.001519 Residual standard error: 1.322 on 10 degrees of freedom Multiple R-squared: 0.6508, Adjusted R-squared: 0.6159 F-statistic: 18.64 on 1 and 10 DF, p-value: 0.001519Quote a confidence interval for the slope coefficient in the model and describe what it means. Again, you may use the above software output to help answer your question.
Question 9
For a distillation column, it is well known that the column temperature directly influences the purity of the product, and this is used in fact for feedback control, to achieve the desired product purity. Use the distillation data set , and build a least squares model that predicts VapourPressure from the temperature measurement, TempC2. Report the following values:
the slope coefficient, and describe what it means in terms of your objective to control the process with a feedback loop
the interquartile range and median of the model’s residuals
the model’s standard error
a confidence interval for the slope coefficient, and its interpretation.
You may use any computer package to build the model and read these values off the computer output.
Question 10
Use the bioreactor data, which shows the percentage yield from the reactor when running various experiments where temperature was varied, impeller speed and the presence/absence of baffles were adjusted.
Build a linear model that uses the reactor temperature to predict the yield. Interpret the slope and intercept term.
Build a linear model that uses the impeller speed to predict yield. Interpret the slope and intercept term.
Build a linear model that uses the presence (represent it as 1) or absence (represent it as 0) of baffles to predict yield. Interpret the slope and intercept term.
Note: if you use R it will automatically convert the
bafflesvariable to 1’s and 0’s for you. If you wanted to make the conversion yourself, to verify what R does behind the scenes, try this:# Read in the data frame bio <- read.csv('http://openmv.net/file/bioreactor-yields.csv') # Force the baffles variables to 0's and 1's bio$baffles <- as.numeric(bio$baffles) - 1
Which variable(s) would you change to boost the batch yield, at the lowest cost of implementation?
Use the
plot(bio)function in R, wherebiois the data frame you loaded using theread.csv(...)function. R notices thatbiois not a single variable, but a group of variables, i.e. a data frame, so it plots what is called a scatterplot matrix instead. Describe how the scatterplot matrix agrees with your interpretation of the slopes in parts 1, 2 and 3 of this question.
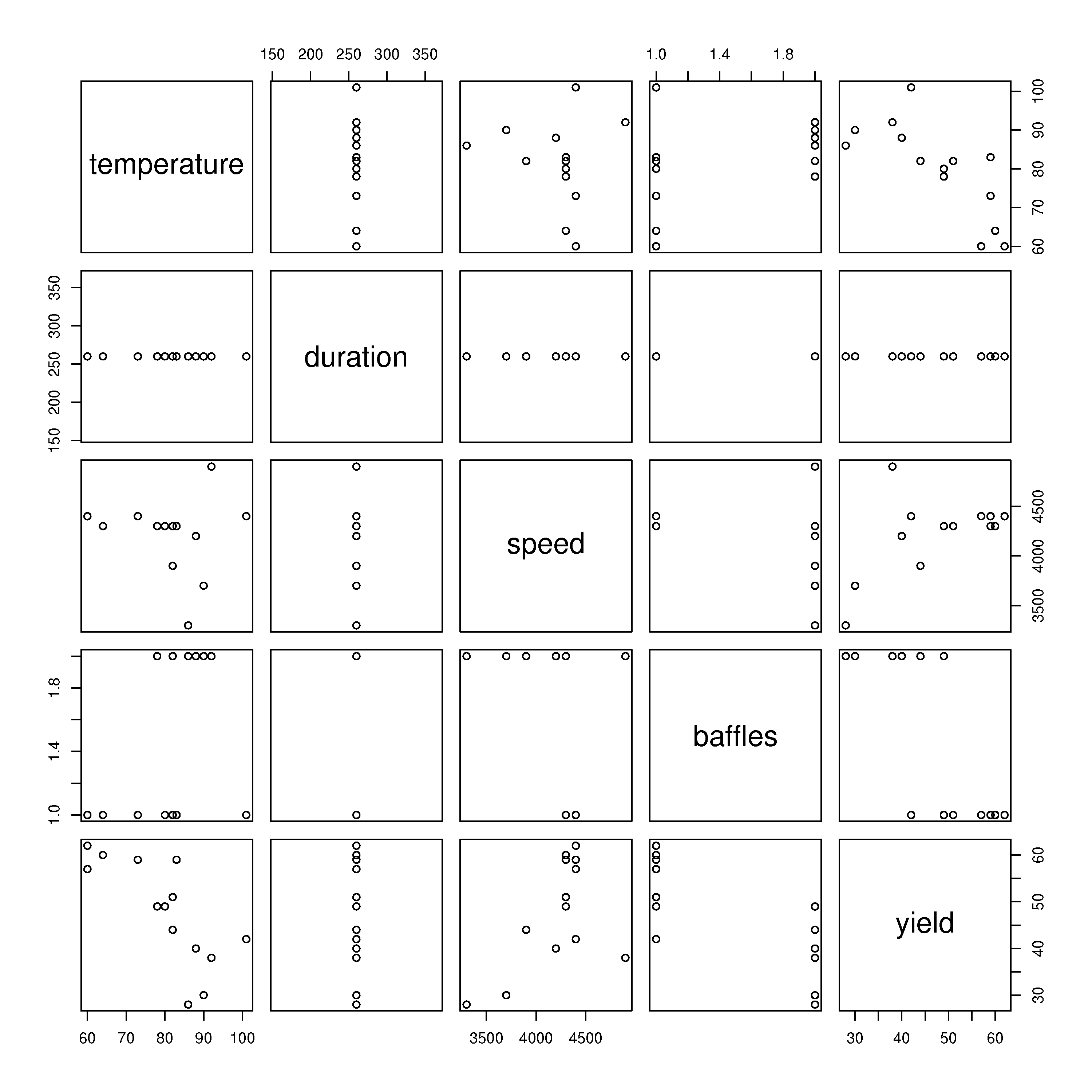
Question 11
Use the gas furnace data from the website to answer these questions. The data represent the gas flow rate (centered) from a process and the corresponding CO2 measurement.
Make a scatter plot of the data to visualize the relationship between the variables. How would you characterize the relationship?
Calculate the variance for both variables, the covariance between the two variables, and the correlation between them, \(r(x,y)\). Interpret the correlation value; i.e. do you consider this a strong correlation?
Now calculate a least squares model relating the gas flow rate as the \(x\) variable to the CO2 measurement as the \(y\)-variable. Report the intercept and slope from this model.
Report the \(R^2\) from the regression model. Compare the squared value of \(r(x,y)\) to \(R^2\). What do you notice? Now reinterpret what the correlation value means (i.e. compare this interpretation to your answer in part 2).
Advanced: Switch \(x\) and \(y\) around and rebuild your least squares model. Compare the new \(R^2\) to the previous model’s \(R^2\). Is this result surprising? How do interpret this?
Question 12
A new type of thermocouple is being investigated by your company’s process control group. These devices produce an almost linear voltage (millivolt) response at different temperatures. In practice though it is used the other way around: use the millivolt reading to predict the temperature. The process of fitting this linear model is called calibration.
Use the following data to calibrate a linear model:
Temperature [K]
273
293
313
333
353
373
393
413
433
453
Reading [mV]
0.01
0.12
0.24
0.38
0.51
0.67
0.84
1.01
1.15
1.31
Show the linear model and provide the predicted temperature when reading 1.00 mV.
Are you satisfied with this model, based on the coefficient of determination (\(R^2\)) value?
What is the model’s standard error? Now, are you satisfied with the model’s prediction ability, given that temperatures can usually be recorded to an accuracy of \(\pm 0.5\) K with most inexpensive thermocouples.
What is your (revised) conclusion now about the usefulness of the \(R^2\) value?
Note: This example explains why we don’t use the terminology of independent and dependent variables in this book. Here the temperature truly is the independent variable, because it causes the voltage difference that we measure. But the voltage reading is the independent variable in the least squares model. The word independent is being used in two different senses (its English meaning vs its mathematical meaning), and this can be misleading.
Question 13
Use the linear model you derived in the gas furnace question, where you used the gas flow rate to predict the CO2 measurement, and construct the analysis of variance table (ANOVA) for the dataset. Use your ANOVA table to reproduce the residual standard error, \(S_E\) value, that you get from the R software output.
Go through the R tutorial to learn how to efficiently obtain the residuals and predicted values from a linear model object.
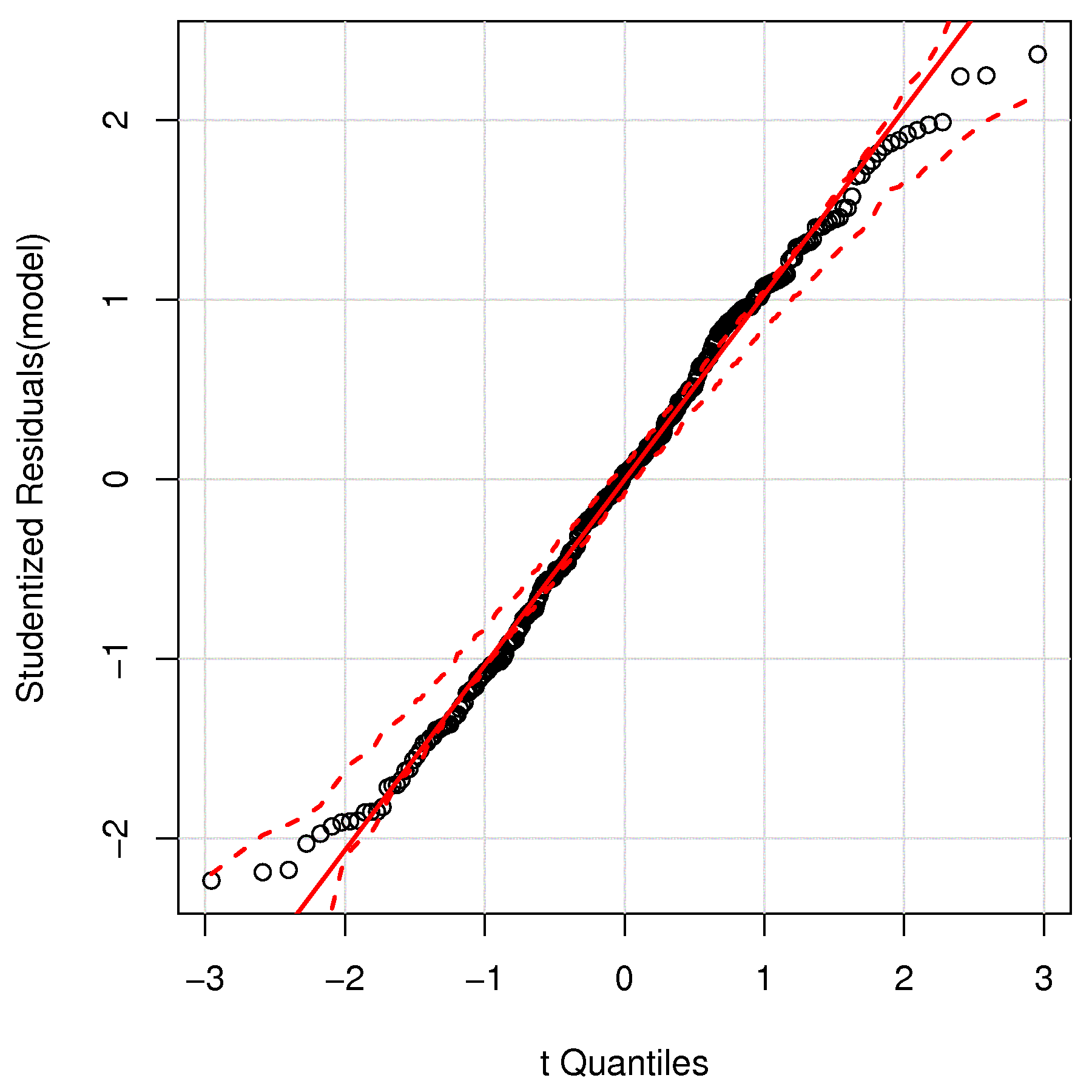
Also for the above linear model, verify whether the residuals are normally distributed.
Use the linear model you derived in the thermocouple question, where you used the voltage measurement to predict the temperature, and construct the analysis of variance table (ANOVA) for that dataset. Use your ANOVA table to reproduce the residual standard error, \(S_E\) value, that you get from the R software output.
Question 14
Use the mature cheddar cheese data set for this question.
Choose any \(x\)-variable, either
Aceticacid concentration (already log-transformed),H2Sconcentration (already log-transformed), orLacticacid concentration (in original units) and use this to predict theTastevariable in the data set. TheTasteis a subjective measurement, presumably measured by a panel of tasters.Prove that you get the same linear model coefficients, \(R^2\), \(S_E\) and confidence intervals whether or not you first mean center the \(x\) and \(y\) variables.
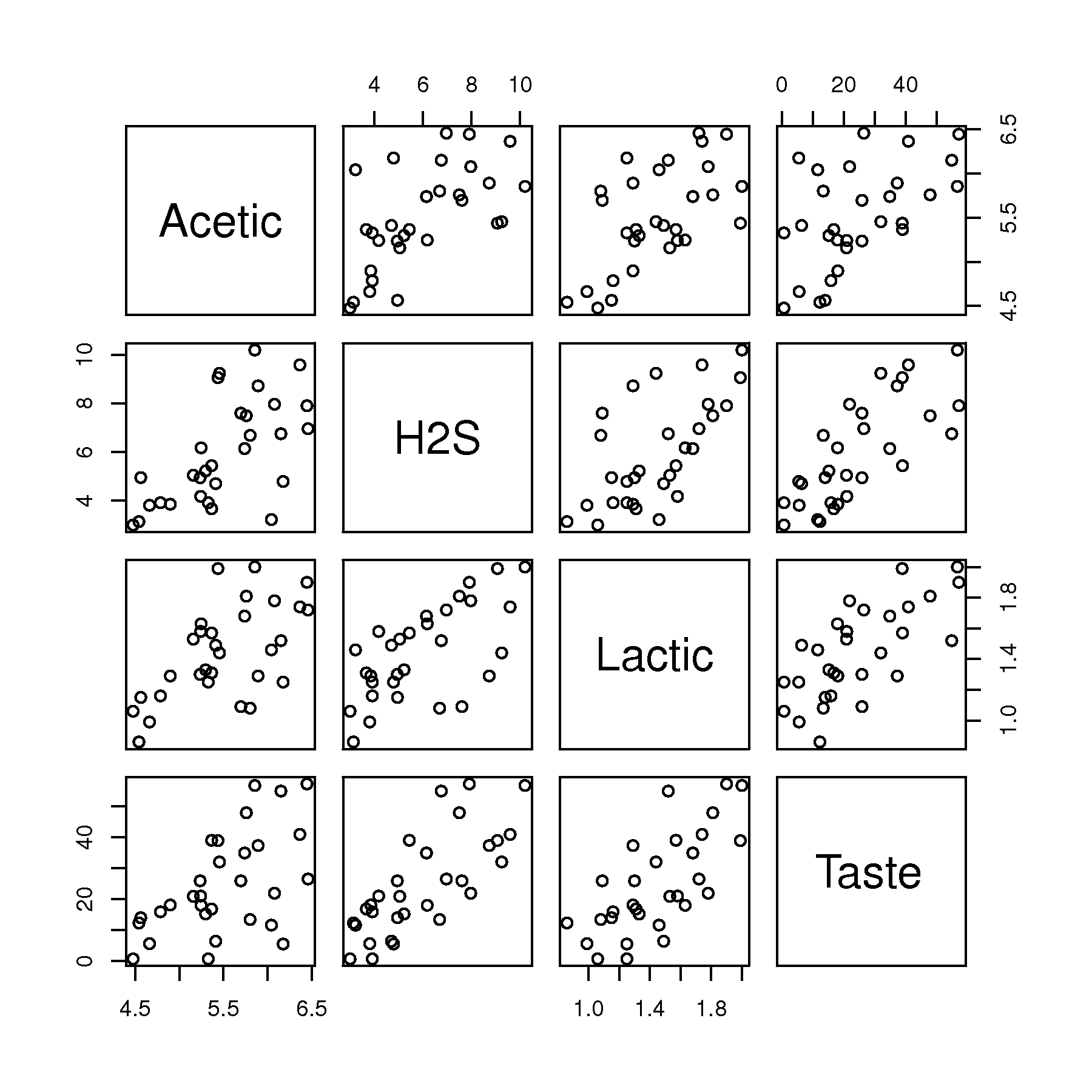
What is the level of correlation between each of the \(x\)-variables. Also show a scatterplot matrix to learn what this level of correlation looks like visually.
Report your correlations as a \(3 \times 3\) matrix, where there should be 1.0’s on the diagonal, and values between \(-1\) and \(+1\) on the off-diagonals.
Build a linear regression that uses all three \(x\)-variables to predict \(y\).
Report the slope coefficient and confidence interval for each \(x\)-variable
Report the model’s standard error. Has it decreased from the model in part 1?
Report the model’s \(R^2\) value. Has it decreased?
Question 15
In this question we will revisit the bioreactor yield data set and fit a linear model with all \(x\)-variables to predict the yield. (This data was also used in a previous question.)
Provide the interpretation for each coefficient in the model, and also comment on each one’s confidence interval when interpreting it.
Compare the 3 slope coefficient values you just calculated, to those from the previous question:
\(\hat{y} = 102.5 - 0.69T\), where \(T\) is tank temperature
\(\hat{y} = -20.3 + 0.016S\), where \(S\) is impeller speed
\(\hat{y} = 54.9 - 16.7B\), where \(B\) is 1 if baffles are present and \(B=0\) with no baffles
Explain why your coefficients do not match.
Are the residuals from the multiple linear regression model normally distributed?
In this part we are investigating the variance-covariance matrices used to calculate the linear model.
First center the \(x\)-variables and the \(y\)-variable that you used in the model.
Note: feel free to use MATLAB, or any other tool to answer this question. If you are using R, then you will benefit from this page in the R tutorial. Also, read the help for the
model.matrix(...)function to get the \(\mathbf{X}\)-matrix. Then read the help for thesweep(...)function, or more simply use thescale(...)function to do the mean-centering.Show your calculated \(\mathbf{X}^T\mathbf{X}\) and \(\mathbf{X}^T\mathbf{y}\) variance-covariance matrices from the centered data.
Explain why the interpretation of covariances in \(\mathbf{X}^T\mathbf{y}\) match the results from the full MLR model you calculated in part 1 of this question.
Calculate \(\mathbf{b} =\left(\mathbf{X}^T\mathbf{X}\right)^{-1}\mathbf{X}^T\mathbf{y}\) and show that it agrees with the estimates that R calculated (even though R fits an intercept term, while your \(\mathbf{b}\) does not).
What would be the predicted yield for an experiment run without baffles, at 4000 rpm impeller speed, run at a reactor temperature of 90 °C?
Question 16
In this question we will use the LDPE data which is data from a high-fidelity simulation of a low-density polyethylene reactor. LDPE reactors are very long, thin tubes. In this particular case the tube is divided in 2 zones, since the feed enters at the start of the tube, and some point further down the tube (start of the second zone). There is a temperature profile along the tube, with a certain maximum temperature somewhere along the length. The maximum temperature in zone 1, Tmax1 is reached some fraction z1 along the length; similarly in zone 2 with the Tmax2 and z2 variables.
We will build a linear model to predict the SCB variable, the short chain branching (per 1000 carbon atoms) which is an important quality variable for this product. Note that the last 4 rows of data are known to be from abnormal process operation, when the process started to experience a problem. However, we will pretend we didn’t know that when building the model, so keep them in for now.
Use only the following subset of \(x\)-variables:
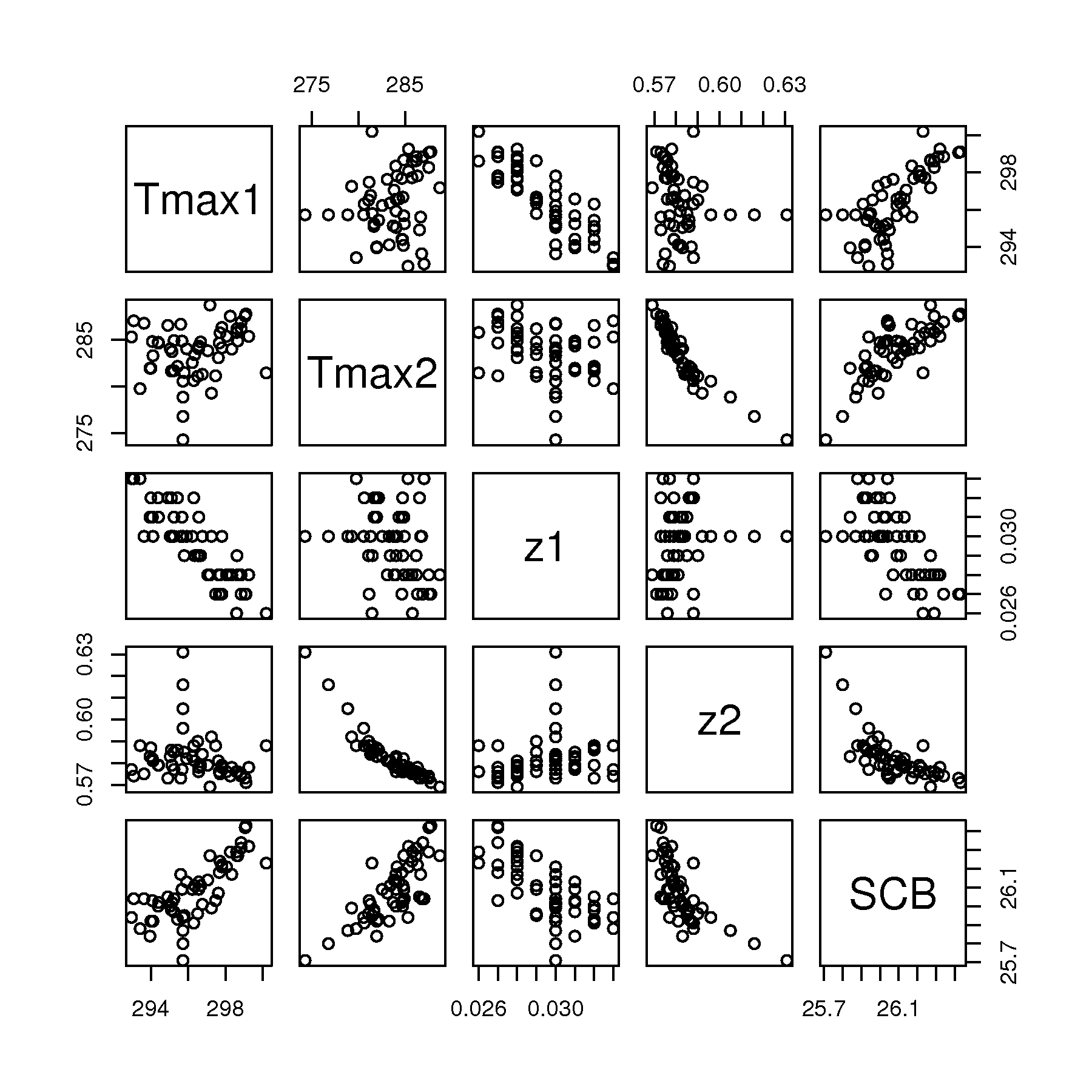
Tmax1,Tmax2,z1andz2and the \(y\) variable =SCB. Show the relationship between these 5 variables in a scatter plot matrix.Use this code to get you started (make sure you understand what it is doing):
LDPE <- read.csv('http://openmv.net/file/ldpe.csv') subdata <- data.frame(cbind(LDPE$Tmax1, LDPE$Tmax2, LDPE$z1, LDPE$z2, LDPE$SCB)) colnames(subdata) <- c("Tmax1", "Tmax2", "z1", "z2", "SCB")Using bullet points, describe the nature of relationships between the 5 variables, and particularly the relationship to the \(y\)-variable.
Let’s start with a linear model between
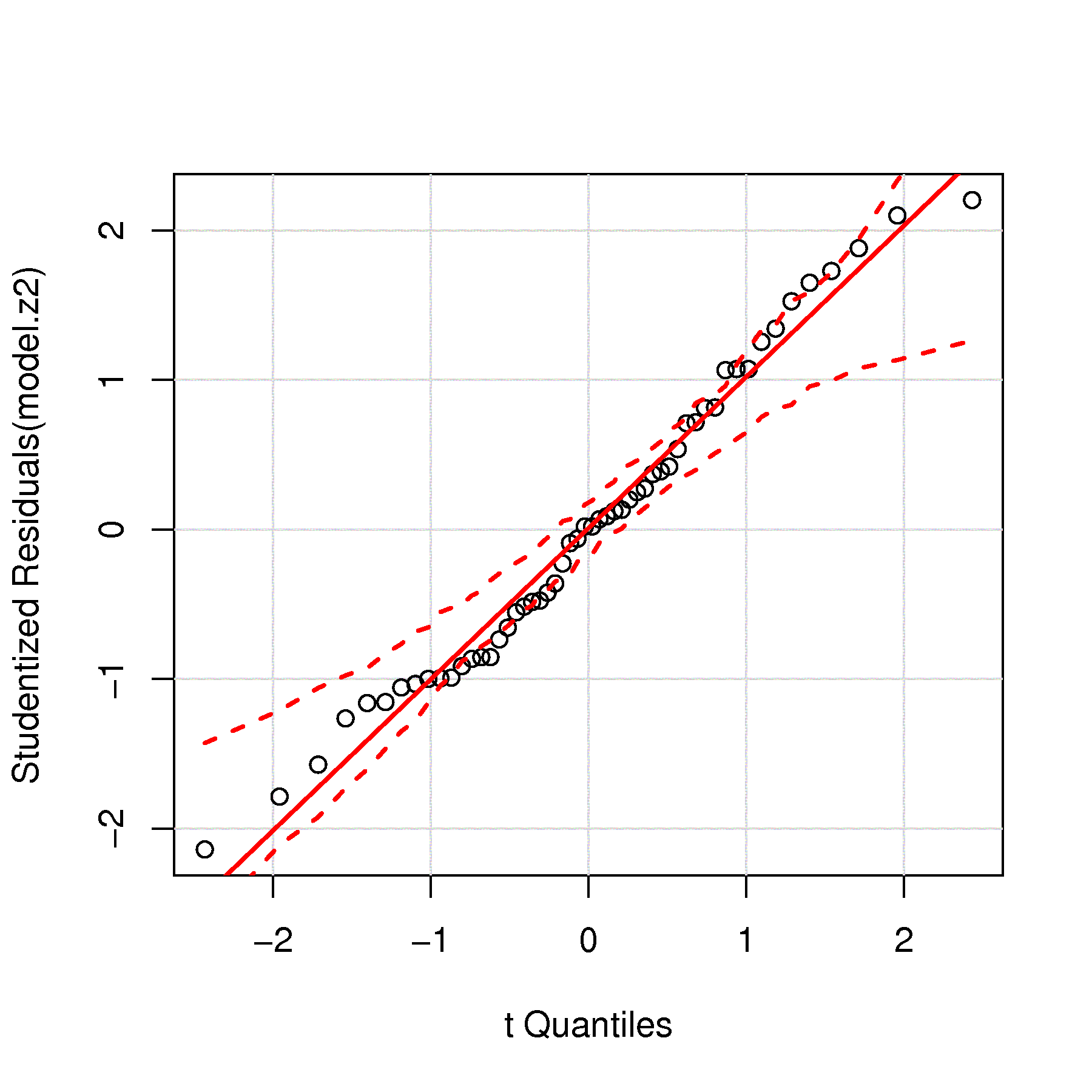
z2andSCB. We will call this thez2model. Let’s examine its residuals:Are the residuals normally distributed?
What is the standard error of this model?
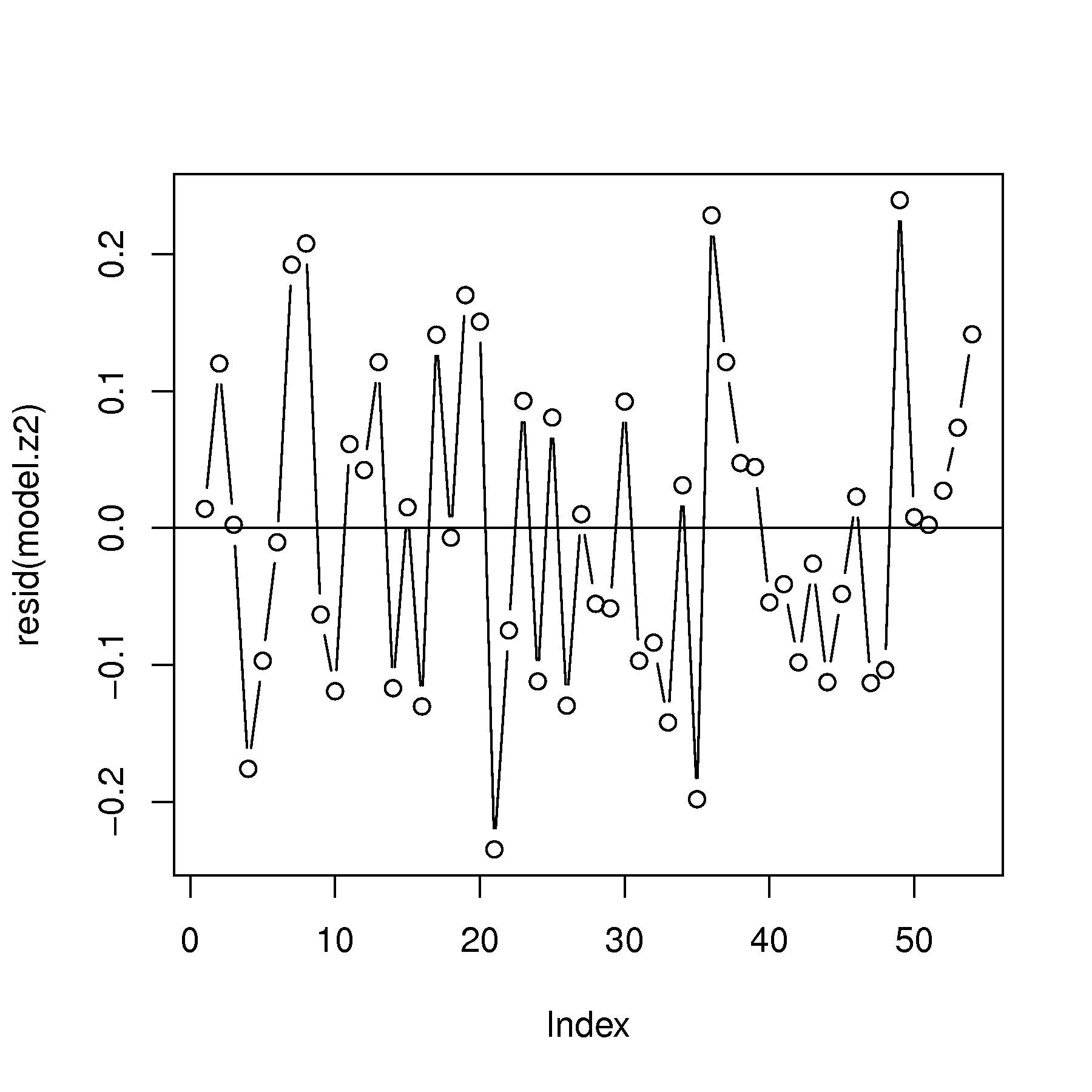
Are there any time-based trends in the residuals (the rows in the data are already in time-order)?
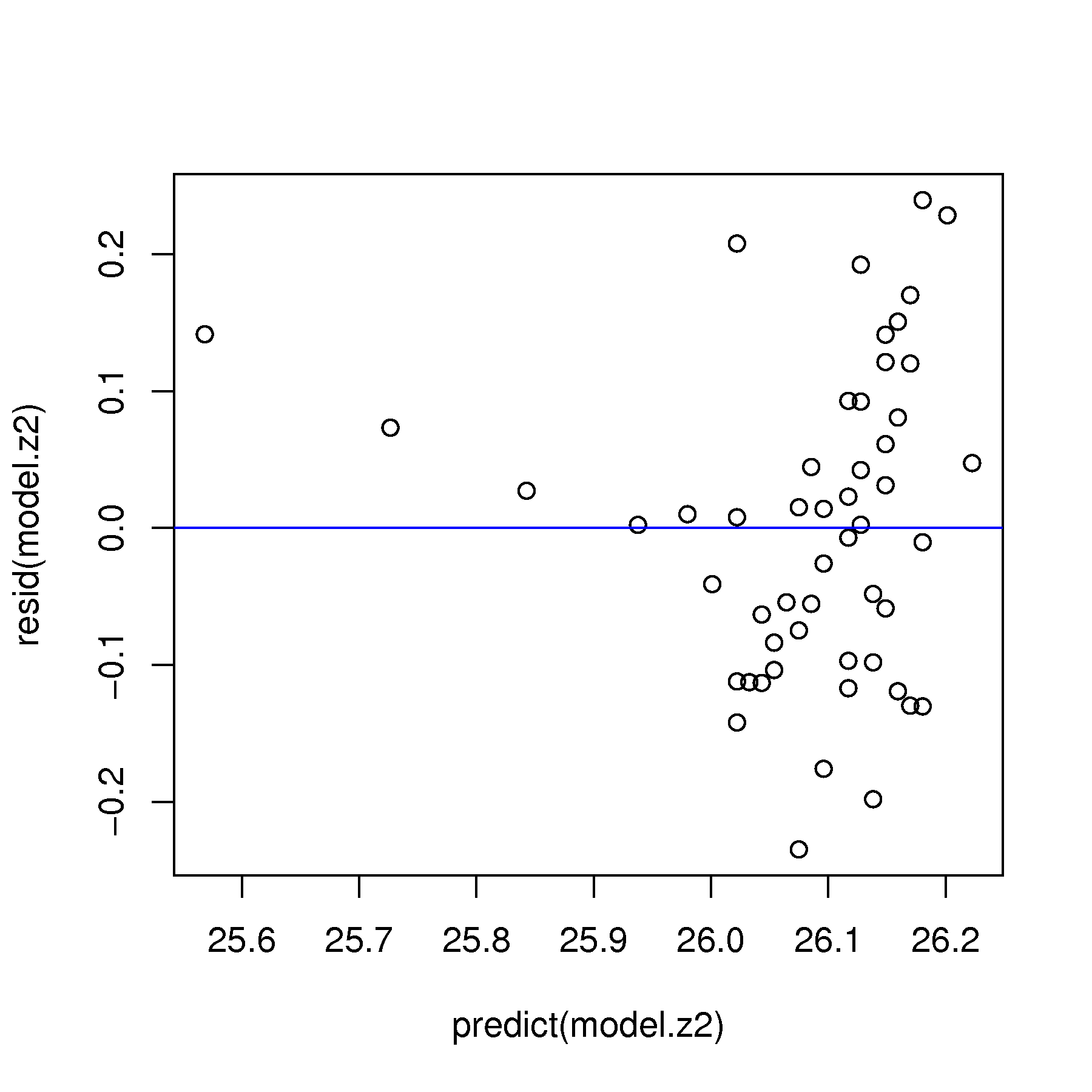
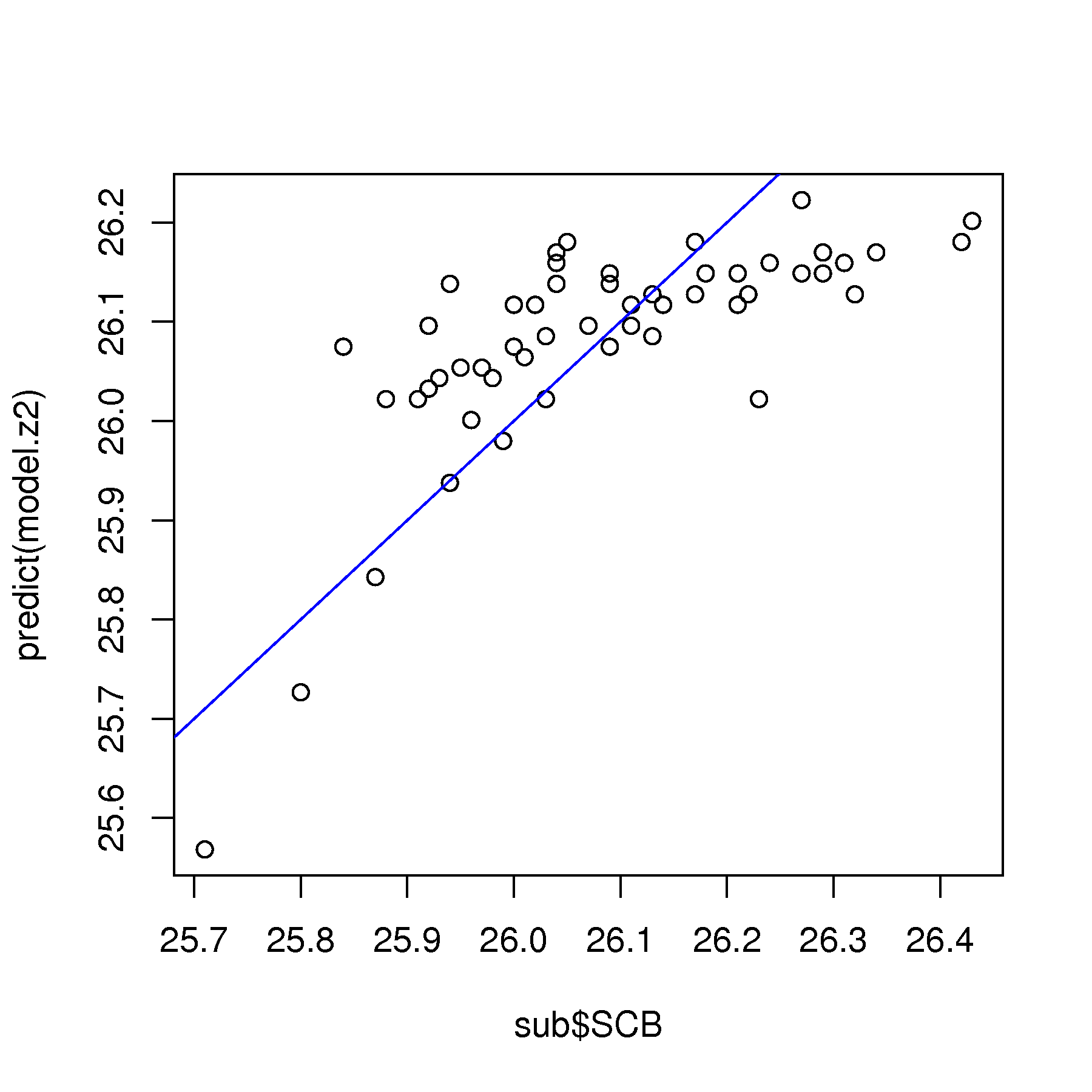
Use any other relevant plots of the predicted values, the residuals, the \(x\)-variable, as described in class, and diagnose the problem with this linear model.
What can be done to fix the problem? (You don’t need to implement the fix yet).
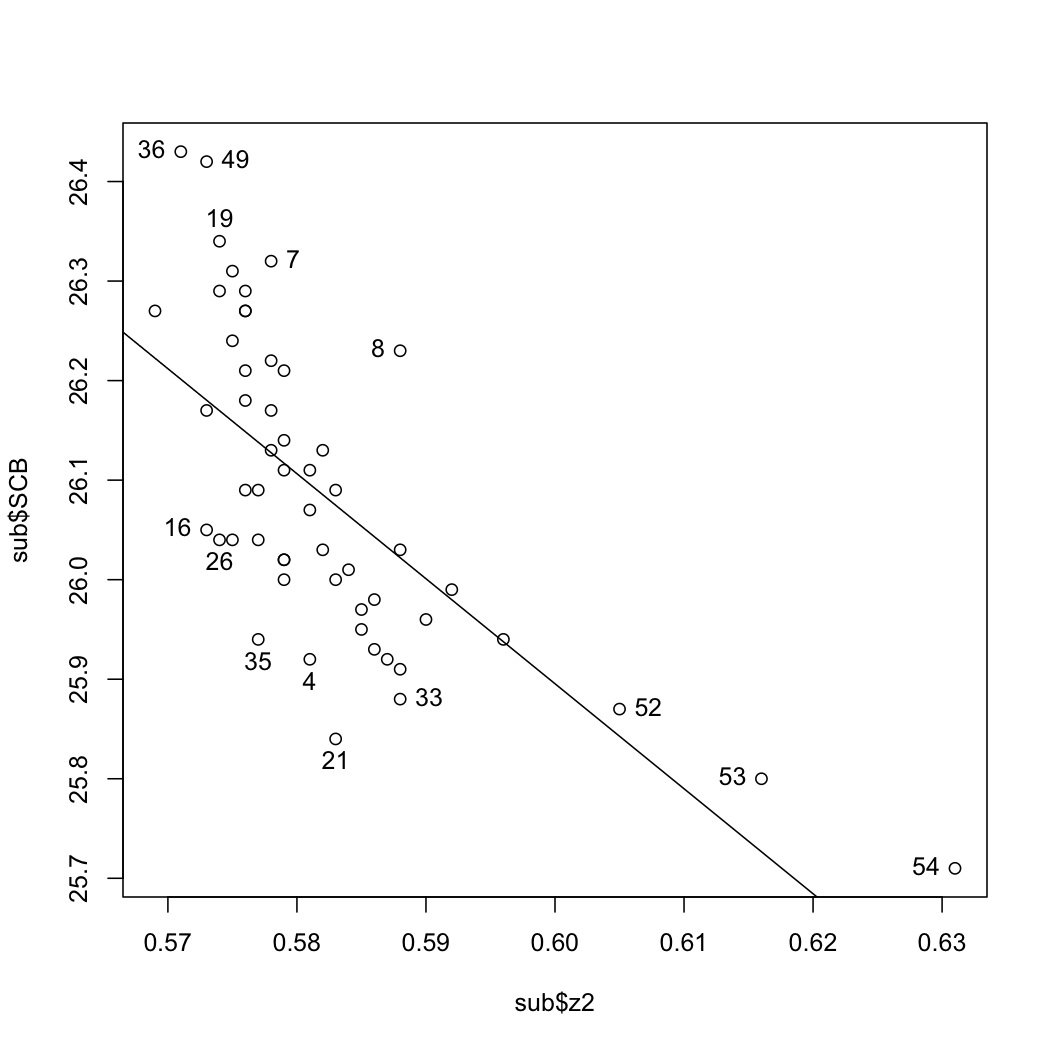
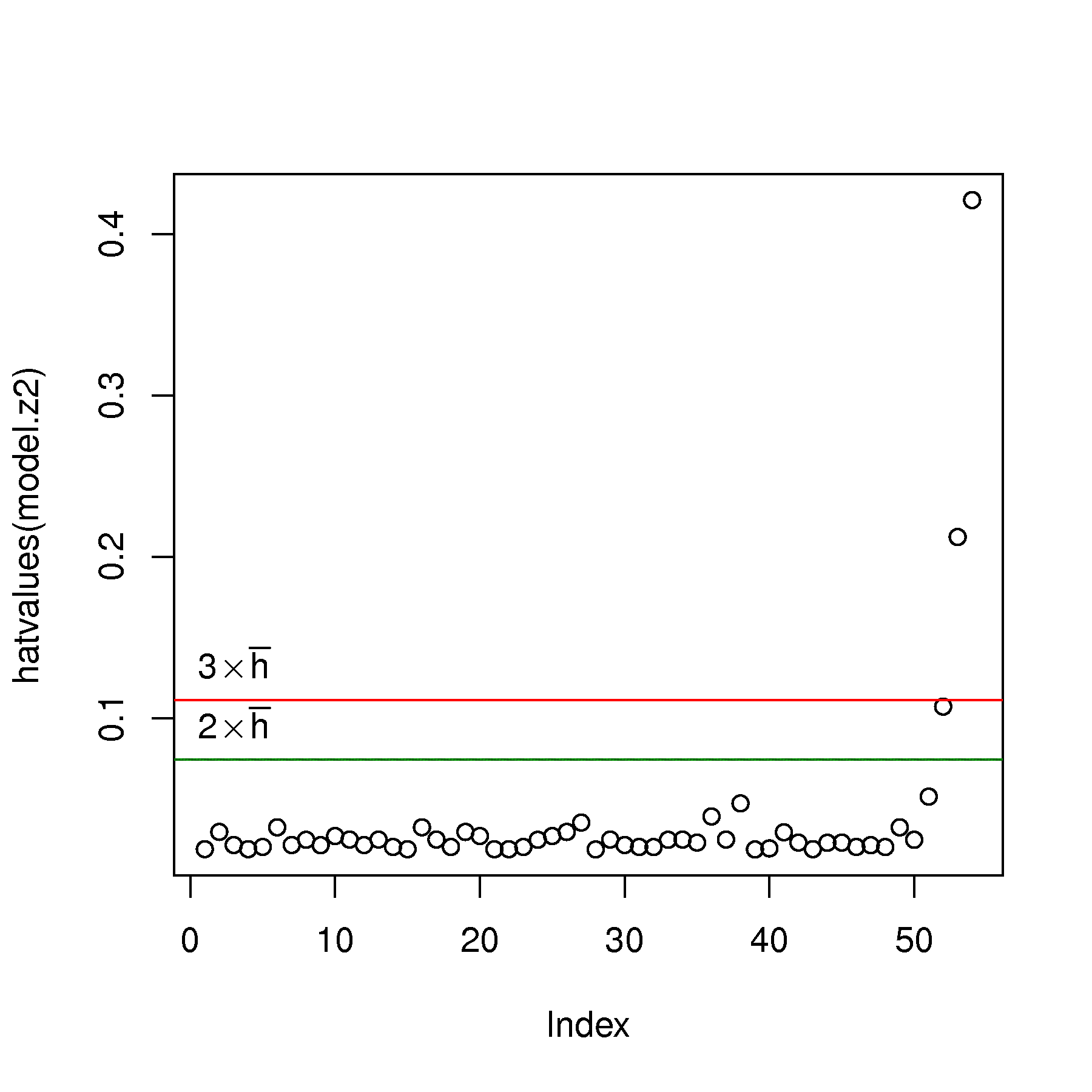
Show a plot of the hat-values (leverage) from the
z2model.Add suitable horizontal cut-off lines to your hat-value plot.
Identify on your plot the observations that have large leverage on the model
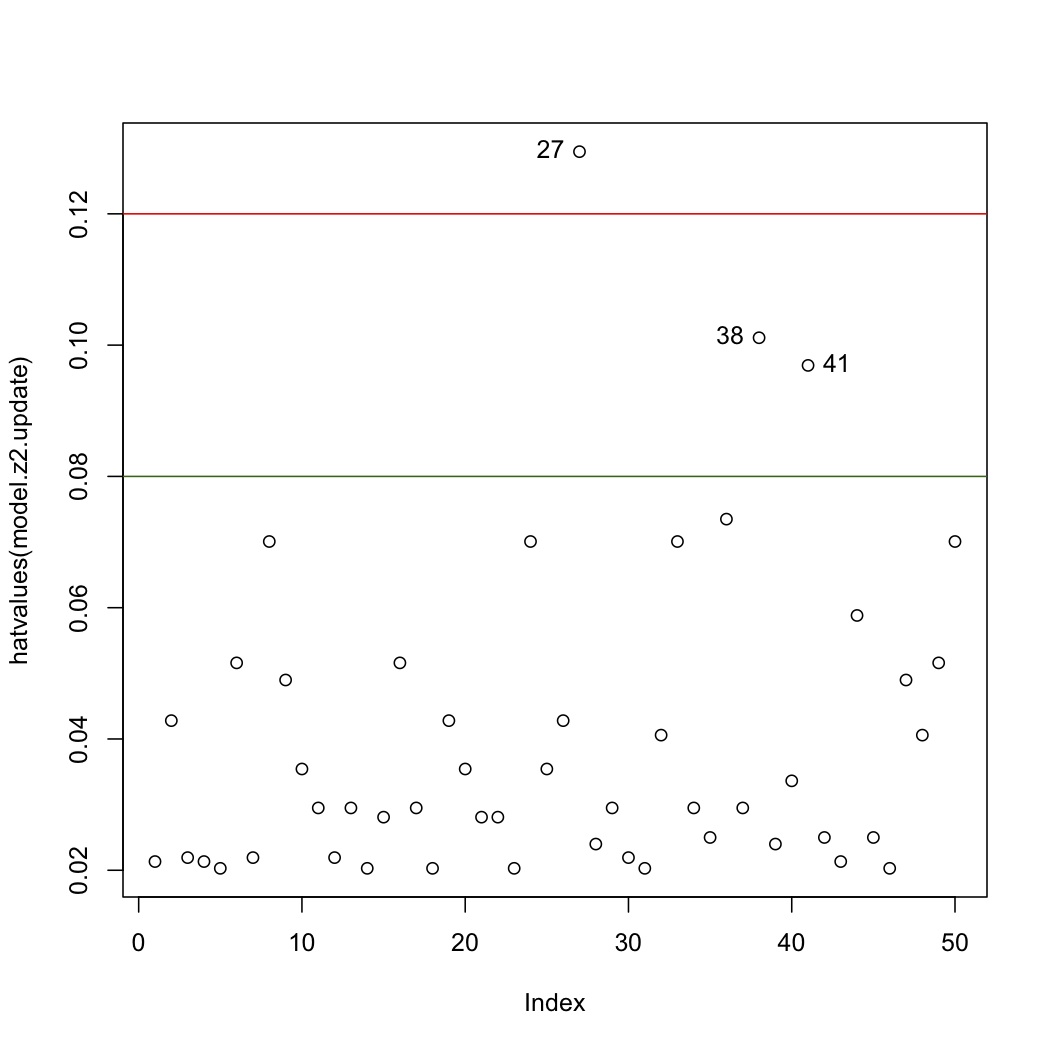
Remove the high-leverage outliers and refit the model. Call this the
z2.updatedmodelShow the updated hat-values and verify whether the problem has mostly gone away
Note: see the R tutorial on how to rebuild a model by removing points
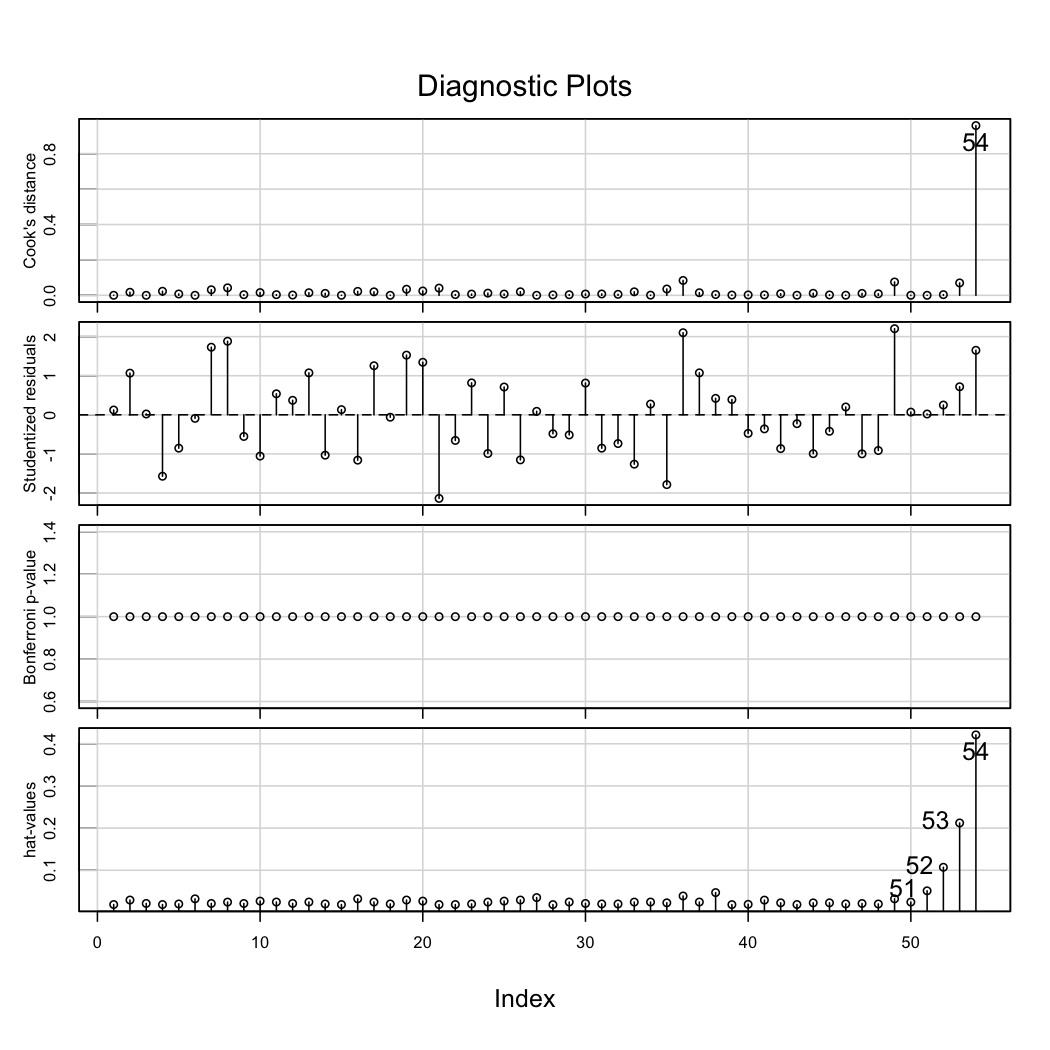
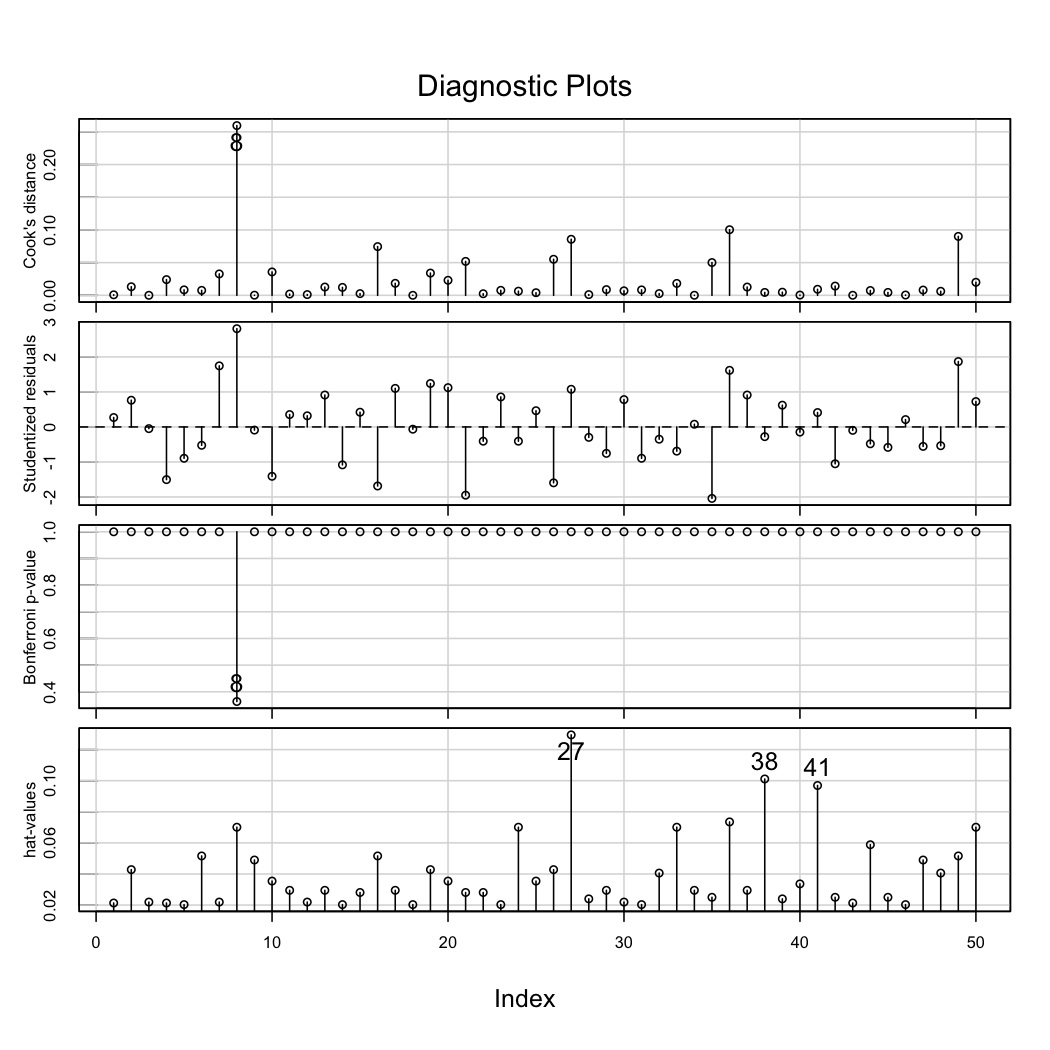
Use the
influenceIndexPlot(...)function in thecarlibrary on both thez2model and thez2.updatedmodel. Interpret what each plot is showing for the two models. You may ignore the Bonferroni p-values subplot.
Question 17
A concrete slump test is used to test for the fluidity, or workability, of concrete. It’s a crude, but quick test often used to measure the effect of polymer additives that are mixed with the concrete to improve workability.
The concrete mixture is prepared with a polymer additive. The mixture is placed in a mold and filled to the top. The mold is inverted and removed. The height of the mold minus the height of the remaining concrete pile is called the “slump”.
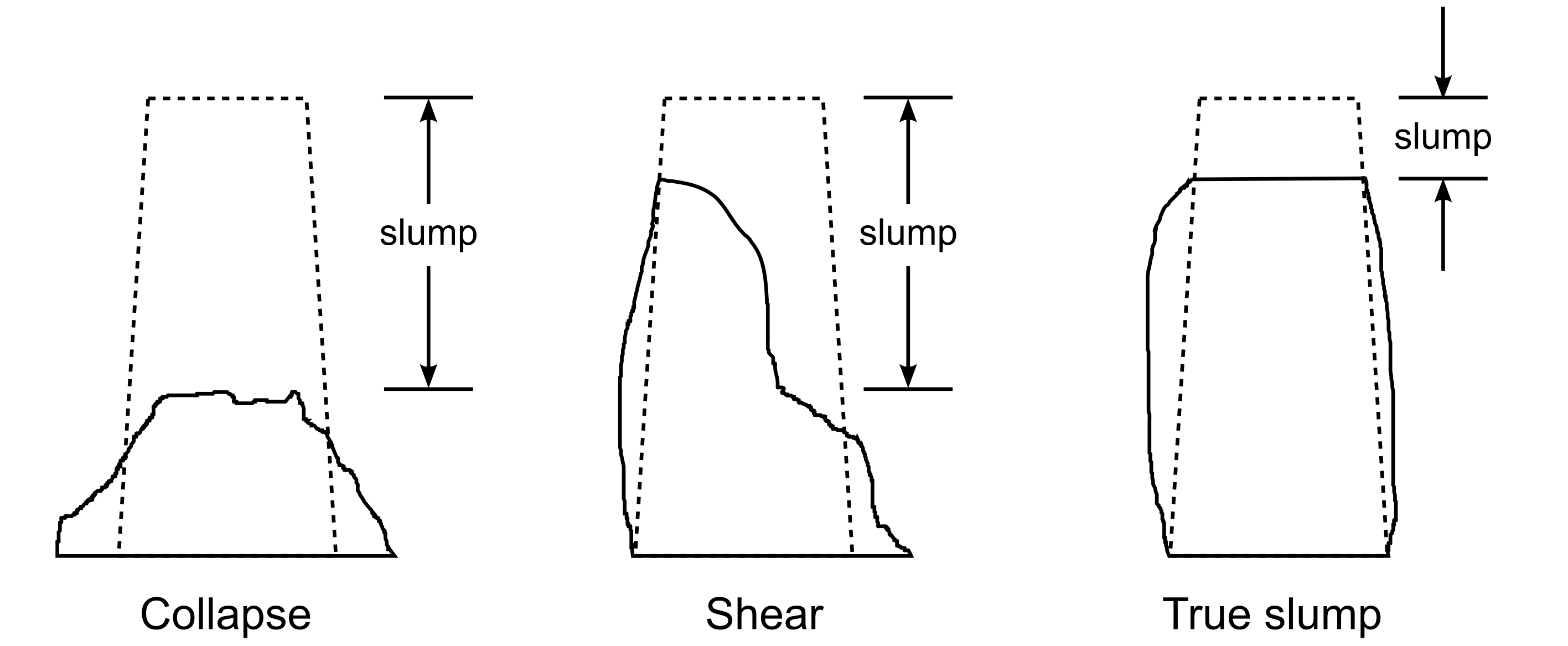
Figure from Wikipedia
{kind=link}
Your company provides the polymer additive, and you are developing an improved polymer formulation, call it B, that hopefully provides the same slump values as your existing polymer, call it A. Formulation B costs less money than A, but you don’t want to upset, or lose, customers by varying the slump value too much.
The following slump values were recorded over the course of the day:
Additive
Slump value [cm]
A
5.2
A
3.3
B
5.8
A
4.6
B
6.3
A
5.8
A
4.1
B
6.0
B
5.5
B
4.5
You can derive the 95% confidence interval for the true, but unknown, difference between the effect of the two additives:
\[\begin{split}\begin{array}{rcccl} -c_t &\leq& z &\leq & +c_t \\ (\overline{x}_B - \overline{x}_A) - c_t \sqrt{s_P^2 \left(\frac{1}{n_B} + \frac{1}{n_A}\right)} &\leq& \mu_B - \mu_A &\leq & (\overline{x}_B - \overline{x}_A) + c_t \sqrt{s_P^2 \left(\frac{1}{n_B} + \frac{1}{n_A}\right)}\\ 1.02 - 2.3 \sqrt{0.709 \left(\frac{1}{5} + \frac{1}{5}\right)} &\leq& \mu_B - \mu_A &\leq& 1.02 + 2.3 \sqrt{0.709 \left(\frac{1}{5} + \frac{1}{5}\right)} \\ -0.21 &\leq& \mu_B - \mu_A &\leq& 2.2 \end{array}\end{split}\]
Fit a least squares model to the data using an integer variable, \(x_A = 0\) for additive A, and \(x_A = 1\) for additive B. The model should include an intercept term also: \(y = b_0 + b_A x_A\). Hint: use R to build the model, and search the R tutorial with the term categorical variable or integer variable for assistance.
Show that the 95% confidence interval for \(b_A\) gives exactly the same lower and upper bounds, as derived above with the traditional approach for tests of differences.
Solution Click to show answerQuestion 18
Some data were collected from tests where the compressive strength, \(x\), used to form concrete was measured, as well as the intrinsic permeability of the product, \(y\). There were 16 data points collected. The mean \(x\)-value was \(\overline{x} = 3.1\) and the variance of the \(x\)-values was 1.52. The average \(y\)-value was 40.9. The estimated covariance between \(x\) and \(y\) was \(-5.5\).
The least squares estimate of the slope and intercept was: \(y = 52.1 - 3.6 x\).
What is the expected permeability when the compressive strength is at 5.8 units?
Calculate the 95% confidence interval for the slope if the standard error from the model was 4.5 units. Is the slope coefficient statistically significant?
Provide a rough estimate of the 95% prediction interval when the compressive strength is at 5.8 units (same level as for part 1). What assumptions did you make to provide this estimate?
Now provide a more accurate, calculated 95% prediction confidence interval for the previous part.
Question 19
A simple linear model relating reactor temperature to polymer viscosity is desirable, because measuring viscosity online, in real time is far too costly, and inaccurate. Temperature, on the other hand, is quick and inexpensive. This is the concept of soft sensors, also known as inferential sensors.
Data were collected from a rented online viscosity unit and a least squares model build:
where the viscosity, \(v\), is measured in Pa.s (Pascal seconds) and the temperature is in Kelvin. A reasonably linear trend was observed over the 86 data points collected. Temperature values were taken over the range of normal operation: 430 to 480 K and the raw temperature data had a sample standard deviation of 8.2 K.
The output from a certain commercial software package was:
Analysis of Variance
---------------------------------------------------------
Sum of Mean
Source DF Squares Square
Model 2 9532.7 4766.35
Error 84 9963.7 118.6
Total 86 19496.4
Root MSE XXXXX
R-Square XXXXX
Which is the causal direction: does a change in viscosity cause a change in temperature, or does a change in temperature cause a change in viscosity?
Calculate the
Root MSE, what we have called standard error, \(S_E\) in this course.What is the \(R^2\) value that would have been reported in the above output?
What is the interpretation of the slope coefficient, -3.75, and what are its units?
What is the viscosity prediction at 430K? And at 480K?
In the future you plan to use this model to adjust temperature, in order to meet a certain viscosity target. To do that you must be sure the change in temperature will lead to the desired change in viscosity.
What is the 95% confidence interval for the slope coefficient, and interpret this confidence interval in the context of how you plan to use this model.
The standard error features prominently in all derivations related to least squares. Provide an interpretation of it and be specific in any assumption(s) you require to make this interpretation.