5.6. Experiments with a single variable at two levels¶
This is the simplest type of experiment. It involves an outcome variable,
Has the reaction yield increased when using catalyst A or B?
Does the concrete’s strength improve when adding a particular binder or not?
Does the plastic’s stretchability improve when extruded at various temperatures (a low or high temperature)?
We can perform several runs (experiments) at level A, and some runs at level B. These runs are randomized (i.e. do not perform all the A runs, and then the B runs). We strive to hold all other disturbance variables constant so we pick up only the A-to-B effect. Disturbances are any variables that might affect
5.6.1. Recap of group-to-group differences¶
We have already seen in the univariate statistics section how to analyze this sort of data. We first calculate a pooled variance, then a
We consider the effect of changing from condition A to condition B to be a statistically significant effect when this confidence interval does not span zero. However, the width of this interval and how symmetrically it spans zero can cause us to come to a different, practical conclusion. In other words, we override the narrow statistical conclusion based on the richer information we can infer from the width of the confidence interval and the variance of the process.
5.6.2. Using linear least squares models¶
There’s another interesting way that you can analyze data from an A versus B set of tests and get the identical result to the methods we showed in the section where we made group-to-group comparisons. In this method, instead of using a
where
lm_difference <- function(groupA, groupB)
{
# Build a linear model with groupA = 0, and groupB = 1
y.A <- groupA[!is.na(groupA)]
y.B <- groupB[!is.na(groupB)]
x.A <- numeric(length(y.A))
x.B <- numeric(length(y.B)) + 1
y <- c(y.A, y.B)
x <- c(x.A, x.B)
x <- factor(x, levels=c("0", "1"), labels=c("A", "B"))
model <- lm(y ~ x)
return(list(summary(model), confint(model)))
}
brittle <- read.csv('http://openmv.net/file/brittleness-index.csv')
# We developed the "group_difference" function in the Univariate section
group_difference(brittle$TK104, brittle$TK107)
lm_difference(brittle$TK104, brittle$TK107)
Use this function in the same way you did in the carbon dioxide exercise in the univariate section. For example, you will find when comparing TK104 and TK107 that
Both methods give identical results, but by very different routes.
5.6.3. The importance of randomization¶
We emphasized in a previous section that experiments must be performed in random order to avoid any unmeasured, and uncontrolled, disturbances from impacting the system.
The concept of randomization was elegantly described in an example by Fisher in Chapter 2 of his book, The Design of Experiments. A lady claims that she can taste the difference in a cup of tea when the milk is added after the tea or when the tea is added after the milk. By setting up
Let’s take a look at a more engineering-oriented example. We previously considered the brittleness of a material made in either TK104 or TK107. The same raw materials were charged to each reactor. So, in effect, we are testing the difference due to using reactor TK104 or reactor TK107. Let’s call them case A (TK104) and case B (TK107) so the notation is more general. We collected 20 brittleness values from TK104 and 23 values from TK107. We will only use the first 8 values from TK104 and the first 9 values from TK107 (you will see why soon):
Case A |
254 |
440 |
501 |
368 |
697 |
476 |
188 |
525 |
|
Case B |
338 |
470 |
558 |
426 |
733 |
539 |
240 |
628 |
517 |
Fisher’s insight was to create one long vector of these outcomes (length of vector =
Only one of the 24,310 sequences will correspond to the actual data printed in the above table. Although all the other realizations are possible, they are fictitious. We do this because the null hypothesis is that there is no difference between A and B. Values in the table could have come from either system.
So for each of the 24,310 realizations, we calculate the difference of the averages between A and B,
Had we used a formal test of differences where we pooled the variances, we would have found a
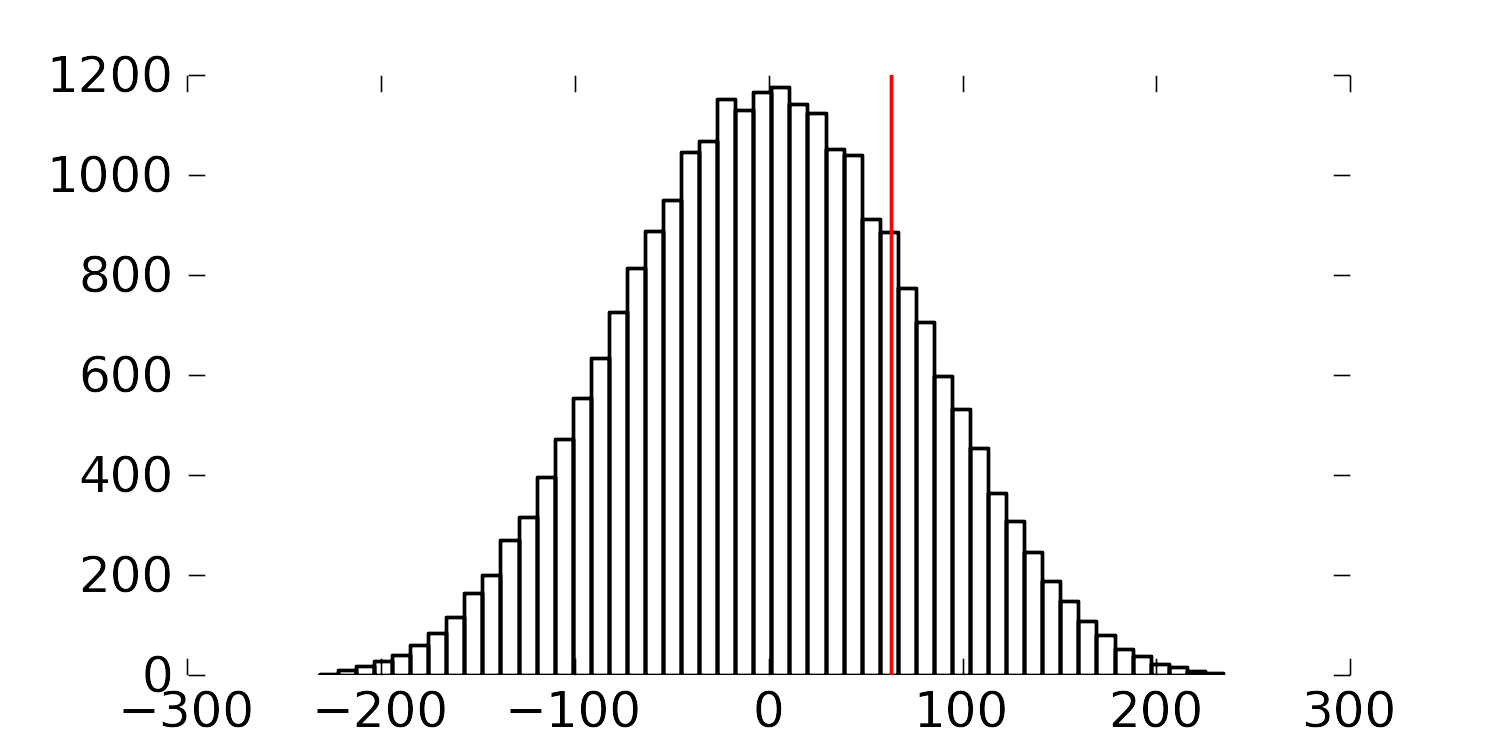
The figure shows the differences in the averages of A and B for the 24,310 realizations. The vertical line represents the difference in the average for the one particular set of numbers we measured in the experiment.
Recall that independence is required to calculate the
The reason we prefer using the