6.5.19. Using indicator variables in a latent variable model¶
Indicator variables, also called dummy variables, are most often binary variables that indicate the presence or absence of a certain effect. For example, a variable that shows if reactor A or reactor B was used. Its value is either a 0 or a 1 in the data matrix
Sometimes these variables are imported into the computer software, but not used in the model. They are only used in the display of results, where the indicator variable is shown in a different colour or with a different marker shape. We will see an example of this for process troubleshooting, to help isolate causes for poor yield from a process:
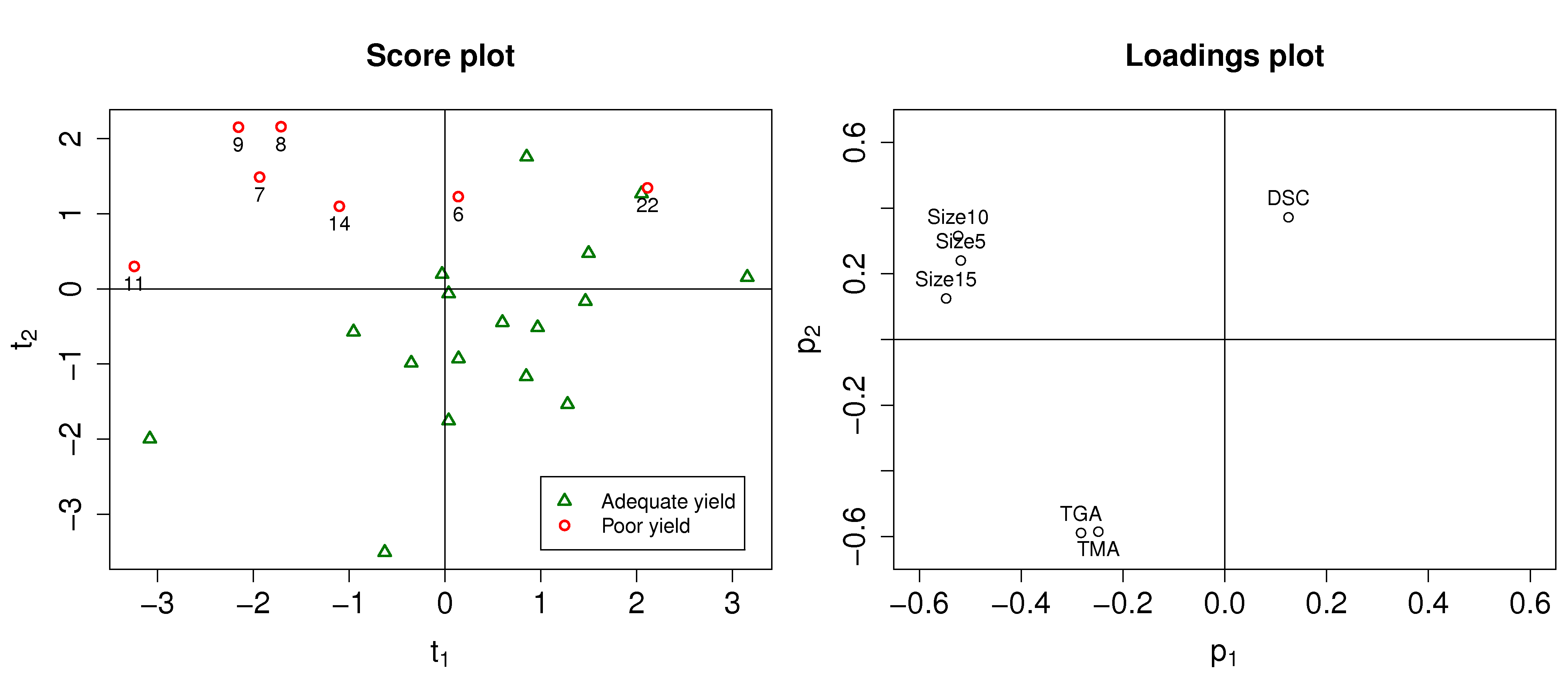
If the variable is included in the model then it is centered and scaled (preprocessed) like any other variable. Care must be taken to make sure this variable is reasonably balanced. There is no guide as to how balanced it needs to be, but there should be a good number of observations of both zeros and ones. The extreme case is where there are
Interpreting these sort of variables in a loading plot is also no different; strong correlations with this variable are interpreted in the usual way.