2.9. The t-distribution¶
Suppose we have a quantity of interest from a process, such as the daily profit. In the preceding section we started to answer the useful and important question:
What is the range within which the true average value lies? E.g. the range for the true, but unknown, daily profit.
But we got stuck, because the lower and upper bounds we calculated for the true average,
which we derived by using the fact that
An obvious way out of our dilemma is to replace
There is one other requirement we have to ensure in order to use the
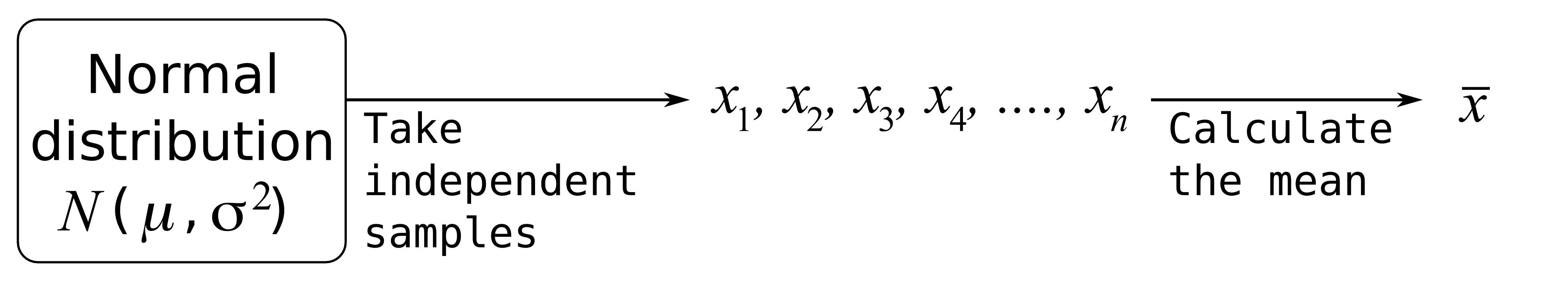
So given our
Compare this to the previous case where our
So the more practical and useful case where
Note that the new variable
We will come back to (1) in a minute; let’s first look at how we can calculate values from the
2.9.1. Calculating the t-distribution¶
In R we use the function
dt(x=..., df=...)to give us the values of the probability density values,dnorm(x, mean=..., sd=...)function for the normal distribution).The cumulative area from
pt(q=..., df=...). For example,pt(1.0, df=8)is 0.8267. Compare this to the R function for the standard normal distribution:pnorm(1.0, mean=0, sd=1)which returns 0.8413.And similarly to the
qnormfunction which returns the ordinate for a given area under the normal distribution, the functionqt(0.8267, df=8)returns 0.9999857, close enough to 1.0, which is the inverse of the previous example.
2.9.2. Using the t-distribution to calculate our confidence interval¶
Returning back to (1) we stated that
We can plot the
Then we write:
Now all the terms in the lower and upper bound are known, or easily calculated.
So we finish this section off with an example. We produce large cubes of polymer product on our process. We would like to estimate the cube’s average viscosity, but measuring the viscosity is a destructive laboratory test. So using 9 independent samples taken from this polymer cube, we get the 9 lab values of viscosity: 23, 19, 17, 18, 24, 26, 21, 14, 18.
If we repeat this process with a different set of 9 samples we will get a different average viscosity. So we recognize the average of a sample of data, is itself just a single estimate of the population’s average. What is more helpful is to have a range, given by a lower and upper bound, that we can say the true population mean lies within.
The average of these nine values is
Using the Central limit theorem, what is the distribution from which
This also requires the assumption that the samples are independent estimates of the population viscosity. We don’t have to assume the
What is the distribution of the sample average? What are the parameters of that distribution?
The sample average is normally distributed as
Assume, for some hypothetical reason, that we know the population viscosity standard deviation is
The interval is calculated using from an earlier equation when discussing the normal distribution:
We can confirm these 9 samples are normally distributed by using a q-q plot (not shown, but you can use the code below to generate the plot). This is an important requirement to use the
Calculate an estimate of the standard deviation.
Now construct the
It comes the
Construct an interval, symbolically, that will contain the population mean of the viscosity. Also calculate the lower and upper bounds of the interval assuming the internal to span 95% of the area of this distribution.
The interval is calculated using (2):
using from R that
qt(0.025, df=8)andqt(0.975, df=8), which gives2.306004
Comparing the answers for parts 4 and 8 we see the interval, for the same level of 95% certainty, is wider when we have to estimate the standard deviation. This makes sense: the standard deviation is an estimate (meaning there is error in that estimate) of the true standard deviation. That uncertainty must propagate, leading to a wider interval within which we expect to locate the true population viscosity,
We will interpret confidence intervals in more detail a little later on.