4.10. More than one variable: multiple linear regression (MLR)
4.10. More than one variable: multiple linear regression (MLR)¶
We now move to including more than one explanatory variable in the linear model. We will:
introduce some matrix notation for this section
show how the optimization problem is solved to estimate the model parameters
how to interpret the model coefficients
extend our tools from the previous section to analyze the MLR model
use integer (yes/no or on/off) variables in our model.
First some motivating examples:
A relationship exists between = reactant concentration and = temperature with respect to = reaction rate. We already have a linear model between , but we want to improve our understanding of the system by learning about the temperature effect, .
We want to predict melt index in our reactor from the reactor temperature, but we know that the feed flow and pressure are also good explanatory variables for melt index. How do these additional variables improve the predictions?
We know that the quality of our plastic product is a function of the mixing time, and also the mixing tank in which the raw materials are blended. How do we incorporate the concept of a mixing tank indicator in our model?
To help the discussion below it is useful to omit the least squares model’s intercept term. We do this by first centering the data.
This indicates that if we fit a model where the and vectors are first mean-centered, i.e. let and , then we still estimate the same slope for , but the intercept term is zero. All we gain from this is simplification of the subsequent analysis. Of course, if you need to know what was, you can use the fact that . Nothing else changes: the and all other model interpretations remain the same. You can easily prove this for yourself.
So in the rest of the this section we will omit the model’s intercept term, since it can always be recovered afterwards.
The general linear model is given by:
And writing the last equation times over for each observation in the data:
where:
:
:
:
:
4.10.2. Estimating the model parameters via optimization¶
As with the simple least squares model, , we aim to minimize the sum of squares of the errors in vector . This least squares objective function can be written compactly as:
Taking partial derivatives with respect to the entries in and setting the result equal to a vector of zeros, you can prove to yourself that . You might find the Matrix Cookbook useful in solving these equations and optimization problems.
Three important relationships are now noted:
An estimate of the standard error is given by: , where is the number of parameters estimated in the model and is the number of observations.
These relationships imply that our estimates of the model parameters are unbiased (the first line), and that the variability of our parameters is related to the matrix and the model’s standard error, .
Going back to the single variable case we showed in the section where we derived confidence intervals for and that:
Notice that our matrix definition, , gives exactly the same result, remembering the variables have already been centered in the matrix form. Also recall that the variability of these estimated parameters can be reduced by (a) taking more samples, thereby increasing the denominator size, and (b) by including observations further away from the center of the model.
Example
Let , and , and . By inspection, the and variables are negatively correlated, and the and variables are positively correlated (also positive covariance). Refer to the definition of covariance in an equation from the prior section.
After mean centering the data we have that , and and . So in matrix form:
The and matrices can then be calculated as:
Notice what these matrices imply (remembering that the vectors in the matrices have been centered). The matrix is a scaled version of the covariance matrix of . The diagonal terms show how strongly the variable is correlated with itself, which is the variance, and always a positive number. The off-diagonal terms are symmetrical, and represent the strength of the relationship between, in this case, and . The off-diagonal terms for two uncorrelated variables would be a number close to, or equal to zero.
The inverse of the matrix is particularly important - it is related to the standard error for the model parameters - as in: .
The non-zero off-diagonal elements indicate that the variance of the coefficient is related to the variance of the coefficient as well. This result is true for most regression models, indicating we can’t accurately interpret each regression coefficient’s confidence interval on its own.
For the two variable case, , the general relationship is that:
where represents the correlation between variable and . What happens as the correlation between the two variables increases?
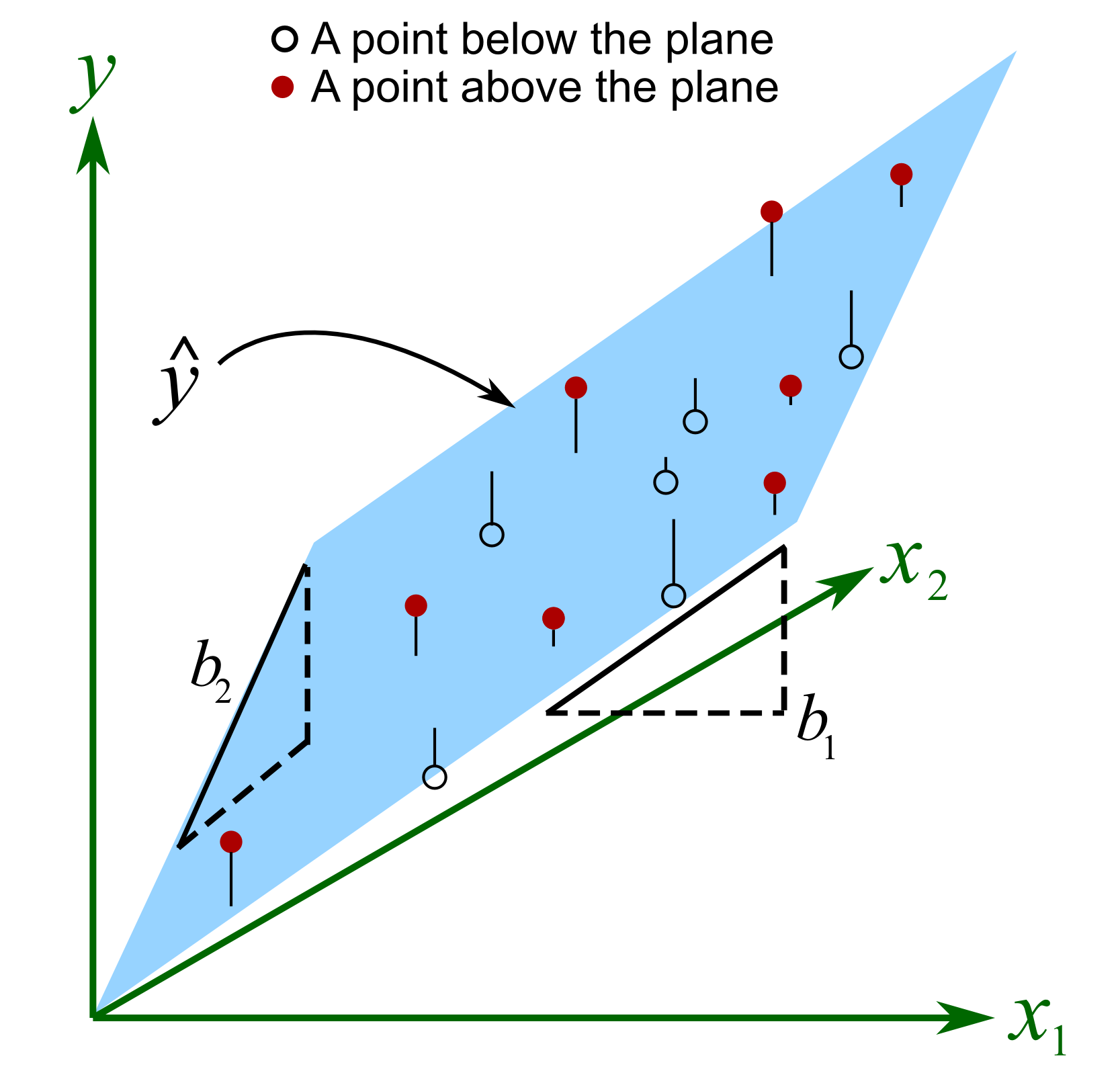
Let’s take a look at the case where . We can plot this on a 3D plot, with axes of , and :
The points are used to fit the plane by minimizing the sum of square distances shown by vertical lines from each point to the plane. The interpretation of the slope coefficients for and is not the same as for the case with just a single variable.
When we have multiple variables, then the value of coefficient is the average change we would expect in for a one unit change in provided we hold fixed. It is the last part that is new: we must assume that other variables are fixed.
For example, let , where is reactor temperature in Kelvin, and is substrate concentration in g/L, and is yield in , for a bioreactor reactor system. The coefficient is the decrease in yield for every 1 Kelvin increase in temperature, holding the substrate concentration fixed.
This is a good point to introduce some terminology you might come across. Imagine you have a model where is the used vehicle price and is the mileage on the odometer (we expect that will be negative) and is the number of doors on the car. You might hear the phrase: “the effect of the number of doors, controlling for mileage, is not significant”. The part “controlling for …” indicates that the controlled variable has been added to regression model, and its effect is accounted for. In other words, for two vehicles with the same mileage, the coefficient indicates whether the second hand price increases or decreases as the number of doors on the car changes (e.g. a 2-door vs a 4-door car).
In the prior example, we could say: the effect of substrate concentration on yield, controlling for temperature, is to increase the yield by 3.2 for every increase in 1 g/L of substrate concentration.
4.10.4. Integer (dummy, indicator) variables in the model¶
Now that we have introduced multiple linear regression to expand our models, we also consider these sort of cases:
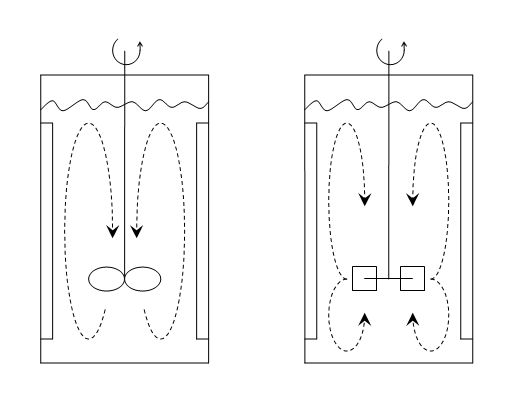
We want to predict yield, but want to indicate whether a radial or axial impeller was used in the reactor and learn whether it has any effect on yield.
Is there an important difference when we add the catalyst first and then the reactants, or the reactants followed by the catalyst?
Use an indicator variable to show if the raw material came from the supplier in Spain, India, or Vietnam and interpret the effect of supplier on yield.
We will start with the simplest case, using the example of the radial or axial impeller. We wish to understand the effect on yield, , as a function of the impeller type, and impeller speed, .
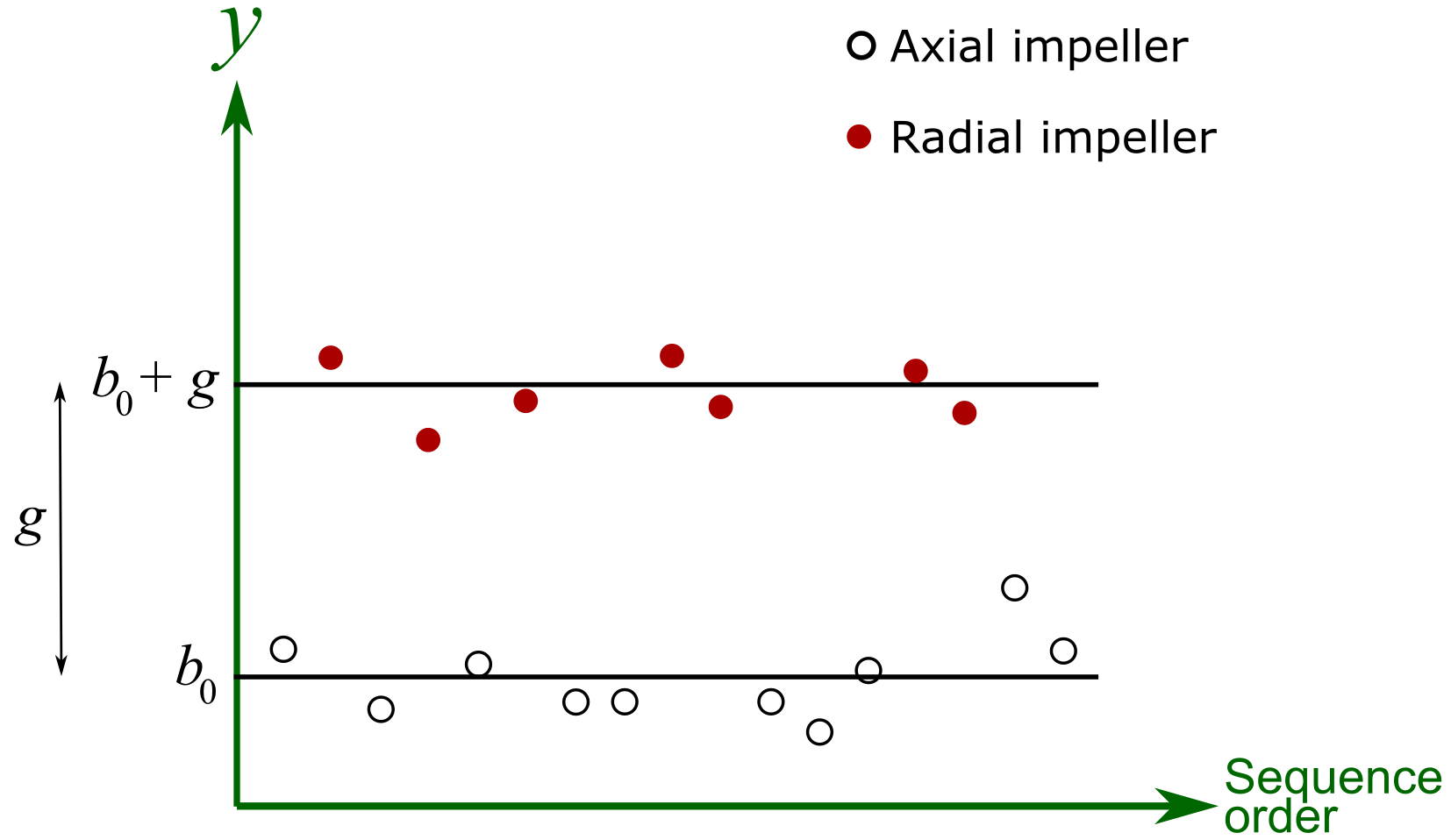
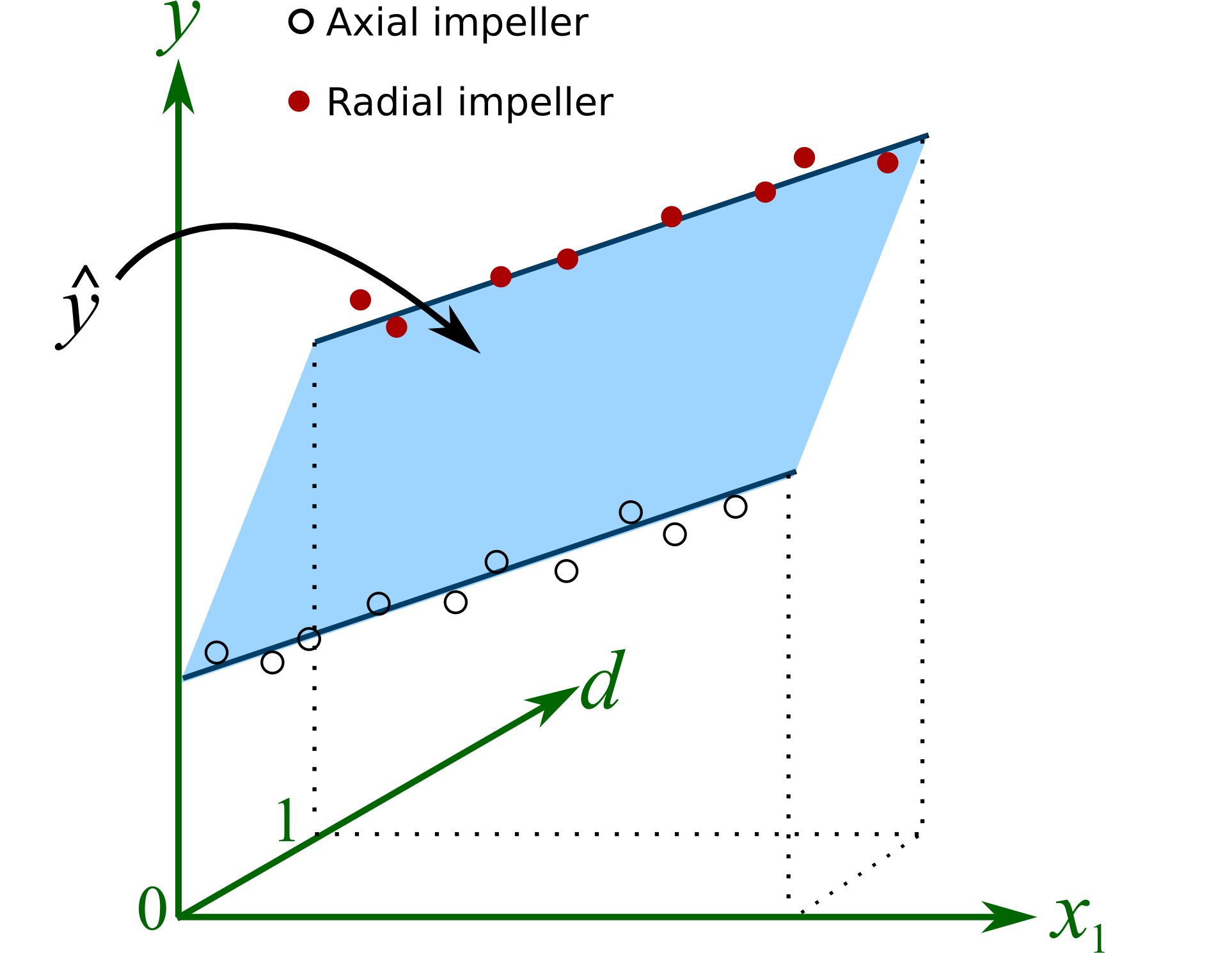
where if an axial impeller was used, or if a radial impeller was used. All other least squares assumptions hold, particularly that the variance of is unrelated to the value of . For the initial discussion let’s assume that , then geometrically, what is happening here is:
The parameter, estimated by , is the difference in intercept when using a different impeller type. Note that the lines are parallel.
Now if , then the horizontal lines in the above figure are tilted, but still parallel to each other. Nothing else is new here, other than the representation of the variable used for . The interpretation of its coefficient, , is the same as with any other least squares coefficient. In this particular example, had , it would indicate that the average decrease in yield is 56 when using a radial impeller.
The rest of the analysis tools for least squares models can be used quite powerfully. For example, a 95% confidence interval for the impeller variable might have been:
which would indicate the impeller type has no significant effect on the yield amount, the -variable.
Integer variables are also called dummy variables or indicator variables. Really what is happening here is the same concept as for multiple linear regression, the equation of a plane is being estimated. We only use the equation of the plane at integer values of , but mathematically the underlying plane is actually continuous.
We have to introduce additional terms into the model if we have integer variables with more than 2 levels. In general, if there are -levels, then we must include terms. For example, if we wish to test the effect of = yield achieved from the raw material supplier in Spain, India, or Vietnam, we could code:
Spain: and
India: and
Vietnam: and .
and solve for the least squares model: , where is the effect of the Indian supplier, holding all other terms constant (i.e. it is the incremental effect of India relative to Spain); is the incremental effect of the Vietnamese supplier relative to the base case of the Spanish supplier. Because of this somewhat confusing interpretation of the coefficients, sometimes people will assume they can sacrifice an extra degree of freedom, but introduce new terms for the levels of the integer variable, instead of terms.
Spain: and and
India: and and
Vietnam: and and
and , where the coefficients and are assumed to be more easily interpreted. However, calculating this model will fail, because there is a built-in perfect linear combination. The matrix is not invertible.