5.9.7. Saturated designs for screening¶
A saturated design can be likened to a well trained doctor asking you a few, but very specific, questions to identify a disease or problem. On the other hand, if you sit there just tell the doctor all your symptoms, you may or may not get an accurate diagnosis. Designed experiments, like visiting this doctor, shortens the time required to identify the major effects in a system, and to do so as accurately as possible, within limited budget.
Saturated designs are most suited for screening, and should always be run when you are investigating a new system with many factors. These designs are usually of resolution III and allow you to determine the main effects with a low number of experiments.
For example, a
Let’s see how by continuing the previous example, repeated again below with the corresponding values of
Experiment
A
B
C
D=AB
E=AC
F=BC
G=ABC
1
77.1
2
68.9
3
75.5
4
72.5
5
67.9
6
68.5
7
71.5
8
63.7
Use a least squares model to estimate the coefficients in the model:
where
How do you assess which main effects are important? There are eight data points and eight parameters, so there are no degrees of freedom and the residuals are all zero. In this case you have to use a Pareto plot, which requires that your variables have been suitably scaled in order to judge importance of the main effects relative to each other. The Pareto plot would be given as shown below, and as usual, it does not show the intercept term.
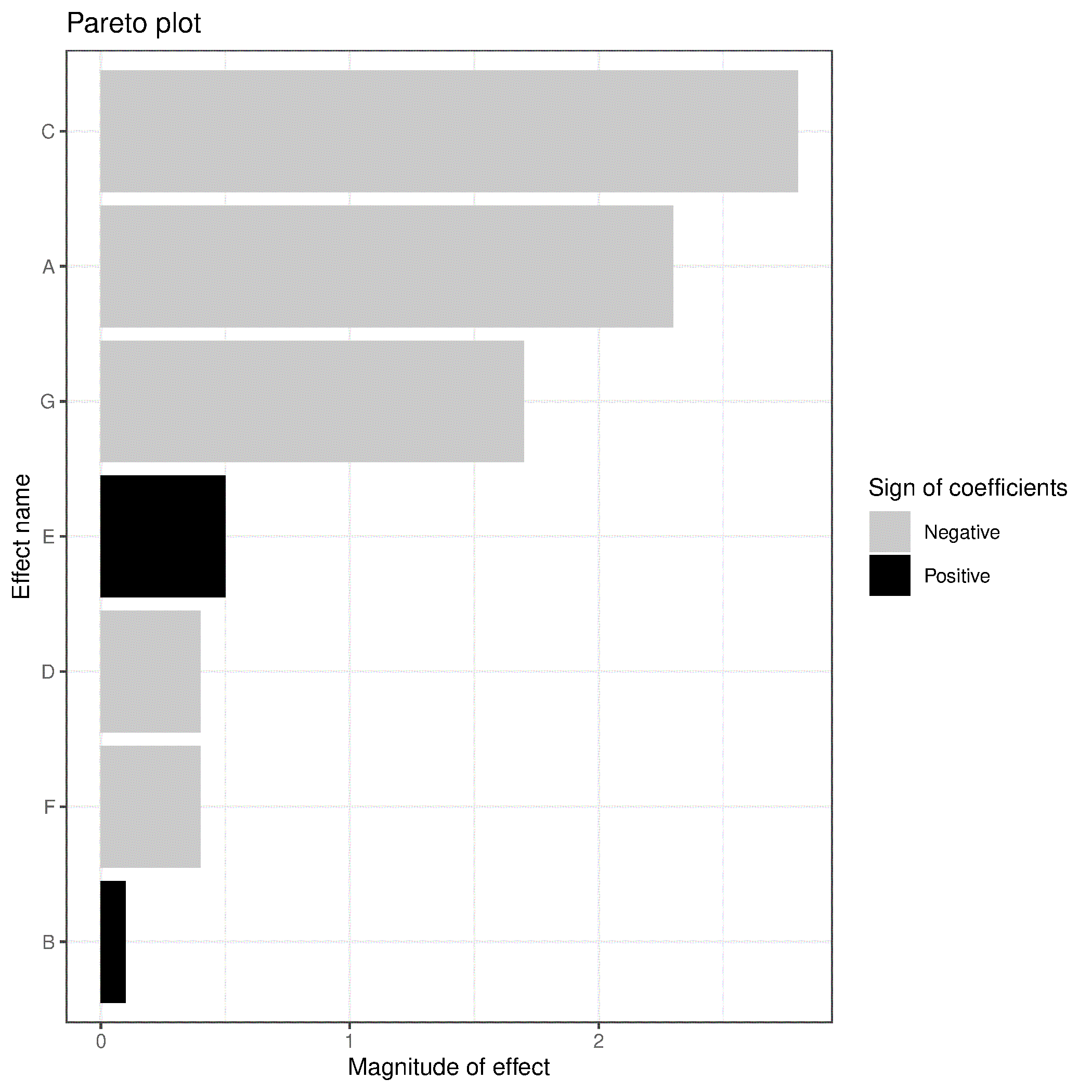
Significant effects would be A, C and G. The next largest effect, E, though fairly small, could be due to the main effect E or due to the AC interaction, because recall the confounding pattern, up to the 2 factor-interactions, for main effect was
The factor B is definitely not important to the response variable in this system and can be excluded in future experiments, as could F and D likely. Future experiments should focus on the A, C and G factors and their interactions. We show how to use these existing 8 experiments in the above table, but add a few new ones in the next section on design foldover and by understanding projectivity.
A side note on screening designs is a mention of Plackett and Burman designs. These designs can sometimes be of greater use than a highly fractionated design. A fractional factorial must have
An important mention to readers interested in other, arguable better screening strategies, is to consider definitive screening designs.