5.11. Response surface methods¶
The purpose of response surface methods (RSM) is to optimize a process or system. RSM is a way to explore the effect of operating conditions (the factors) on the response variable,
Initially, when we are far away from the optimum, we will use factorial experiments. As we approach the optimum then these factorials are replaced with better designs that more closely approximate conditions at the optimum.
Notice how it is a sequential approach. RSM then is a tool the describes how we should run these sequential sets of experiments. At the start of this section on designed experiments we showed how sequential experimentation (COST) leads to sub-optimal solutions. Why are we advocating sequential experimentation now? The difference is that here we use sequential experiments by changing multiple factors simultaneously, and not changing only one factor at a time.
RSM concept for a single variable: COST approach
We will however first consider just the effect of a single factor,
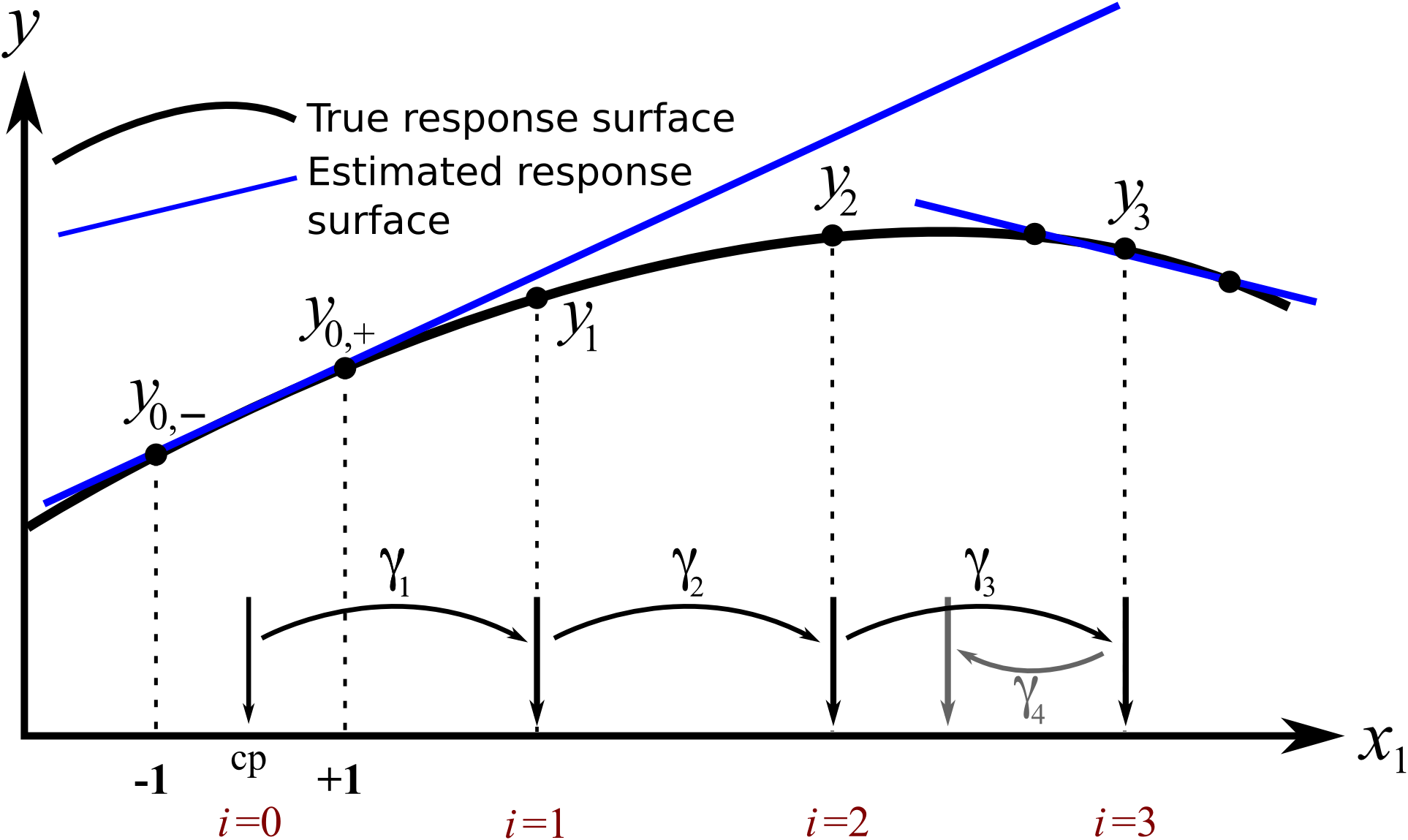
We start at the point marked
Make another step-size, this time of
Our next value of
This univariate example is in fact what experimenters do when using the COST approach described earlier. We have:
exploratory steps of different sizes towards an optimum
refit the model once we plateau
repeat
This approach works well if there really is only a single factor that affects the response. But with most systems there are multiple factors that affect the response. We show next how the exact same idea is used, only we change multiple variables at a time to find the optimum on the response surface.
5.11.1. Response surface optimization via a 2-variable system example¶
This example considers a new system here where two factors, temperature T, and substrate concentration S are known to affect the yield from a bioreactor. But in this example we are not just interested in yield, but actually the total profit from the system. This profit takes into account energy costs, raw materials costs and other relevant factors. The illustrations in this section show the contours of profit in light grey, but in practice these are obviously unknown.
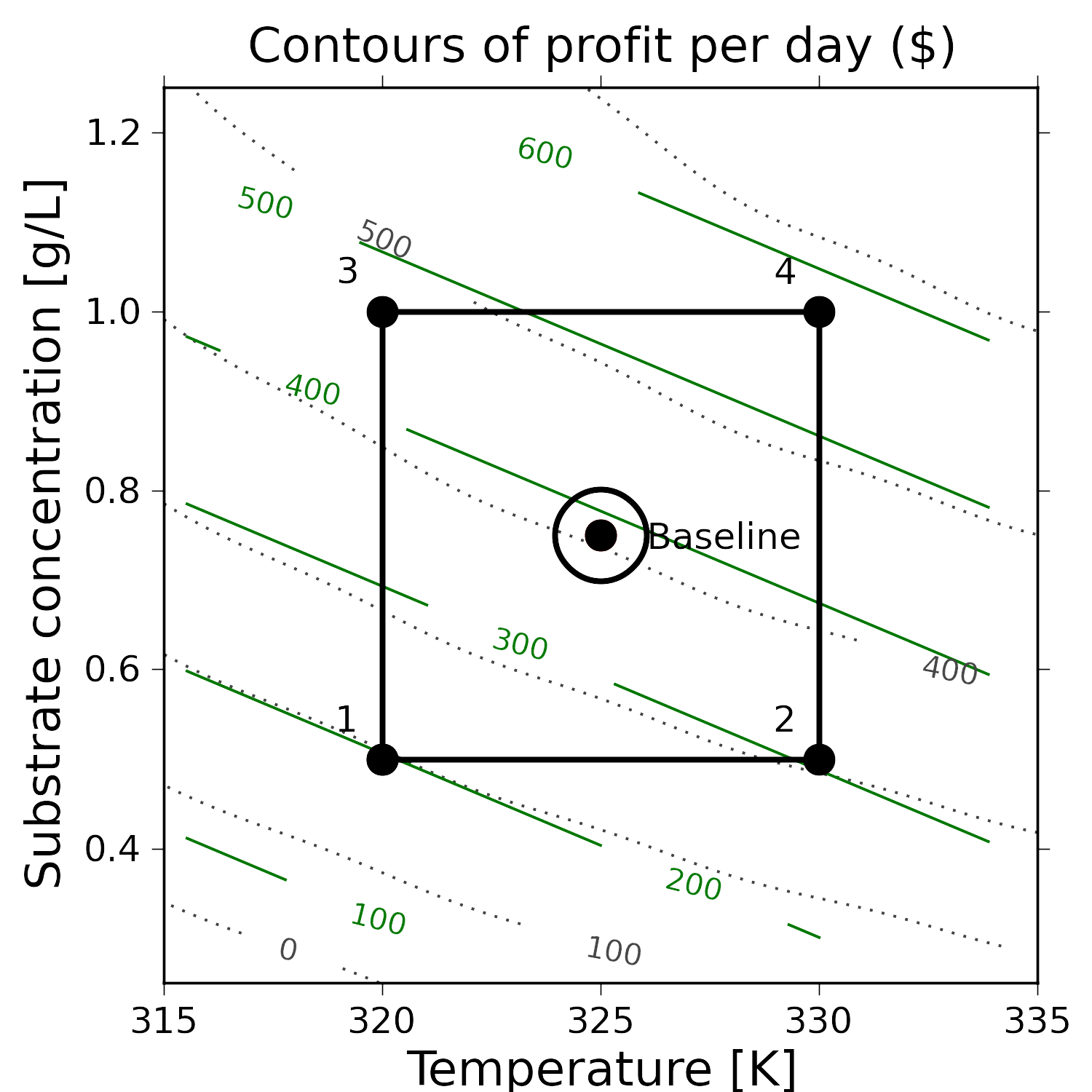
We currently operate at this baseline condition:
T = 325 K
S = 0.75 g/L
Profit = $407 per day
We start by creating a full factorial around this baseline by choosing
The results from the full factorial are in the table here:
Experiment |
T (actual) |
S (actual) |
T (coded) |
S (coded) |
Profit |
|---|---|---|---|---|---|
Baseline |
325 K |
0.75 g/L |
0 |
0 |
407 |
1 |
320 K |
0.50 g/L |
193 |
||
2 |
330 K |
0.50 g/L |
310 |
||
3 |
320 K |
1.0 g/L |
468 |
||
4 |
330 K |
1.0 g/L |
571 |
Clearly the promising direction to maximize profit is to operate at higher temperatures and higher substrate concentrations. But how much much higher and in what ratio should we increase
where
The model shows that we can expect an increase of $55/day of profit for a unit increase in
Similarly, we can increase
The interaction term is small, indicating the response surface is mostly linear in this region. The illustration shows the model’s contours (straight, green lines). Notice that the model contours are a good approximation to the actual contours (dotted, light grey), which are unknown in practice.
To improve our profit in the optimal way we move along our estimated model’s surface, in the direction of steepest ascent. This direction is found by taking partial derivatives of the model function, ignoring the interaction term, since it is so small.
This says for every
The simplest way to do this is just to pick a move size in one of the variables, then change the move size of the other one.
So we will choose to increase
So when we run the next experiment at these conditions. The daily profit is
We decide to make another move, in the same direction of steepest ascent, i.e. along the vector that points in the
K
g/L
Again, we determine profit at
K
g/L
The profit at this point is
Experiment |
T (actual) |
S (actual) |
T |
S |
Profit |
|---|---|---|---|---|---|
6 |
335 K |
1.97 g/L |
0 |
0 |
688 |
8 |
331 K |
1.77 g/L |
694 |
||
9 |
339 K |
1.77 g/L |
725 |
||
10 |
331 K |
2.17 g/L |
620 |
||
11 |
339 K |
2.17 g/L |
642 |
This time we have deciding to slightly smaller ranges in the factorial
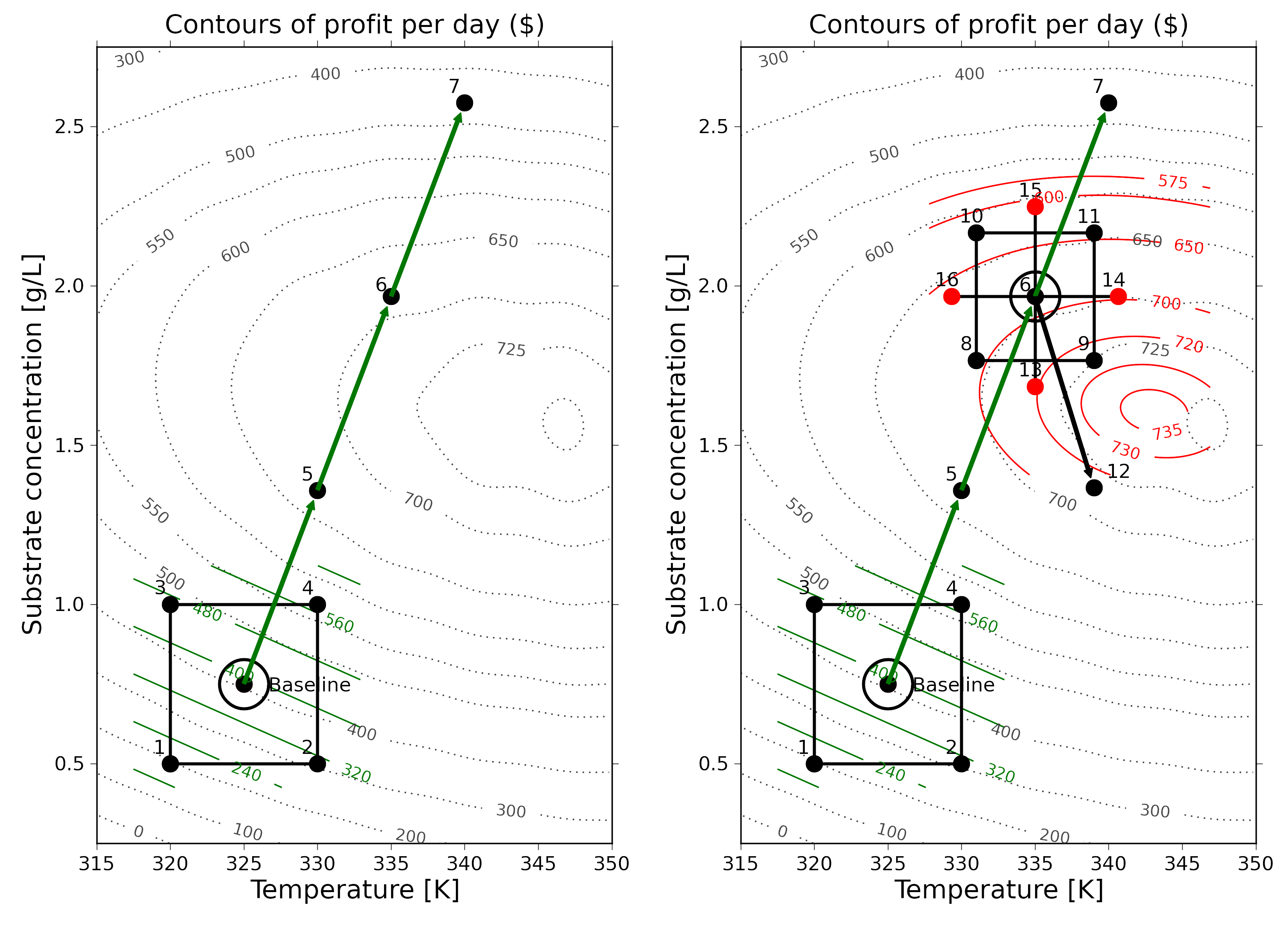
A least squares model from the 4 factorial points (experiments 8, 9, 10, 11, run in random order), seems to show that the promising direction now is to increase temperature but decrease the substrate concentration.
As before we take a step in the direction of steepest ascent of
We determine that at run 12 the profit is
One must realize that as one approaches an optimum we will find:
The response variable will start to plateau, since, recall that the first derivative is zero at an optimum, implying the surface flattens out, and all points, in all directions away from the optimum are worse off.
The response variable remains roughly constant for two consecutive jumps, because one has jumped over the optimum.
The response variable decreases, sometimes very rapidly, because we have overshot the optimum.
The presence of curvature can also be inferred when interaction terms are similar or larger in magnitude than the main effect terms.
An optimum therefore exhibits curvature, so a model that only has linear terms in it will not be suitable to use to find the direction of steepest ascent along the true response surface. We must add terms that account for this curvature.
Checking for curvature
The factorial’s center point can be predicted from
So when the measured center point value is quite different from the predicted center point in the linear model, then that is a good indication there is curvature in the response surface. The way to accommodate for that is to add quadratic terms to the estimate model.
Adding higher-order terms using central composite designs
We will not go into too much detail about central composite designs, other than to show what they look like for the case of 2 and 3 variables. These designs take an existing orthogonal factorial and augment it with axial points. This is great, because we can start off with an ordinary factorial and always come back later to add the terms to account for nonlinearity.
The axial points are placed
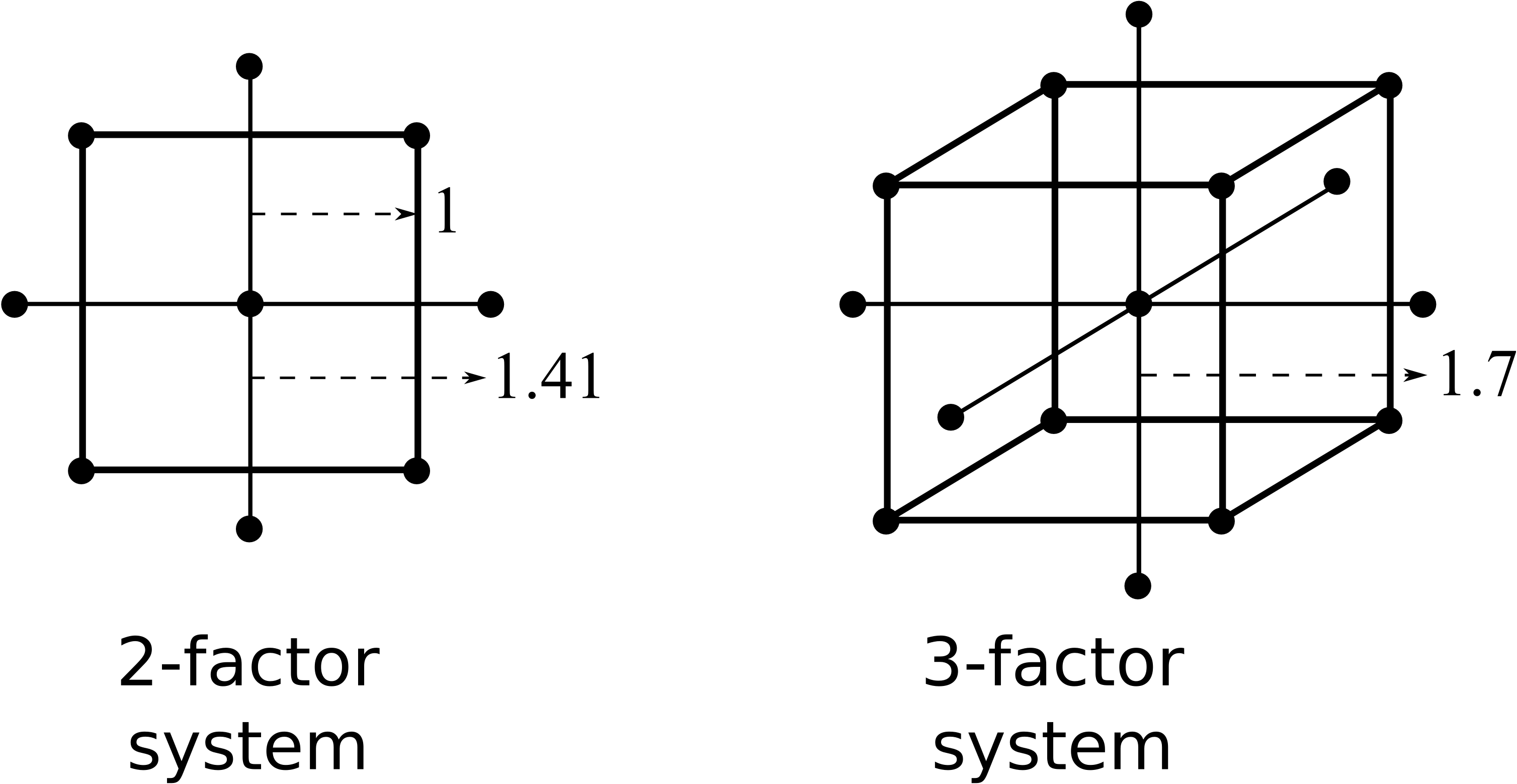
So a central composite design layout was added to the factorial in the above example and the experiments run, randomly, at the 4 axial points.
The four response values were
Notice how the linear terms estimated previously are the same! The quadratic effects are clearly significant when compared to the other effects, which was what prevented us from successfully using a linear model to project out to point 12 previously.
The final step in the response surface methodology is to plot this model’s contour plot and predict where to run the next few experiments. As the solid contour lines in the illustration show, we should run our next experiments roughly at
This is not exactly where the true process optimum is, but it is pretty close to it (the temperature of
This example has demonstrated how powerful response surface methods are. A minimal number of experiments has quickly converged onto the true, unknown process optimum. We achieved this by building successive least squares models that approximate the underlying surface. Those least squares models are built using the tools of fractional and full factorials and basic optimization theory, to climb the hill of steepest ascent.
5.11.2. The general approach for response surface modelling¶
Start at your baseline conditions and identify the main factors based on physics of the process, operator input, expert opinion input, and intuition. Also be aware of any constraints, especially for safe process operation. Perform factorial experiments (full or fractional factorials), completely randomized. Use the results from the experiment to estimate a linear model of the system:
The main effects are usually significantly larger than the two-factor interactions, so these higher interaction terms can be safely ignored. Any main effects that are not significant may be dropped for future iterations.
Use the model to estimate the path of steepest ascent (or descent if minimizing
The path of steepest ascent is climbed. Move any one of the main effects, e.g.
If any of the
One can make several sequential steps until the response starts to level off, or if you become certain you have entered a different operating mode of the process.
At this point you repeat the factorial experiment from step 1, making the last best response value your new baseline. This is also a good point to reintroduce factors that you may have omitted earlier. Also, if you have a binary factor; investigate the effect of alternating its sign at this point. These additional factorial experiments should also include center points.
Repeat steps 1 through 5 until the linear model estimate starts to show evidence of curvature, or that the interaction terms start to dominate the main effects. This indicates that you are reaching an optimum.
Curvature can be assessed by comparing the predicted center point, i.e. the model’s intercept =
If there is curvature, add axial points to expand the factorial into a central composite design. Now estimate a quadratic model of the form:
Draw contour plots of this estimated response surface (all data analysis software packages have contour plotting functions) and determine where to place your sequential experiments. You can also find the model’s optimum analytically by taking derivatives of the model function.
Summary
In the previous sections we used factorials and fractional factorials for screening the important factors. When we move to process optimization, we are assuming that we have already identified the important variables. In fact, we might find that variables that were previously important, appear unimportant as we approach the optimum. Conversely, variables that might have been dropped out earlier, become important at the optimum.
Response surface methods generally work best when the variables we adjust are numerically continuous. Categorical variables (yes/no, catalyst A or B) are handled by fixing them at one or the other value, and then performing the optimization conditional on those selected values. It is always worth investigating the alternative values once the optimum has been reached.
Many software packages provide tools that help with an RSM study. If you would like to use R in your work, we highly recommend the
rsmpackage by Russel Lenth, available in R. You can read more about the package in this article as well as a case-study.
5.12. Evolutionary operation¶
Evolutionary operation (EVOP) is a tool to help maintain a full-scale process at its optimum. Since the process is not constant, the optimum will gradually move away from its current operating point. Chemical processes drift due to things such as heat-exchanger fouling, build-up inside reactors and tubing, catalyst deactivation, and other slowly varying disturbances in the system.
EVOP is an iterative hunt for the process optimum by making small perturbations to the system. Similar to response surface methods, once every iteration is completed, the process is moved towards the optimum. The model used to determine the move direction and levels of next operation are from full or fractional factorials, or designs that estimate curvature, like the central composite design.
Because every experimental run is a run that is expected to produce saleable product (we don’t want off-specification product), the range over which each factor is varied must be small. Replicate runs are also made to separate the signal from noise, because the optimum region is usually flat.
Some examples of the success of EVOP and a review paper are in these readings:
George Box: Evolutionary Operation: A Method for Increasing Industrial Productivity”, Journal of the Royal Statistical Society (Applied Statistics), 6, 81 - 101, 1957.
William G. Hunter and J. R. Kittrell, “Evolutionary Operation: A Review”, Technometrics, 8, 389-397, 1966.
Current day examples of EVOP do not appear in the scientific literature much, because this methodology is now so well established.