6.5.5. PCA example: Food texture analysis¶
Let’s take a look at an example to consolidate and extend the ideas introduced so far. This data set is from a food manufacturer making a pastry product. Each sample (row) in the data set is taken from a batch of product where 5 quality attributes are measured:
Percentage oil in the pastry
The product’s density (the higher the number, the more dense the product)
A crispiness measurement, on a scale from 7 to 15, with 15 being more crispy.
The product’s fracturability: the angle, in degrees, through which the pasty can be slowly bent before it fractures.
Hardness: a sharp point is used to measure the amount of force required before breakage occurs.
A scatter plot matrix of these
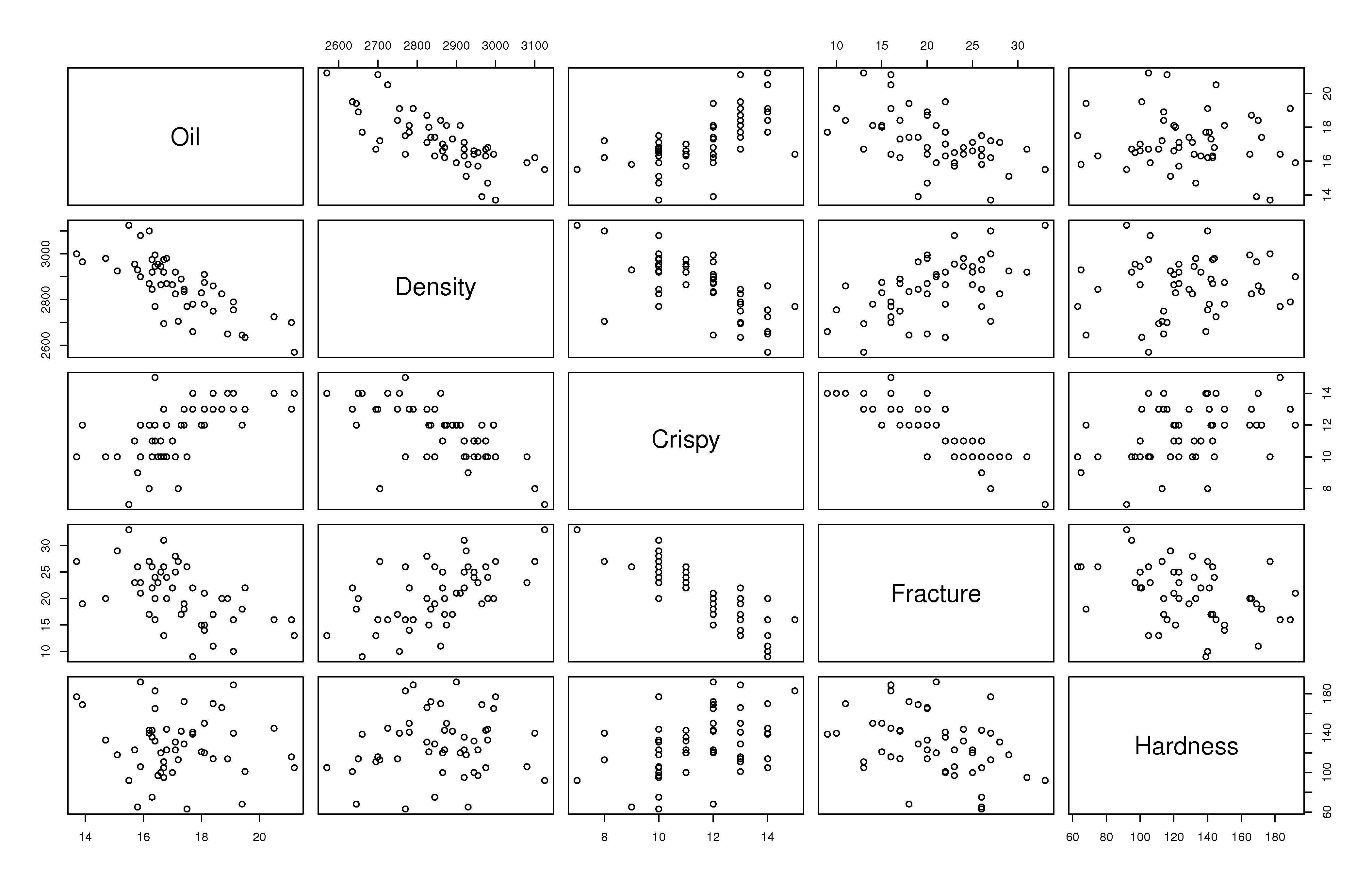
We can get by with this visualization of the data because
Preprocessing the data
The first step with PCA is to center and scale the data. The box plots show how the raw data are located at different levels and have arbitrary units.
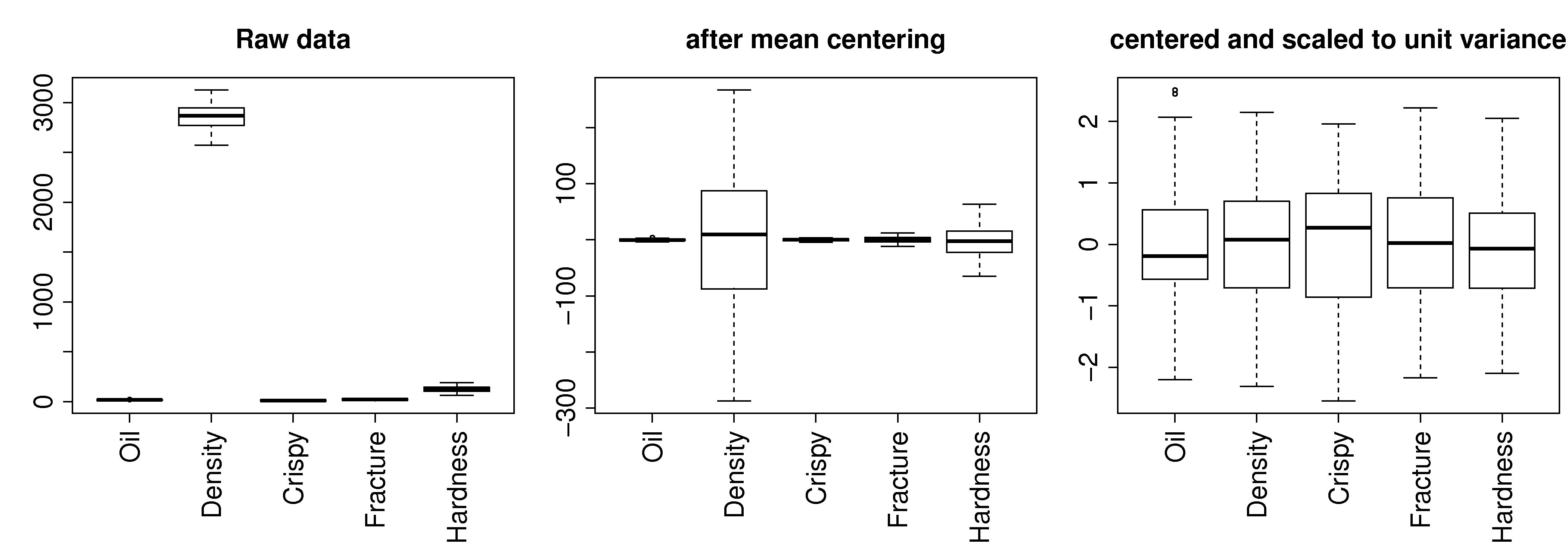
Centering removes any bias terms from the data by subtracting the mean value from each column in the matrix
Scaling removes the fact that the raw data could be in diverse units:
Then each column
Centering and scaling does not alter the overall interpretation of the data: if two variables were strongly correlated before preprocessing they will still be strongly correlated after preprocessing.
For reference, the mean and standard deviation of each variable is recorded below. In the last 3 columns we show the raw data for observation 33, the raw data after centering, and the raw data after centering and scaling:
Variable |
Mean |
Standard deviation |
Raw data |
After centering |
After autoscaling |
|---|---|---|---|---|---|
Oil |
17.2 |
1.59 |
15.5 |
-1.702 |
-1.069 |
Density |
2857.6 |
124.5 |
3125 |
267.4 |
+2.148 |
Crispy |
11.52 |
1.78 |
7 |
-4.52 |
-2.546 |
Fracture |
20.86 |
5.47 |
33 |
12.14 |
+2.221 |
Hardness |
128.18 |
31.13 |
92 |
-36.18 |
-1.162 |
Loadings:
We will discuss how to determine the number of components to use in a future section, and how to compute them, but for now we accept there are two important components,
Where we might visualize that first component by a bar plot:
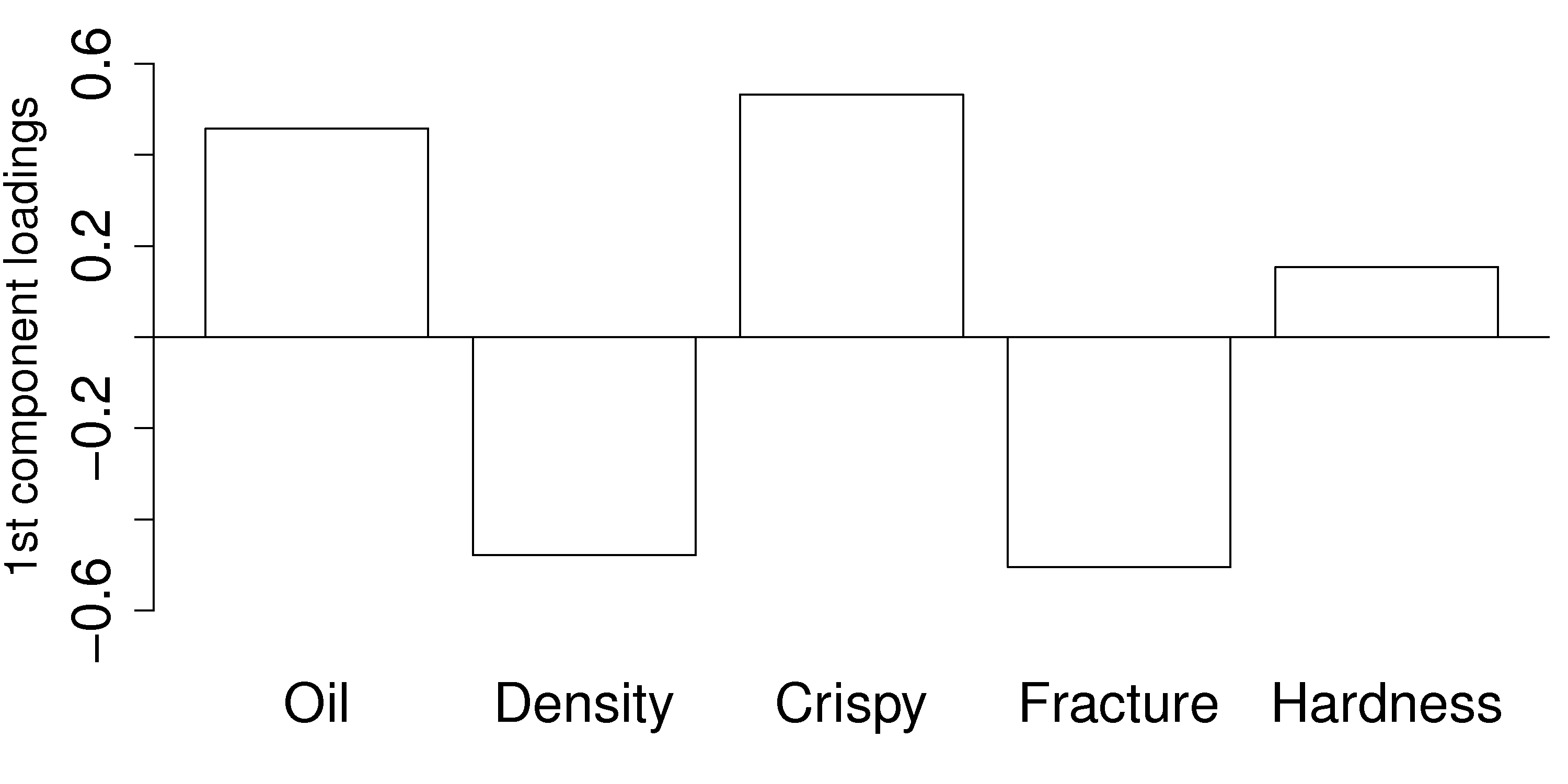
This plot shows the first component. All variables, except for hardness have large values in
Once we have centered and scaled the data, remember that a negative
For a pastry product to have a high
Scores:
Let’s examine the score values calculated. As shown in equation (1), the score value is a linear combination of the data,
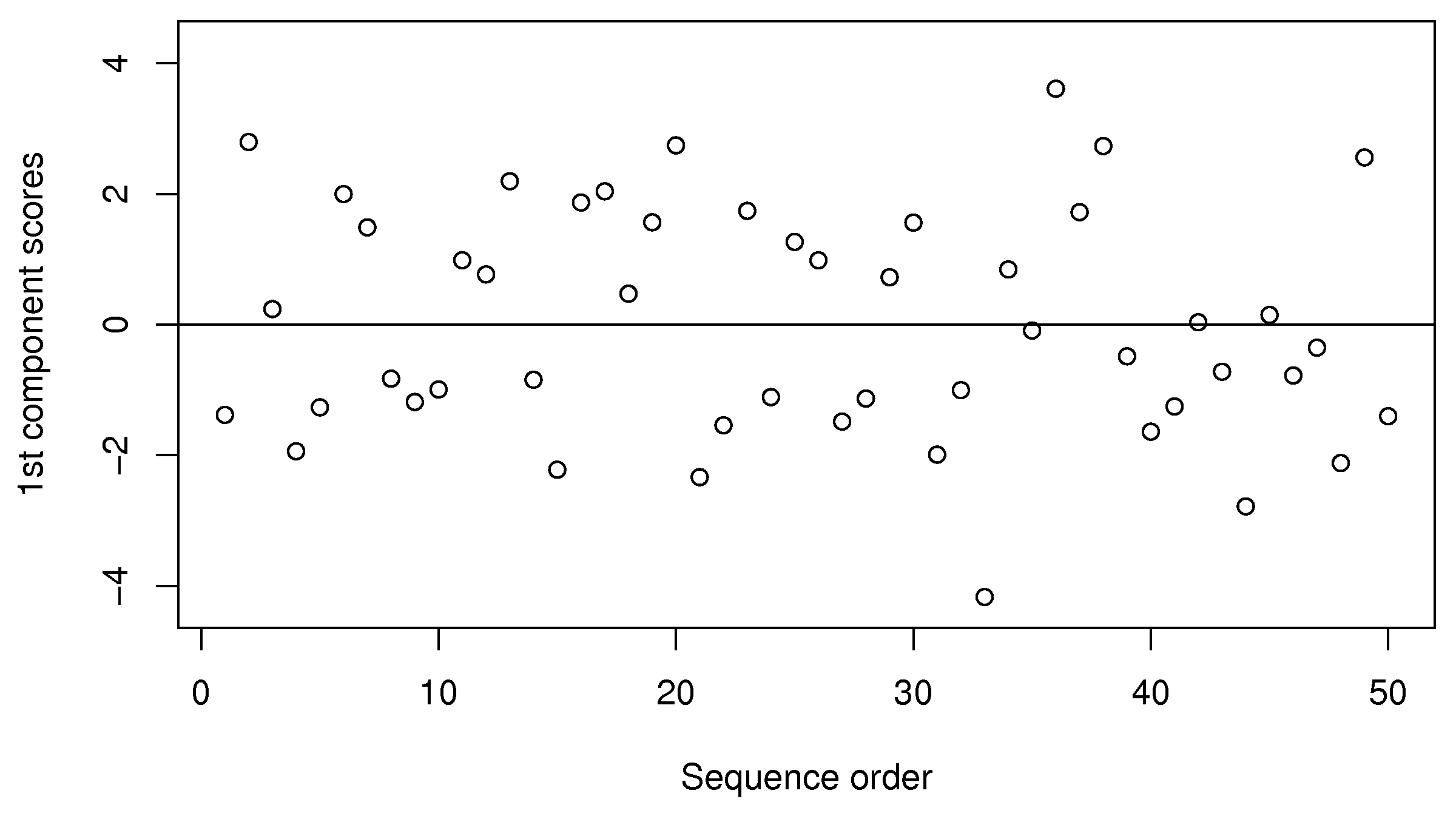
The samples appear to be evenly spread, some high and some low on the
We can also investigate sample 36, with a
We note here that this component explains 61% of the original variability in the data. It’s hard to say whether this is high or low, because we are unsure of the degree of error in the raw data, but the point is that a single variable summarizes about 60% of the variability from all 5 columns of raw data.
Loadings:
The second loading vector is shown as a bar plot:
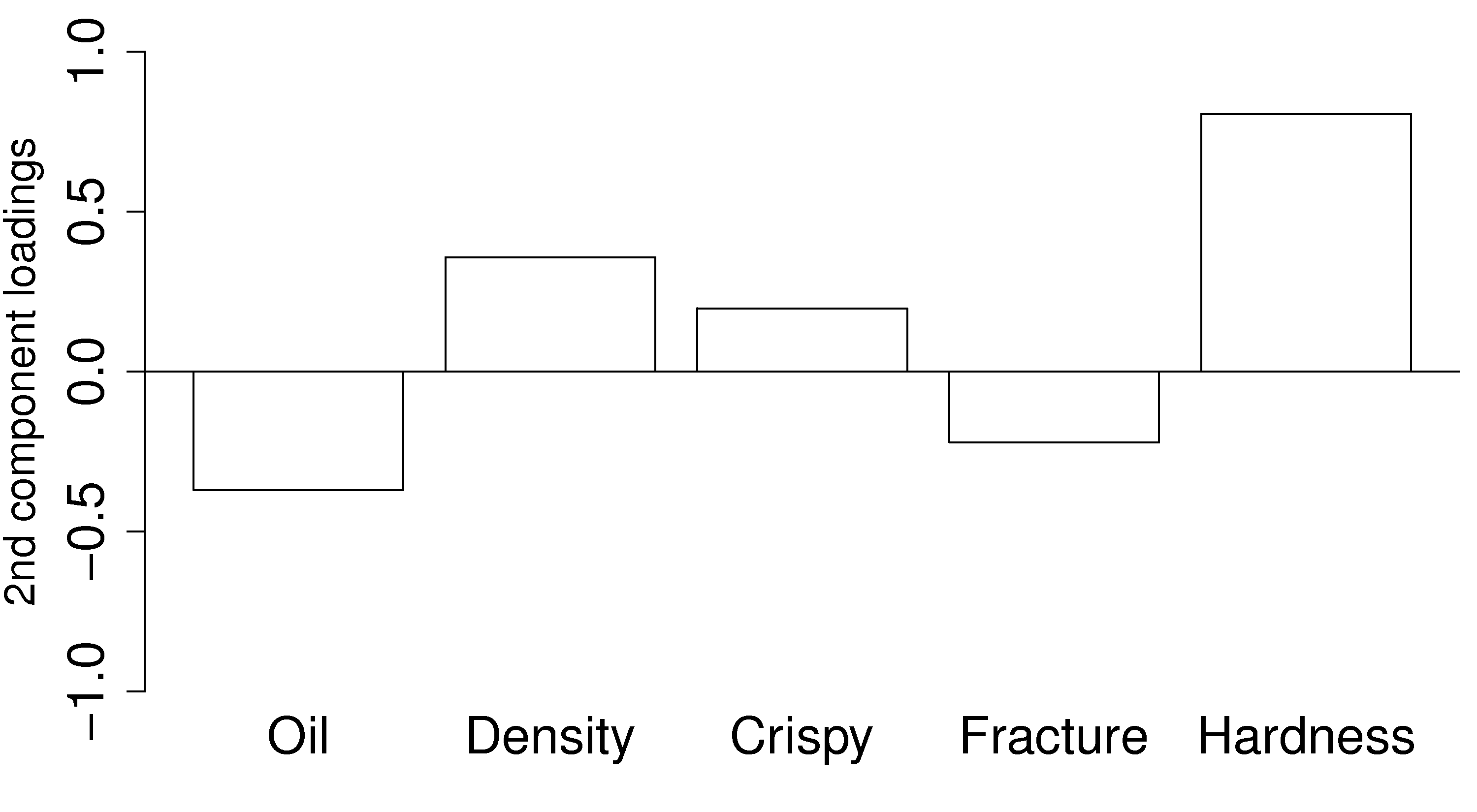
This direction is aligned mainly with the hardness variable: all other variables have a small coefficient in
Because this component is orthogonal to the first component, we can be sure that this hardness variation is independent of the first component. One valuable way to interpret and use this information is that you can adjust the variables in