6.5.21. PCA Exercises¶
Each exercise introduces a new topic or highlights some interesting aspect of PCA.
6.5.21.1. Room temperature data¶
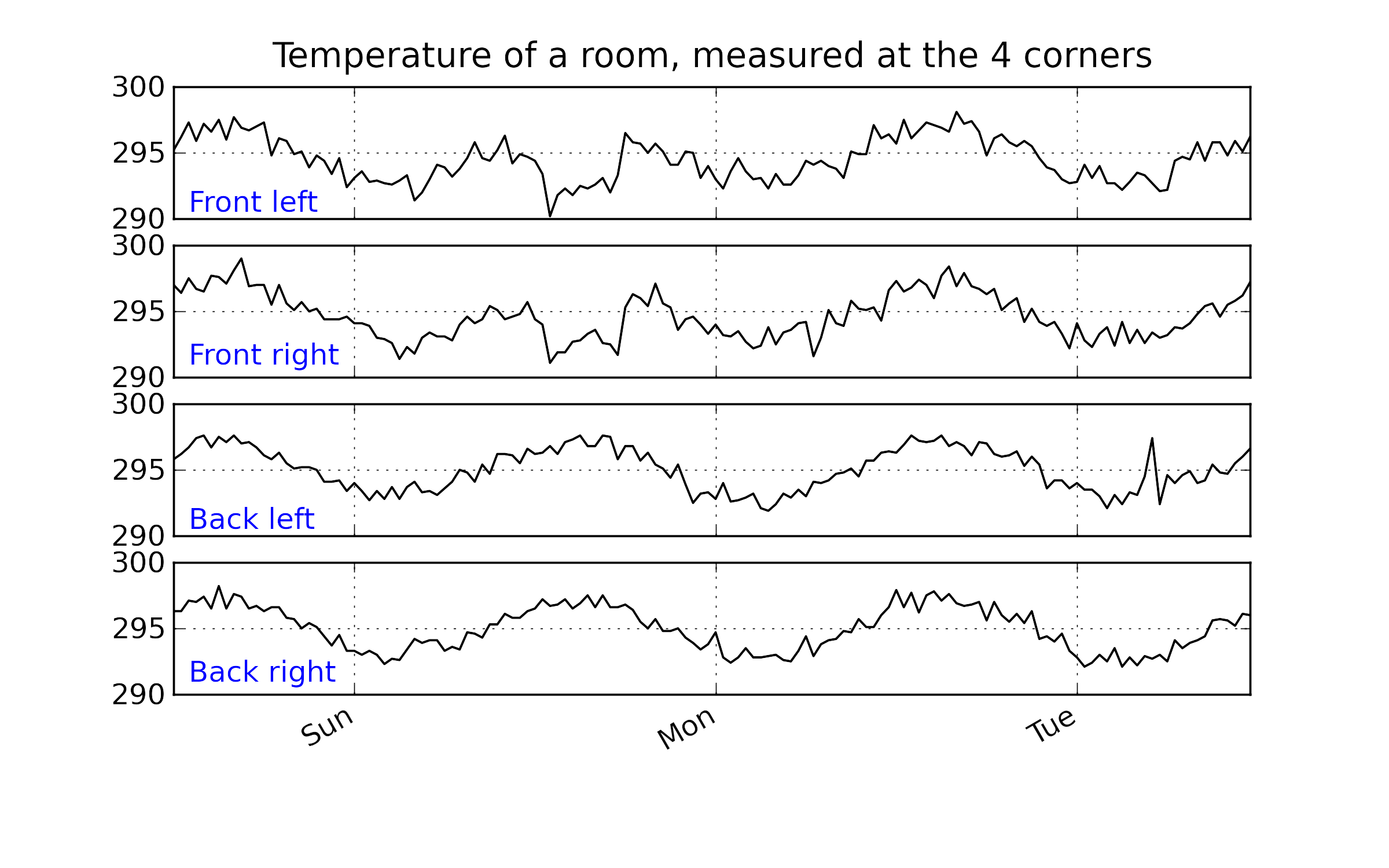
Web address: http://openmv.net/info/room-temperature
Description: Temperature measurements from 4 corners of a room
Objectives
Before even fitting the model:
How many latent variables do you expect to use in this model? Why?.
What do you expect the first loading vector to look like?
Now build a PCA model using any software package.
How much variation was explained by the first and second latent variables? Is this result surprising, given the earlier description of the dataset?
Plot a time series plot (also called a line plot) of
Plot a bar plot of the loadings for the second component. Given this bar plot, what are the characteristics of an observation with a large, positive value of
Now plot the time series plot for
Now use the concept of brushing to interrogate and learn from the model.
Plot a score plot of
Also plot the time series plot of the raw data.
Select a cluster of interest in the score plot and see the brushed values in the raw data. Are these the values you expected to be highlighted?
Next plot the Hotelling’s
Also plot the SPE line plot. Brush the outlier in the SPE plot and find its location in the score plot.
Why does this point have a large SPE value?
Describe how a 3-D scatter plot would look with
What have we learned?
Interpreted that a latent variable is often a true driving force in the system under investigation.
How to interpret a loadings vector and its corresponding score vector.
Brushing multivariate and raw data plots to confirm our understanding of the model.
Learned about Hotelling’s
We have confirmed how the scores are on the model plane, and the SPE is the distance from the model plane to the actual observation.
6.5.21.2. Food texture data set¶
Web address: http://openmv.net/info/food-texture
Description: Data from a food manufacturer making a pastry product. Each row contains the 5 quality attributes of a batch of product.
Fit a PCA model.
Report the
Plot the loadings plot as a bar plot for
What feature(s) of the raw data does the second component explain? Plot sequence-ordered plots of the raw data to confirm your answer.
Look for any observations that are unusual. Are there any unusual scores? SPE values? Plot contribution plots for the unusual observations and interpret them.
6.5.21.3. Food consumption data set¶
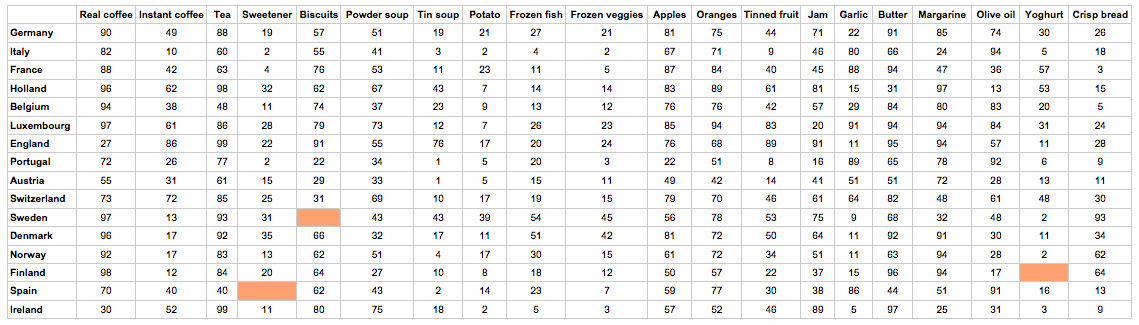
This data set has become a classic data set when learning about multivariate data analysis. It consists of
Missing data: yes
Web address: http://openmv.net/info/food-consumption
Description: The data table lists for each country the relative consumption of certain food items, such as tea, jam, coffee, yoghurt, and others.
Fit a PCA model to the data using 2 components.
Plot a loadings plot of
Since each column represents food consumption, how would you interpret a country with a high (positive or negative)
Now plot SPE after 2 components (don’t plot the default SPE, make sure it is the SPE only after two components). Use a contribution plot to interpret any interesting outliers.
Now add a third component and plot SPE after 3 components. What has happened to the observations you identified in the previous question? Investigate the loadings plot for the third component now (as a bar plot) and see which variables are heavily loaded in the 3rd component.
Also plot the
Now plot a score plot of the 3rd component against the 1st component. Generate a contribution plot in the score from the interesting observation(s) you selected in part 4. Does this match up with your interpretation of what the 3rd component is modelling?
What we learned:
Further practice of our skills in interpreting score plots and loading plots.
How to relate contribution plots to the loadings and the
6.5.21.4. Silicon wafer thickness¶
Web address: http://openmv.net/info/silicon-wafer-thickness
Description: These are nine thickness measurements recorded from various batches of silicon wafers. One wafer is removed from each batch and the thickness of the wafer is measured at the nine locations, as shown in the illustration.

Build a PCA model on all the data.
Plot the scores for the first two components. What do you notice? Investigate the outliers, and the raw data for each of these unusual observations. What do you conclude about those observations?
Exclude the unusual observations and refit the model.
Now plot the scores plot again; do things look better? Record the
Plot a loadings plot for the first component. What is your interpretation of
And the interpretation of
Also plot the corresponding time series plot for
Repeat the above question for the second component.
Finally, plot both the
What we learned:
Identifying outliers; removing them and refitting the model.
Variability in a process can very often be interpreted. The
6.5.21.5. Process troubleshooting¶
Recent trends show that the yield of your company’s flagship product is declining. You are uncertain if the supplier of a key raw material is to blame, or if it is due to a change in your process conditions. You begin by investigating the raw material supplier.
The data available has:
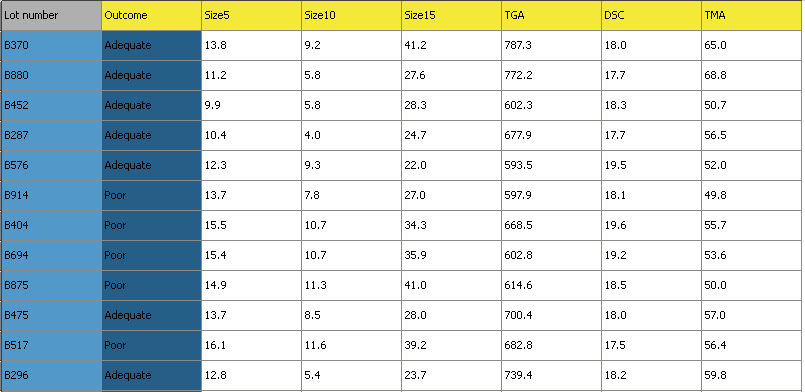
Web address: http://openmv.net/info/raw-material-characterization
Description: 3 of the 6 measurements are size values for the plastic pellets, while the other 3 are the outputs from thermogravimetric analysis (TGA), differential scanning calorimetry (DSC) and thermomechanical analysis (TMA), measured in a laboratory. These 6 measurements are thought to adequately characterize the raw material. Also provided is a designation
AdequateorPoorthat reflects the process engineer’s opinion of the yield from that lot of materials.
Import the data, and set the Outcome variable as a secondary identifier for each observation, as shown in the illustration below. The observation’s primary identifier is its batch number.
Build a latent variable model for all observations and use auto-fit to determine the number of components. If your software does not have and auto-fit features (cross-validation), then use a Pareto plot of the eigenvalues to decide on the number of components.
Interpret component 1, 2 and 3 separately (using the loadings bar plot).
Now plot the score plot for components 1 and 2, and colour code the score plot with the
Outcomevariable. Interpret why observations withPooroutcome are at their locations in the score plot (use a contribution plot).What would be your recommendations to your manager to get more of your batches classified as
Adequaterather thanPoor?Now build a model only on the observations marked as
Adequatein the Outcome variable.Re-interpret the loadings plot for
What we learned:
How to use an indicator variable in the model to learn more from our score plot.
How to build a data set, and bring in new observations as testing data.