6.5.16. Determining the number of components to use in the model with cross-validation
Cross-validation is a general tool that helps to avoid over-fitting - it can be applied to any model, not just latent variable models.
As we add successive components to a model we are increasing the size of the model, , and we are explaining the model-building data, , better and better. (The equivalent in least squares models would be to add additional -variable terms to the model.) The model’s value will increase with every component. As the following equation shows, the variance of the matrix increases with every component, while the residual variance in matrix must decrease.
This holds for any model where the and matrices are completely orthogonal to each other: (a matrix of zeros), such as in PCA, PLS and least squares models.
There comes a point for any real data set where the number of components, = the number of columns in and , extracts all systematic variance from , leaving unstructured residual variance in . Fitting any further components will start to fit this noise, and unstructured variance, in .
Cross-validation for multivariate data sets was described by Svante Wold in his paper on Cross-validatory estimation of the number of components in factor and principal components models, in Technometrics, 20, 397-405, 1978.
The general idea is to divide the matrix into groups of rows. These rows should be selected randomly, but are often selected in order: row 1 goes in group 1, row 2 goes in group 2, and so on. We can collect the rows belonging to the first group into a new matrix called , and leave behind all the other rows from all other groups, which we will call group . So in general, for the group, we can split matrix into and .
Wold’s cross-validation procedure asks to build the PCA model on the data in using components. Then use data in as new, testing data. In other words, we preprocess the rows, calculate their score values, , calculate their predicted values, , and their residuals, . We repeat this process, building the model on and testing it with , to eventually obtain .
After repeating this on groups, we gather up and assemble a type of residual matrix, , where the represents the number of components used in each of the PCA models. The subscript indicates that this is not the usual error matrix, . From this we can calculate a type of value. We don’t call this , but it follows the same definition for an value. We will call it instead, where is the number of components used to fit the models.
We also calculate the usual PCA model on all the rows of using components, then calculate the usual residual matrix, . This model’s value is:
The behaves exactly as , but with two important differences. Like , it is a number less than 1.0 that indicates how well the testing data, in this case testing data that was generated by the cross-validation procedure, are explained by the model. The first difference is that is always less than the value. The other difference is that will not keep increasing with each successive component, it will, after a certain number of components, start to decrease. This decrease in indicates the new component just added is not systematic: it is unable to explain the cross-validated testing data. We often see plots such as this one:
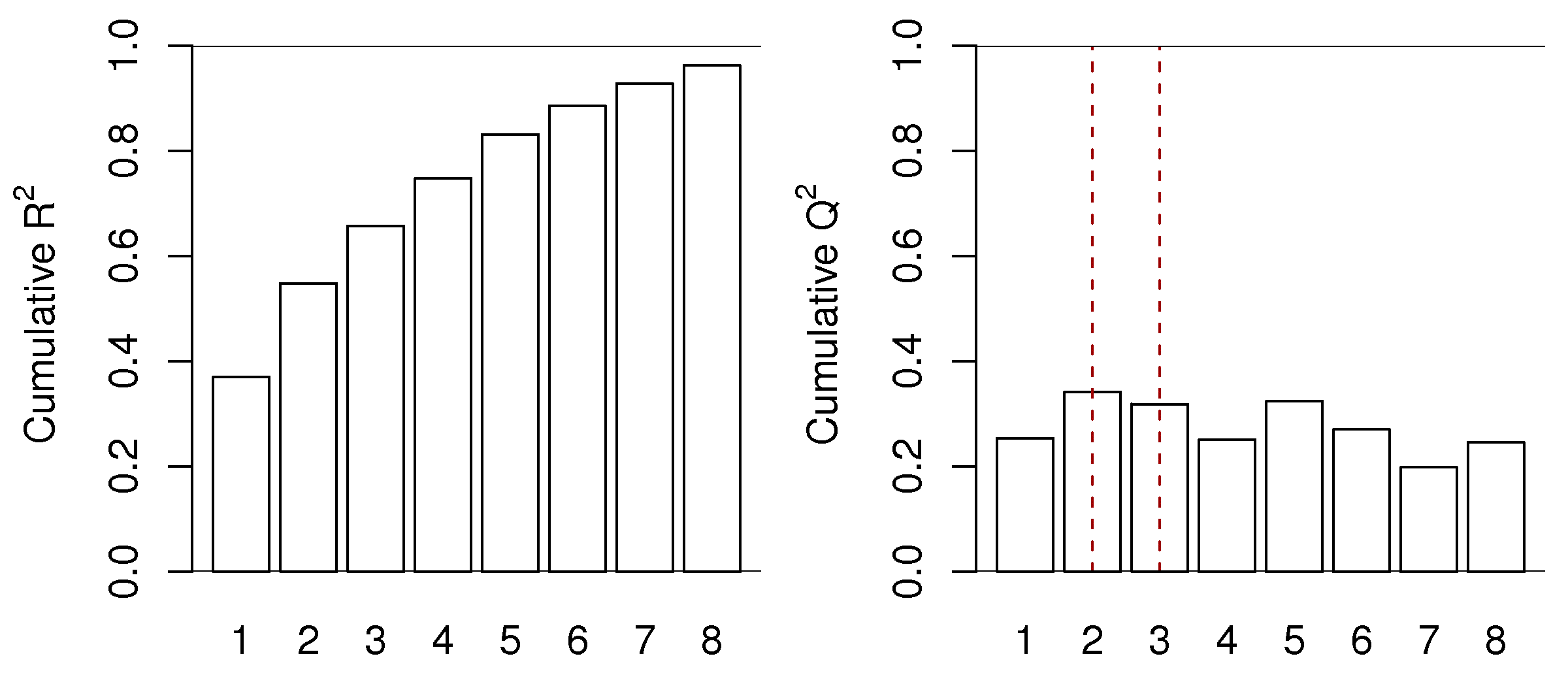
This is for a real data set, so the actual cut off for the number of components could be either or , depending on what the 3rd component shows to the user and how interested they are in that component. Likely the 4th component, while boosting the value from 66% to 75%, is not really fitting any systematic variation. The value drops from 32% to 25% when going from component 3 to 4. The fifth component shows increasing again. Whether this is fitting actual variability in the data or noise is for the modeller to determine, by investigating that 5th component. These plots show that for this data set we would use between 2 and 5 components, but not more.
Cross-validation, as this example shows is never a precise answer to the number of components that should be retained when trying to learn more about a dataset. Many studies try to find the “true” or “best” number of components. This is a fruitless exercise; each data set means something different to the modeller and the objective for which the model was intended to assist.
The number of components to use should be judged by the relevance of each component. Use cross-validation as guide, and always look at a few extra components and step back a few components; then make a judgement that is relevant to your intended use of the model.
However, cross-validation’s objective is useful for predictive models, such as PLS, so we avoid over-fitting components. Models where we intend to learn from, or optimize, or monitor a process may well benefit from fewer or more components than suggested by cross-validation.