2.8. Normal distribution¶
Before introducing the normal distribution, we first look at two important concepts: the Central limit theorem, and the concept of independence. Both concepts are used in important derivations, based on the normal distribution.
2.8.1. Central limit theorem¶
The Central limit theorem plays an important role in the theory of probability and in the derivation of the normal distribution. We don’t prove this theorem here, but we only use the result that:
The average of a sequence of values from any distribution will approach the normal distribution, provided the original distribution has finite variance.
The condition of finite variance is true for almost all systems of practical interest.
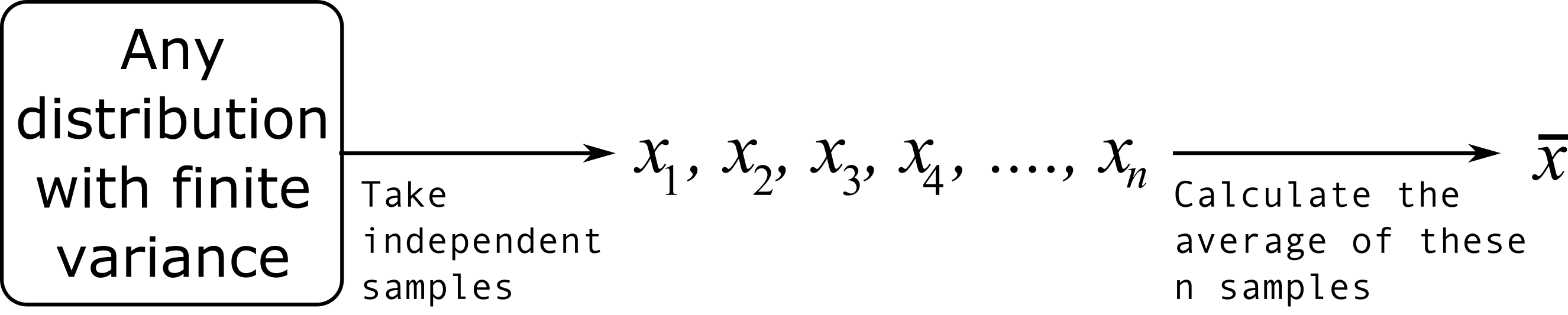
The critical requirement for the central limit theorem to be true is that the samples used to compute that average are independent of each together. The average produced from such samples will be more nearly normal though. Note: we do not require the original data to be normally distributed. This is a common misconception though.
Imagine a case where we are throwing dice. The distributions, shown below, are obtained when we throw a die
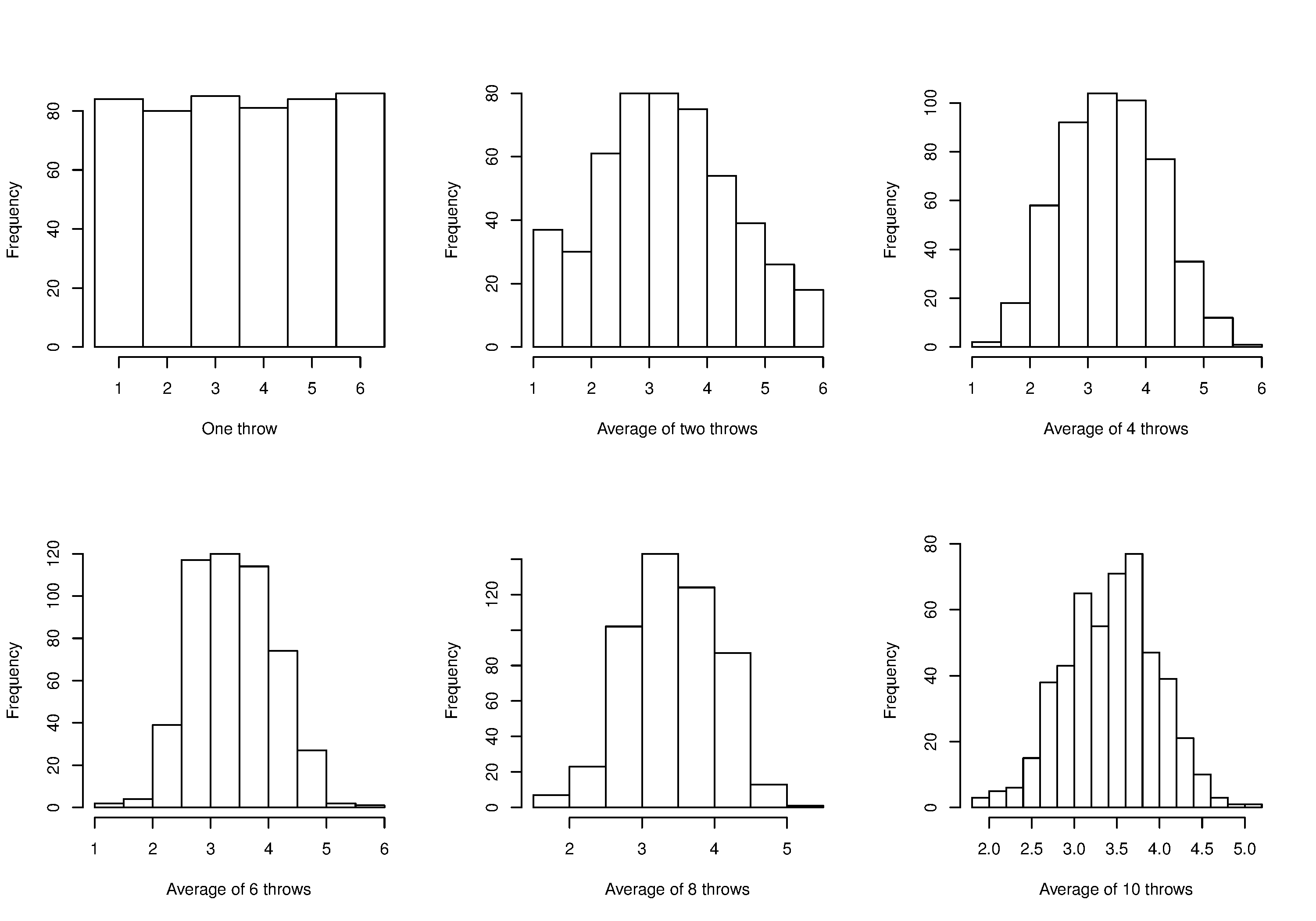
As one sees from the above figures, the distribution from these averages quickly takes the shape of the so-called normal distribution. As
What is the engineering significance of this averaging process (which is really just a weighted sum)? Many of the quantities we measure are bulk properties, such as viscosity, density, or particle size. We can conceptually imagine that the bulk property measured is the combination of the same property, measured on smaller and smaller components. Even if the value measured on the smaller component is not normally distributed, the bulk property will be as if it came from a normal distribution.
2.8.2. Independence¶
The assumption of independence is widely used in statistical work and is a condition for using the central limit theorem.
Note
The assumption of independence means that the samples we have in front of us are randomly taken from a population. If two samples are independent, there is no possible relationship between them.
We frequently violate this assumption of independence in engineering applications. Think about these examples for a while:
A questionnaire is given to a group of people. What happens if they discuss the questionnaire in sub-groups prior to handing it in?
We are not going to receive
The rainfall amount, recorded every day, over the last 30 days.
These data are not independent: if it rains today, it can likely rain tomorrow as the weather usually stays around for some days. These data are not useful as a representative sample of typical rainfall, however they are useful for complaining about the weather. Think about the case if we had considered rainfall in hourly intervals, rather than daily intervals.
The snowfall, recorded on 3 January for every year since 1976: independent or not?
These sampled data will be independent.
The impurity values in the last 100 batches of product produced is shown below. Which of the 3 time sequences has independent values?
In chemical processes there is often a transfer from batch-to-batch: we usually use the same lot of raw materials for successive batches, the batch reactor may not have been cleaned properly between each run, and so on. It is very likely that two successive batches (
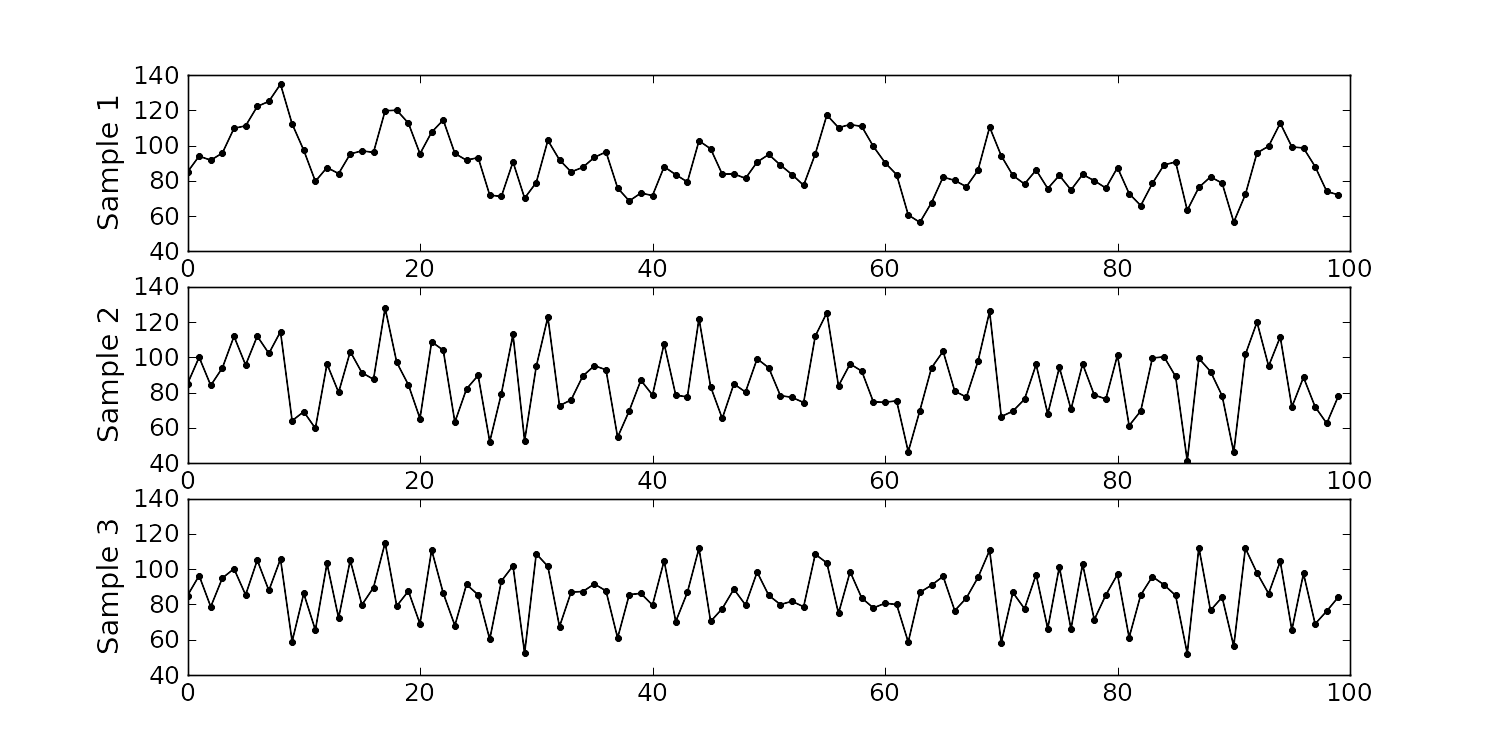
Sequence 2 (sequence 1 is positively correlated, while sequence 3 is negatively correlated).
We need a highly reliable pressure release system. Manufacturer A sells a system that fails 1 in every 100 occasions, and manufacturer B sells a system that fails 3 times in every 1000 occasions. Given this information, answer the following:
The probability that system A fails:
The probability that system B fails:
The probability that both system A and fail at the same time:
For the previous question, what does it mean for system A to be totally independent of system B?
It means the 2 systems must be installed in parallel, so that there is no interaction between them at all.
How would the probability of both A and B failing simultaneously change if A and B were not independent?
The probability of both failing simultaneously will increase.
2.8.3. Formal definition for the normal distribution¶
Some questions:
What is the maximum value of
What happens to the shape of
What happens to the shape of
Fill out this table:
0
1
0
1
1
0
-1
1
0
To calculate the point on the curve dnorm(...) function in R. It requires you specify the two parameters:
Some useful points:
The total area from
to is 1.0; we cannot calculate the integral of analytically.
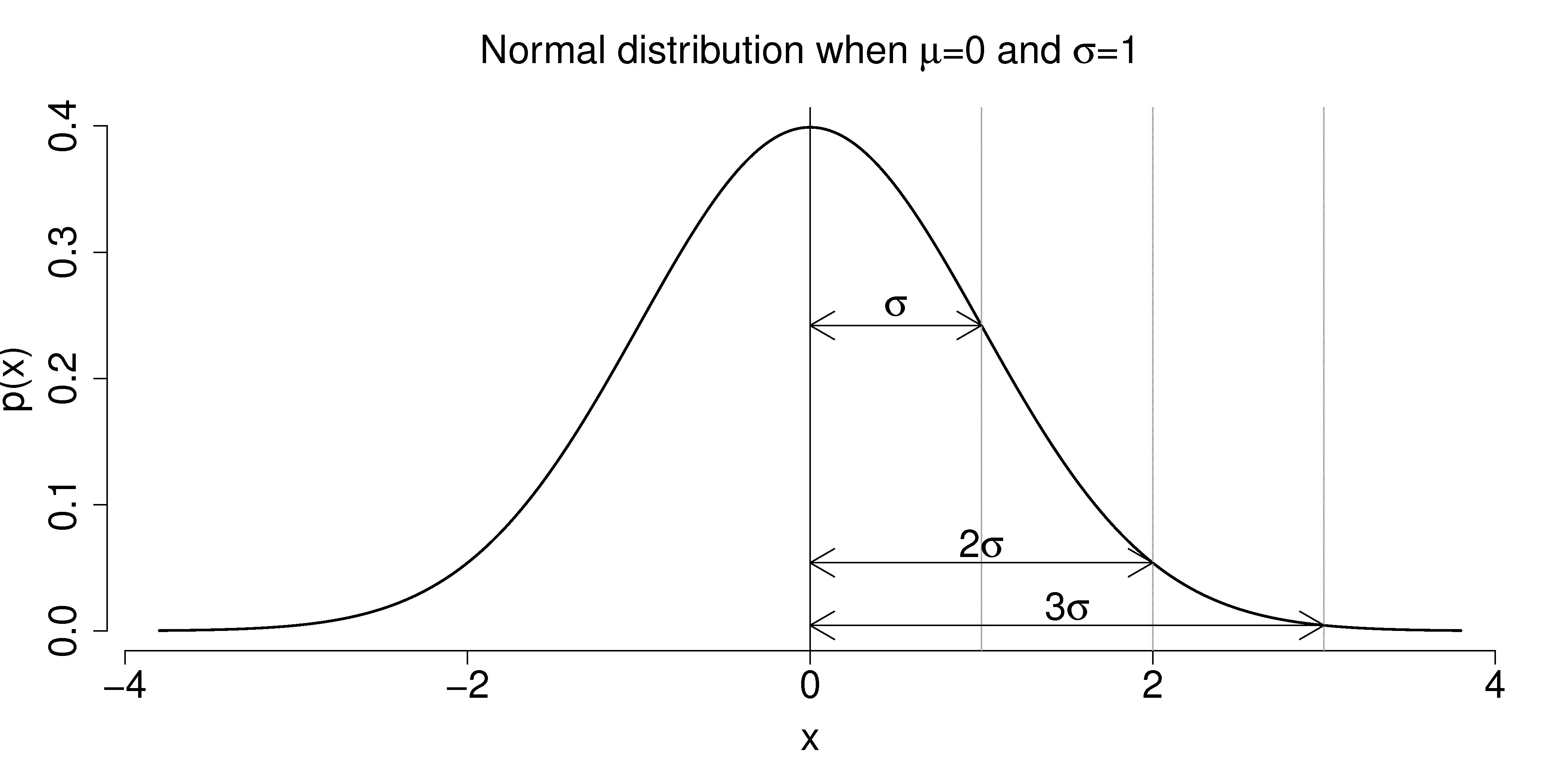
is the distance from the mean, , to the point of inflection The normal distribution only requires two parameters to describe it:
and The area from
to is about 70% (68.3% exactly) of the distribution. So we have a probability of about 15% of seeing an value greater than , and also 15% of The tail area outside
is about 5% (2.275 outside each tail)
It is more useful to calculate the area under
You might still find yourself having to refer to tables of cumulative area under the normal distribution, instead of using the pnorm() function (for example in a test or exam). If you look at the appendix of most statistical texts you will find these tables, and there is one at the end of this chapter. Since these tables cannot be produced for all combinations of mean and standard deviation parameters, they use what is called standard form.
The values of the mean and standard deviation are either the population parameters, if known, or using the best estimate of the mean and standard deviation from the sampled data.
For example, if our values of
This transformation to standard form does not change the distribution of the original
This is a common statistical technique, to standardize a variable, which we will see several times. Standardization takes our variable from
The units of
Consult a statistical table found in most statistical textbooks for the normal distribution, such as the one found at the end of this chapter. Make sure you can firstly understand how to read the table. Secondly, duplicate a few entries in the table using R. Complete these small exercises by estimating what the rough answer should be. Use the tables first, then use R to get a more accurate estimate.
Assume
Assume
2.8.4. Checking for normality: using a q-q plot¶
Often we are not sure if a sample of data can be assumed to be normally distributed. This section shows you how to test whether the data are normally distributed, or not.
Before we look at this method, we need to introduce the concept of the inverse cumulative distribution function (inverse CDF). Recall the cumulative distribution is the area underneath the distribution function, pnorm() function in R to verify that.
Now the inverse cumulative distribution is used when we know the area, but want to get back to the value along the qnorm(0.95, mean=0, sd=1) to calculate this value. The q stands for quantile, because we give it the quantile and it returns the qnorm(0.5) gives 0.0.
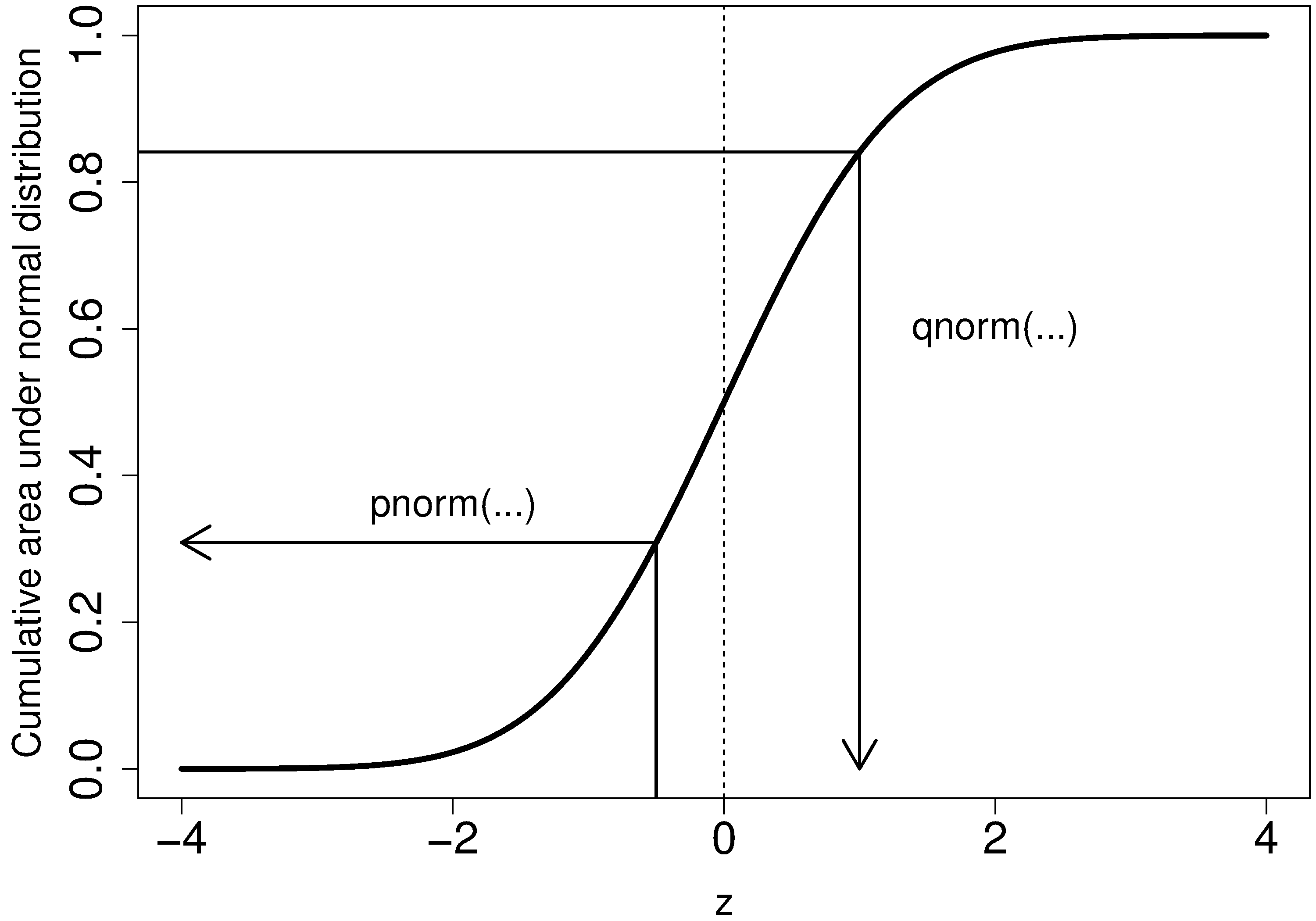
On to checking for normality. We start by first constructing some quantities that we would expect for truly normally distributed data. Secondly, we construct the same quantities for the actual data. A plot of these 2 quantities against each other will reveal if the data are normal, or not.
Imagine we have
The middle, sorted data point from this truly normal distribution must have a
qnorm(0.5)). By definition, 50% of the data should lie below this mid point. The first data point will be atqnorm(1/N), the second atqnorm(2/N), the middle data point atqnorm(0.5), and so on. In general, theqnorm((i-0.5)/N), for values ofqnorm(1.0) = Inf. So we construct this vector of theoretically expected quantities from the inverse cumulative distribution function.N = 10 index = seq(1, N) P = (index - 0.5) / N P [1] 0.05 0.15 0.25 0.35 0.45 0.55 0.65 0.75 0.85 0.95 theoretical.quantity = qnorm(P) [1] -1.64 -1.04 -0.674 -0.385 -0.126 0.125 0.385 0.6744 1.036 1.64
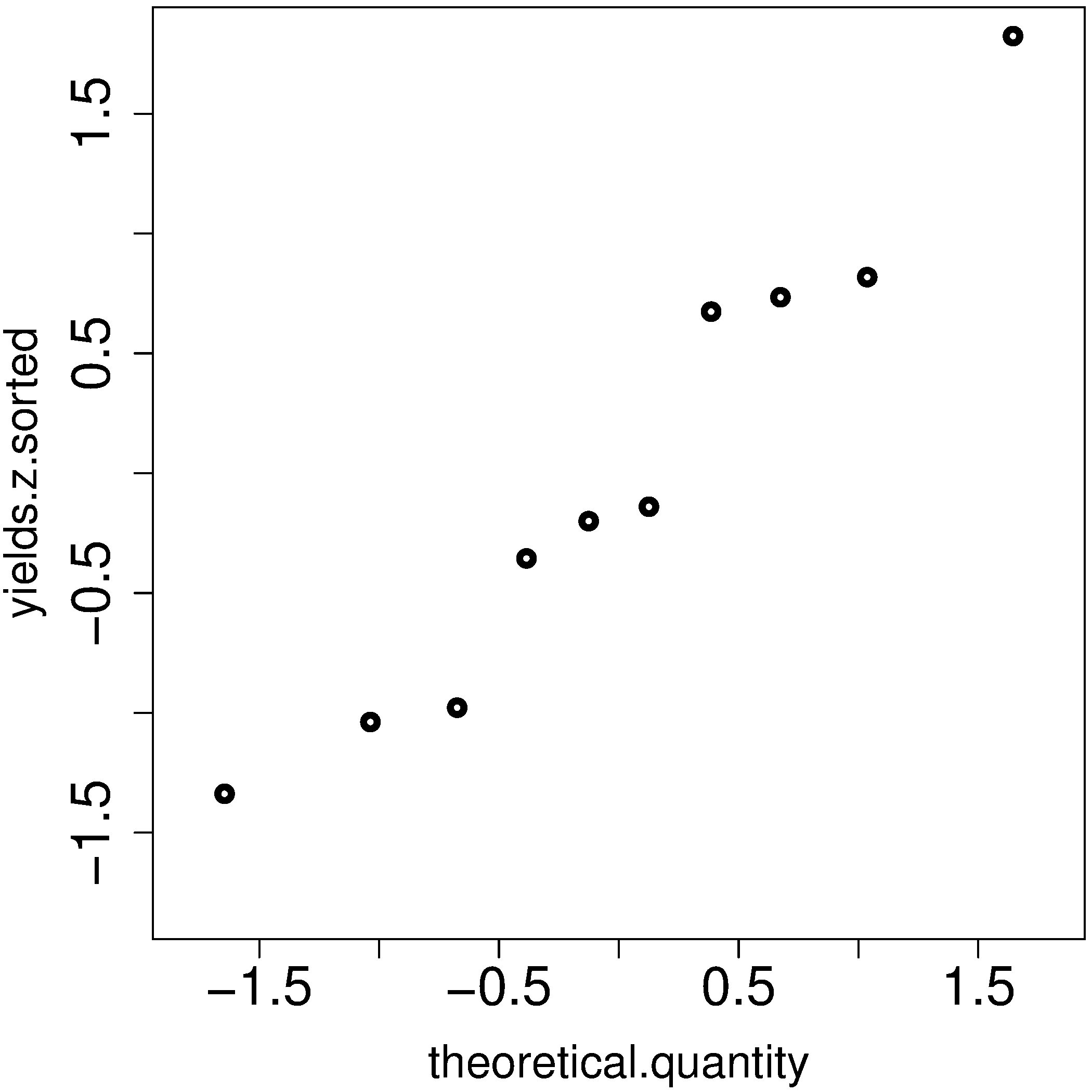
We also construct the actual quantiles for the sampled data. First, standardize the sampled data by subtracting off its mean and dividing by its standard deviation. Here is an example of 10 batch yields (see actual values below). The mean yield is 80.0 and the standard deviation is 8.35. The standardized yields are found by subtracting off the mean and dividing by the standard deviation. Then the standardized values are sorted. Compare them to the theoretical quantities.
yields <- c(86.2, 85.7, 71.9, 95.3, 77.1, 71.4, 68.9, 78.9, 86.9, 78.4) mean.yield <- mean(yields) # 80.0 sd.yield <- sd(yields) # 8.35 yields.z = (yields - mean.yield)/sd.yield [1] 0.734 0.674 -0.978 1.82 -0.35 -1.04 -1.34 -0.140 0.818 -0.200 yields.z.sorted = sort(yields.z) [1] -1.34 -1.04 -0.978 -0.355 -0.200 -0.140 0.674 0.734 0.818 1.82 theoretical.quantity # numbers are rounded in the printed output [1] -1.64 -1.04 -0.674 -0.385 -0.126 0.125 0.385 0.6744 1.036 1.64
The final step is to plot this data in a suitable way. If the sampled quantities match the theoretical quantities, then a scatter plot of these numbers should form a 45 degree line.
plot(theoretical.quantity, yields.z.sorted, type="p")
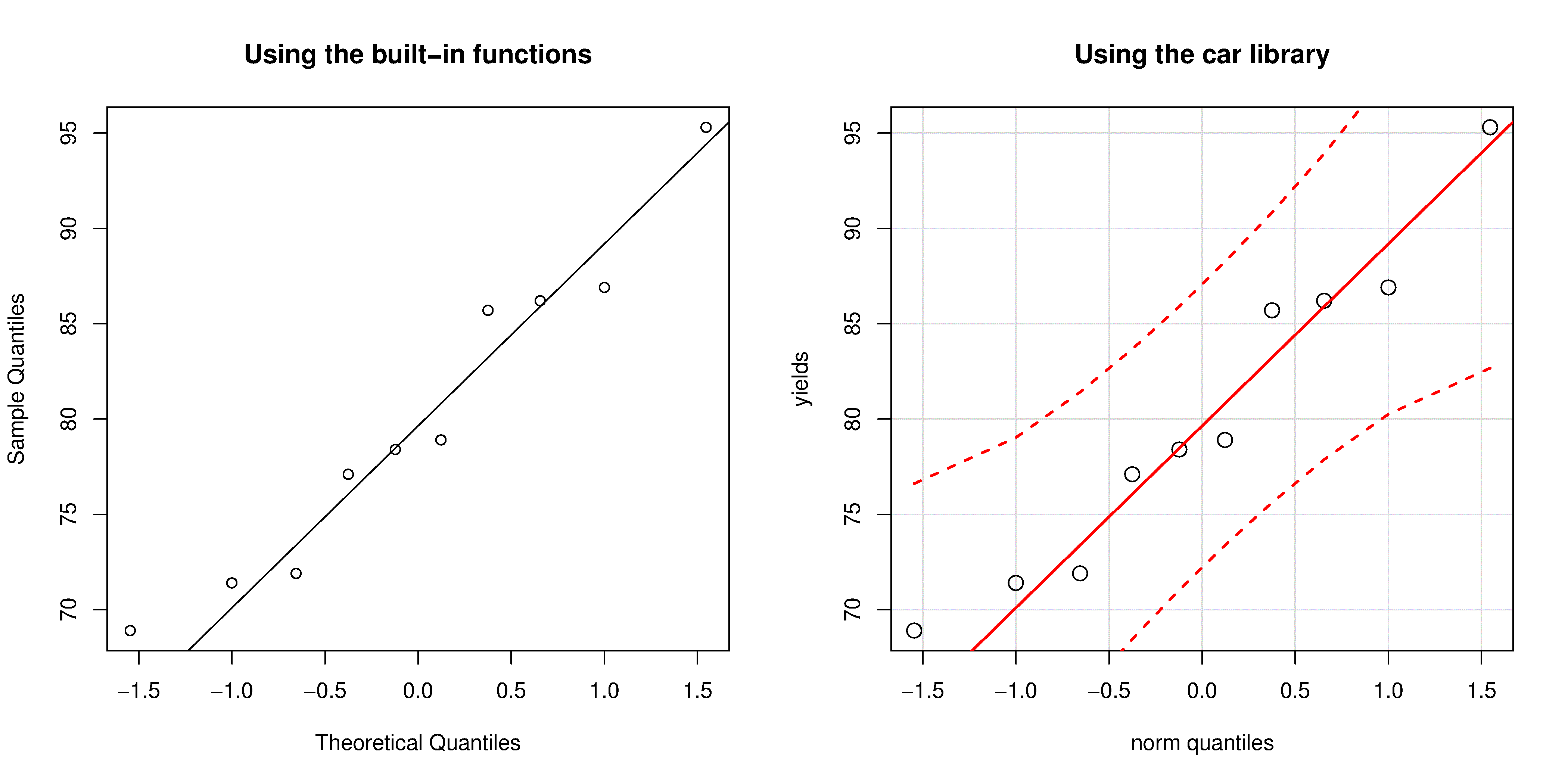
A built-in function exists in R that runs the above calculations and shows a scatter plot. The 45 degree line is added using the qqline(...) function. However, a better function that adds a confidence limit envelope is included in the car library (see the Package Installer menu in R for adding libraries from the internet).
qqnorm(yields)
qqline(yields)
# or, using the ``car`` library
library(car)
qqPlot(yields)
All the above code together in one script for you to test out:
The R plot rescales the
The q-q plot, quantile-quantile plot, shows the quantiles of 2 distributions against each other. In fact, we can use the horizontal axis for any distribution, it need not be the theoretical normal distribution. We might be interested if our data follow an
We can use the q-q plot to compare any 2 samples of data, even if they have different values of quantile function in R. The simple example below shows how to compare the q-q plot for 1000 normal distribution samples against 2000
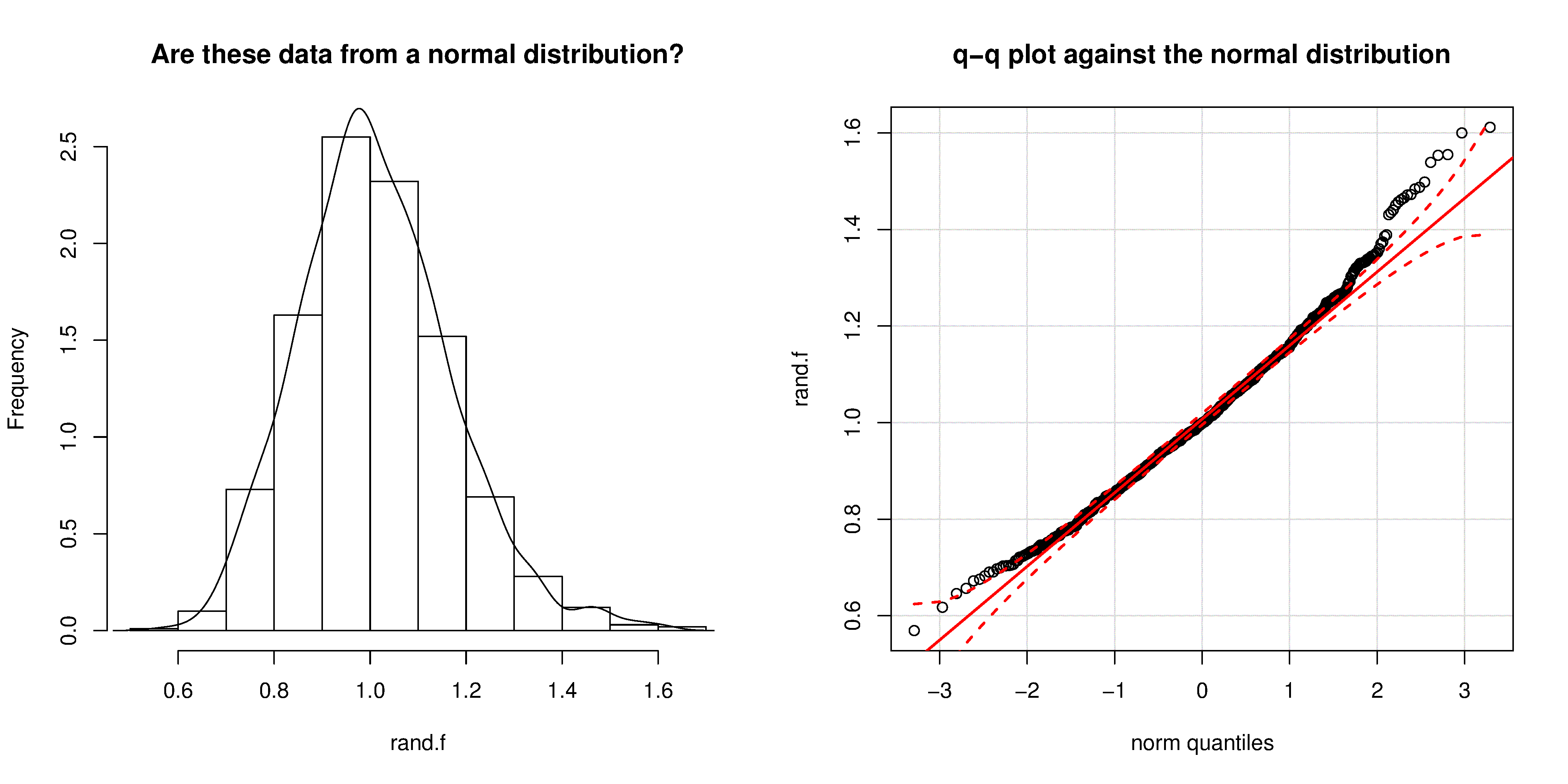
Even though the histogram of the
2.8.5. Introduction to confidence intervals from the normal distribution¶
We introduce the concept of confidence intervals here as a straightforward application of the normal distribution, Central limit theorem, and standardization.
Suppose we have a quantity of interest from a process, such as the daily profit. We have many measurements of this profit, and we can easily calculate the average profit. But we know that if we take a different data set of profit values and calculate the average, we will get a similar, but different average. Since we will never know the true population average, the question we want to answer is:
What is the range within which the true (population) average value lies? E.g. give a range for the true, but unknown, daily profit.
This range is called a confidence interval, and we study them in more depth later on. We will use an example to show how to calculate this range.
Let’s take
An estimate of the population mean is given by
The estimated population variance is
This is new: the estimated mean,
Mathematically we write:
This important result helps answer our question above. It says that repeated estimates of the mean will be an accurate, unbiased estimate of the population mean, and interestingly, the variance of that estimate is decreased by using a greater number of samples,
We can illustrate this result as shown below:
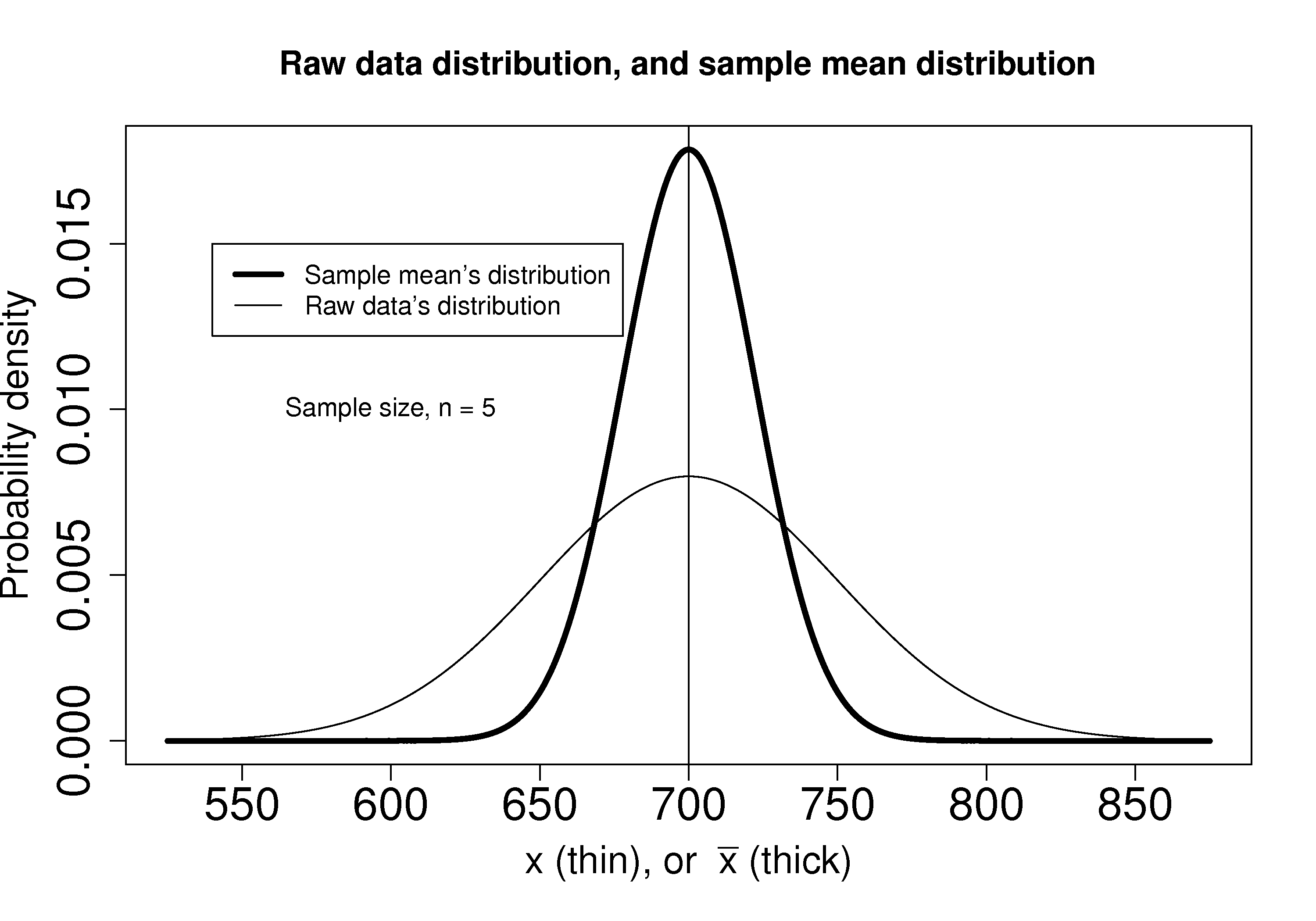
The true population (but unknown to us) profit value is $700.
The 5 samples come from the distribution given by the thinner line:
The
Creating
The
which subtracts off the unknown population mean from our estimate of the mean, and divides through by the standard deviation for
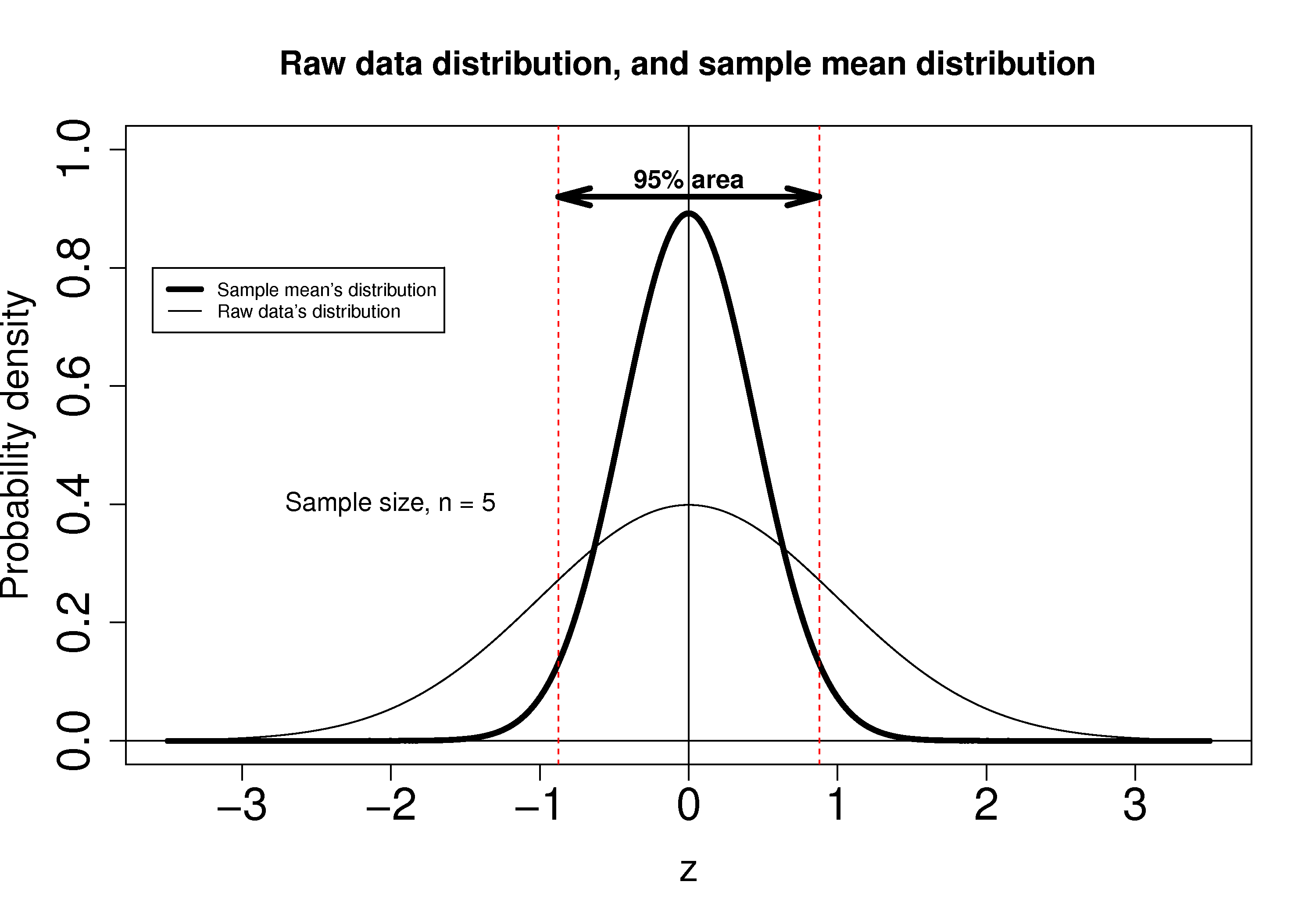
Using the known normal distribution for
These vertical lines are symmetrical about 0, and we will call them
qnorm(1 - 0.05/2), so that there is 2.5% area in each tail.Finally, we construct an interval for the true population mean,
Notice that the lower and upper bound are a function of the known sample mean,
So to estimate our bounds we must know the value of this population standard deviation. This is not very likely, (I can’t think of any practical cases where we know the population standard deviation, but not the population mean, which is the quantity we are constructing this range for), however there is a hypothetical example in the next section to illustrate the calculations.
The