6.5.11. PCA example: analysis of spectral data
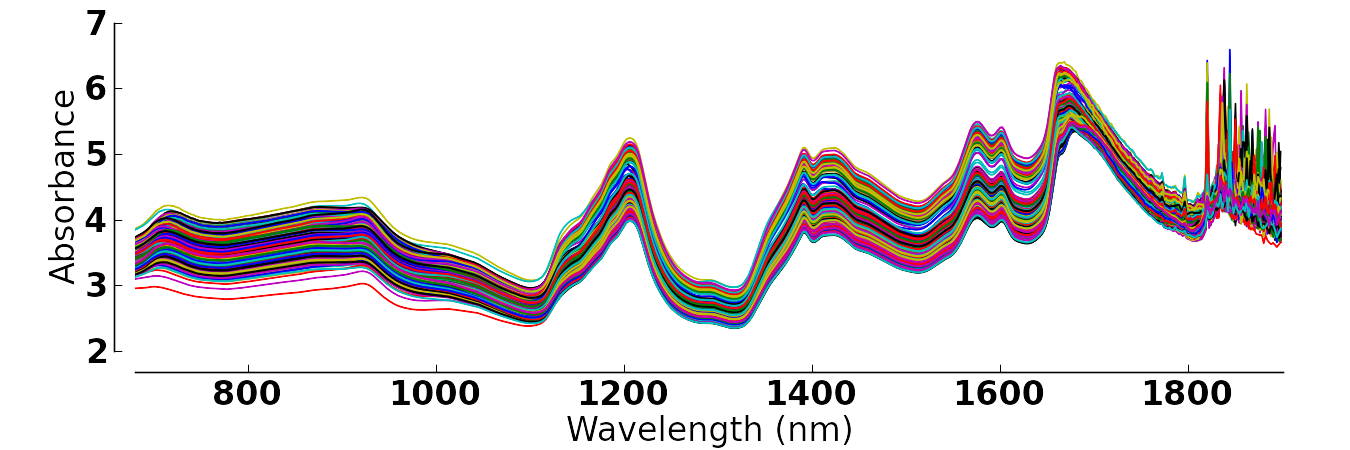
A data set, available on the dataset website, contains data on 460 tablets, measured at 650 different wavelengths.
This R code will calculate principal components for this data:
which gives this output:
Importance of first k=4 (out of 460) components:
PC1 PC2 PC3 PC4
Standard deviation 21.8835 10.9748 3.60075 3.27081
Proportion of Variance 0.7368 0.1853 0.01995 0.01646
Cumulative Proportion 0.7368 0.9221 0.94200 0.95846
The (Cumulative Proportion) values shows the first component explains 73.7% of the variability in , the second explains an additional 18.5% for a cumulative total of 92.2%, and the third component explains an additional 1.99%. These three components together explain 94.2% of all the variation in . This means we have reduced from a matrix to a matrix of scores, , and a matrix of loadings, . This is a large reduction in data size, with a minimal loss of information.
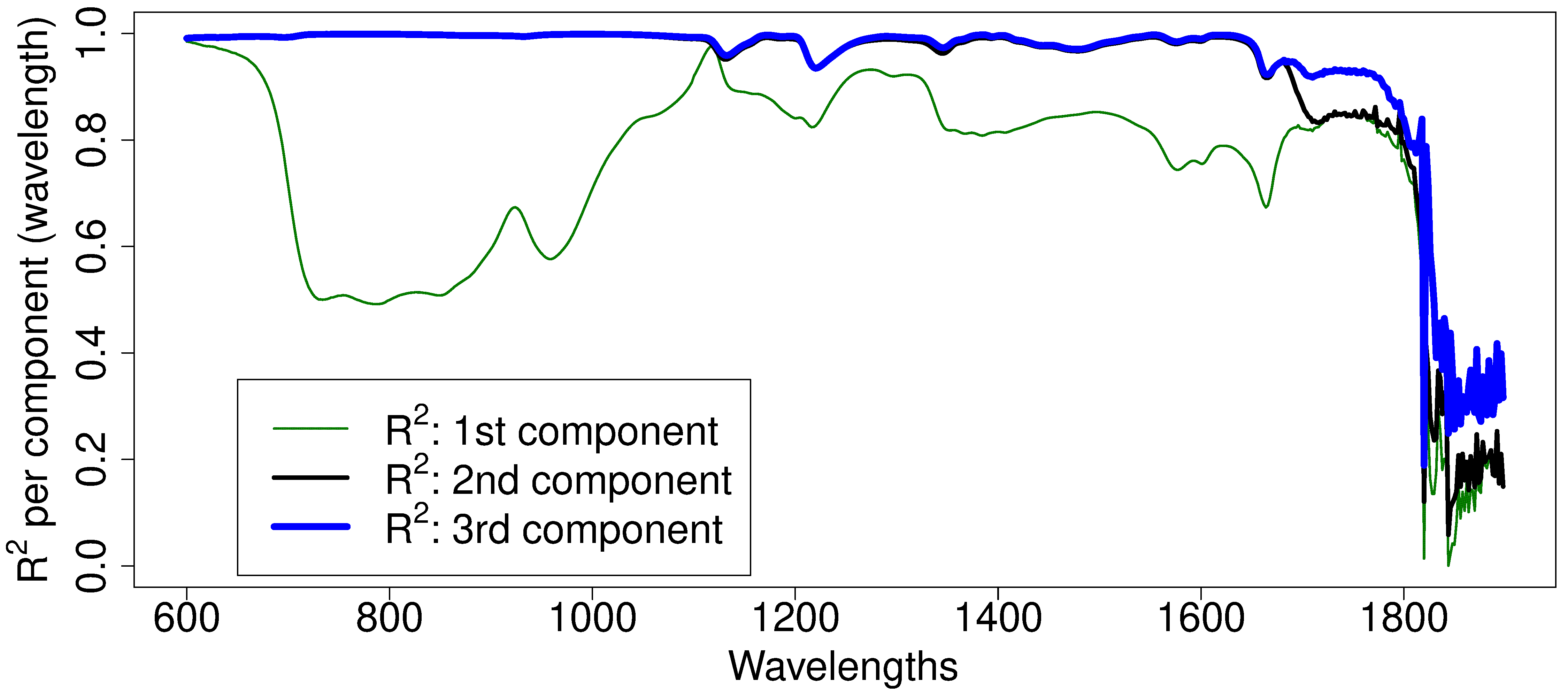
Let’s visually show what the values are for each column. Shown below are these values for the first 3 components. The first component (green, thin line) explains certain regions of the spectra very well, particularly the region around 1100nm. Wavelengths beyond 1800 nm are not well explained at all. The second component is primarily responsible for explaining additional variability in the 700 to 1100nm region. The third component only seems to explain the additional variability from 1700 to 1800nm. Fitting a fourth component is only going to start fitting the noisy regions of the spectrum on the very right. For these data we could use 2 components for most applications, or perhaps 3 if the region between 1700 and 1800nm was also important.
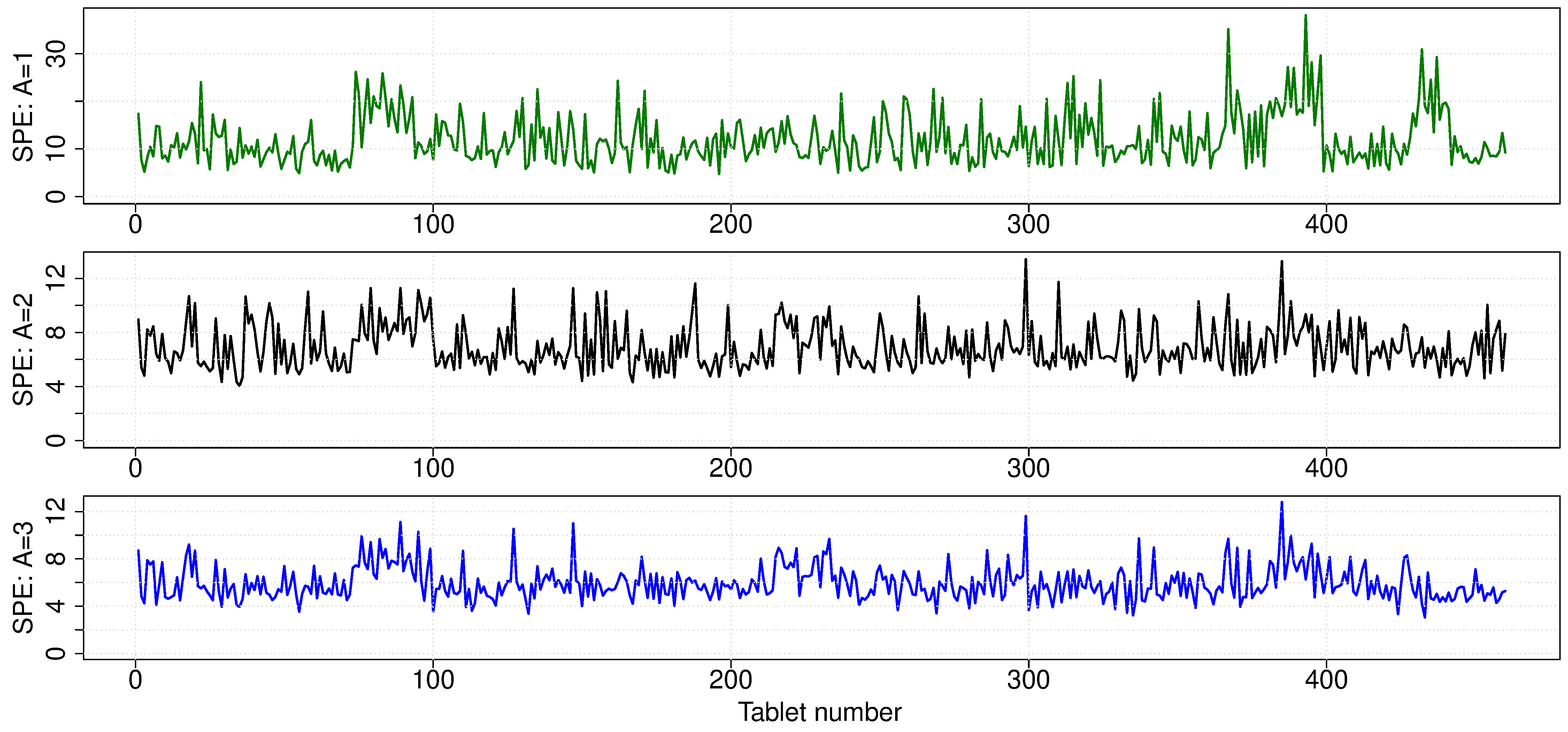
Finally, we can show the SPE plot for each observation. SPE values for each tablet become smaller and smaller as each successive component is added. Since each new component explains additional variance, the size of SPE must decrease. There don’t appear to be any major outliers off the model’s plane after the first component.
The code for the above plots is: