4.8. Investigating an existing linear model¶
4.8.1. Summary so far¶
We have introduced the linear model,
Along the way, while investigating these assumptions, we will introduce some new topics:
Transformations of the raw data to better meet our assumptions
Leverage, outliers, influence and discrepancy of the observations
Inclusion of additional terms in the linear model (multiple linear regression, MLR)
The use of training and testing data
It is a common theme in any modelling work that the most informative plots are those of the residuals - the unmodelled component of our data. We expect to see no structure in the residuals, and since the human eye is excellent at spotting patterns in plots, it is no surprise that various types of residual plots are used to diagnose problems with our model.
4.8.2. The assumption of normally distributed errors¶
We look for normally distributed errors because if they are non-normal, then the standard error,
This is one of the easiest assumptions to verify: use a q-q plot to assess the distribution of the residuals. Do not plot the residuals in sequence or some other order to verify normality - it is extremely difficult to see that. A q-q plot highlights very clearly when tails from the residuals are too heavy. A histogram may also be used, but for real data sets, the choice of bin width can dramatically distort the interpretation - rather use a q-q plot. Some code for R:
model = lm(...)
library(car)
qqPlot(model) # uses studentized residuals
qqPlot(resid(model)) # uses raw residuals
If the residuals appear non-normal, then attempt the following:
Remove the outlying observation(s) in the tails, but only after careful investigation whether that outlier really was unusual
Use a suitable transformation of the y-variable
The simple example shown here builds a model that predicts the price of a used vehicle using only the mileage as an explanatory variable.
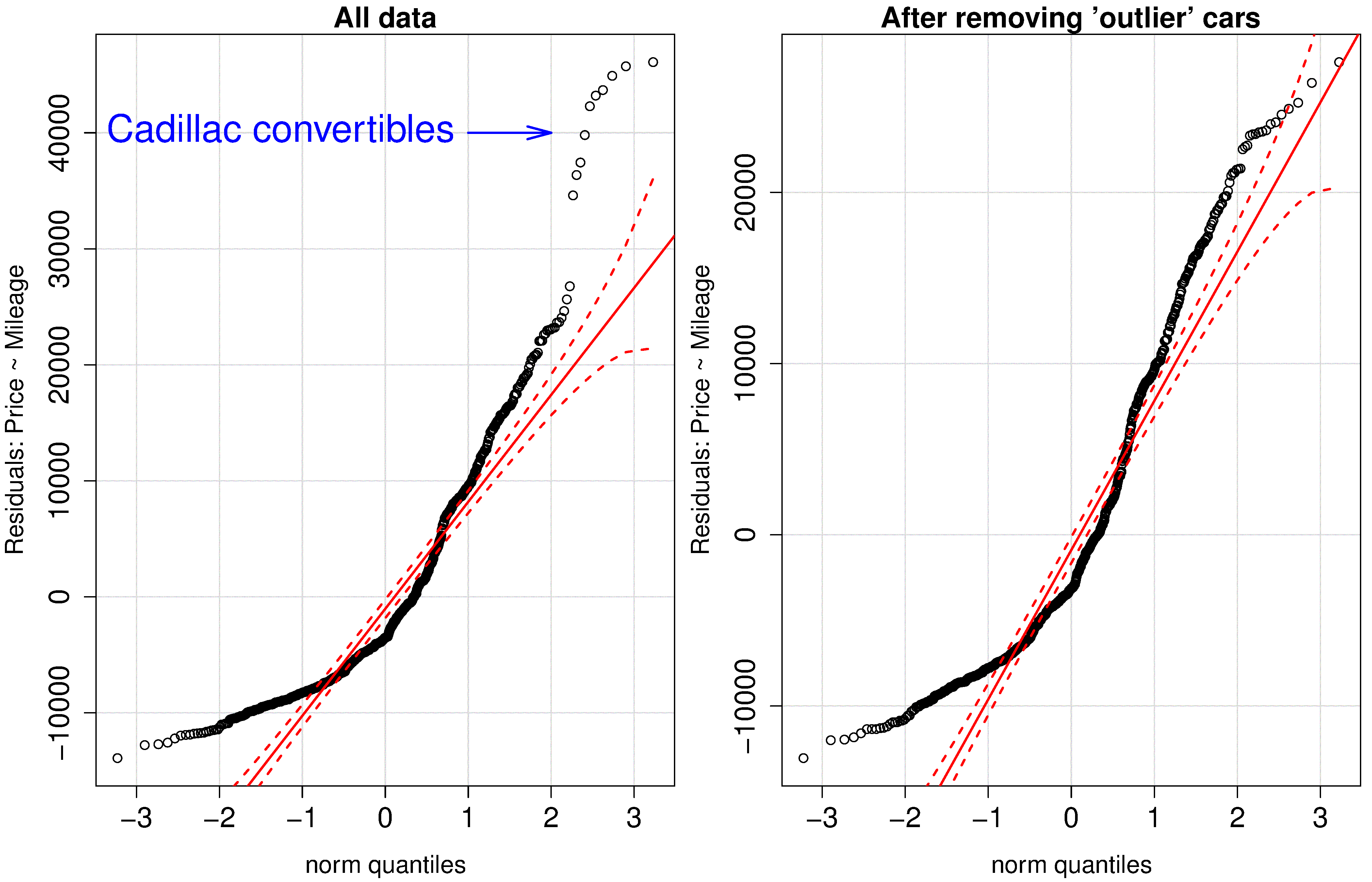
The group of outliers were due to 10 observations of a certain class of vehicle (Cadillac convertibles) that distorted the model. We removed these observations, which now limits our model to be useful only for other vehicle types, but we gain a smaller standard error and a tighter confidence interval. These residuals are still very non-normal though.
The slope coefficient (interpretation: each extra mile on the odometer reduces the sale price on average by 15 to 17 cents) has a tighter confidence interval after removing those unusual observations.
Removing the Cadillac cars from our model indicates that there is more than just mileage that affect their resale value. In fact, the lack of normality, and structure in the residuals leads us to ask which other explanatory variables can be included in the model.
In the next fictitious example the
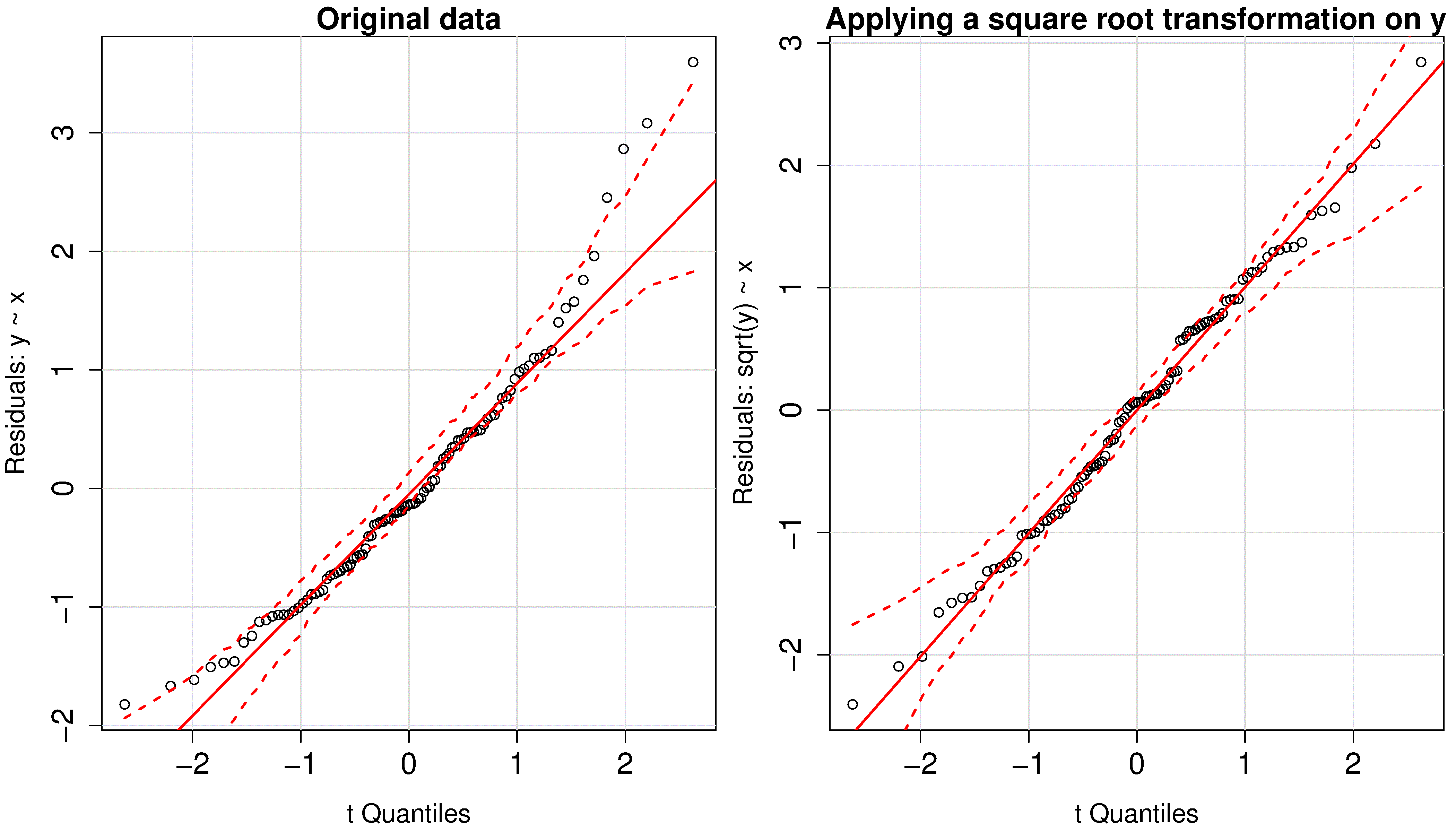
More discussion about transformations of the data is given in the section on model linearity.
4.8.3. Non-constant error variance¶
It is common in many situations that the variability in
Violating the assumption of non-constant error variance increases the standard error,
To detect this problem you should plot:
the predicted values of
(on the x-axis) against the residuals (y-axis) the
values against the residuals (y-axis)
This problem reveals itself by showing a fan shape across the plot; an example is shown in the figure.
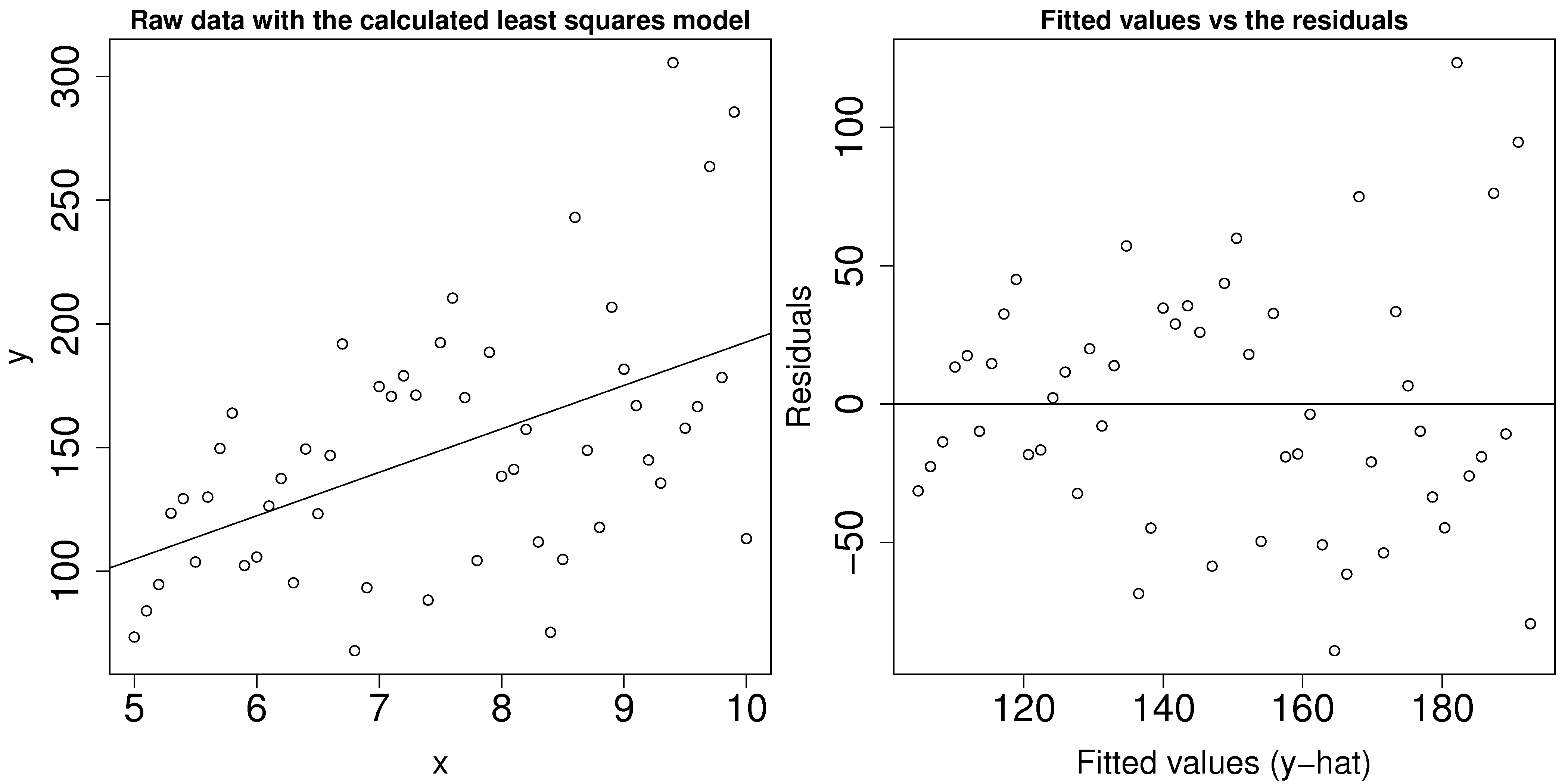
To counteract this problem one can use weighted least squares, with smaller weights on the high-variance observations, i.e. apply a weight inversely proportional to the variance. Weighted least squares minimizes:
4.8.4. Lack of independence in the data¶
The assumption of independence in the data requires that values in the
Data are not independent when they are correlated with each other. This is common on slow moving processes: for example, measurements taken from a large reactor are unlikely to change much from one minute to the next.
Treating this problem properly comes under the topic of time-series analysis, for which a number of excellent textbooks exist, in particular the one by Box and Jenkins. But we will show how to detect autocorrelation, and provide a make-shift solution to avoid it.
If you suspect that there may be lack of independence, use plots of the residuals in time order. Look for patterns such as slow drifts, or rapid criss-crossing of the zero axis.
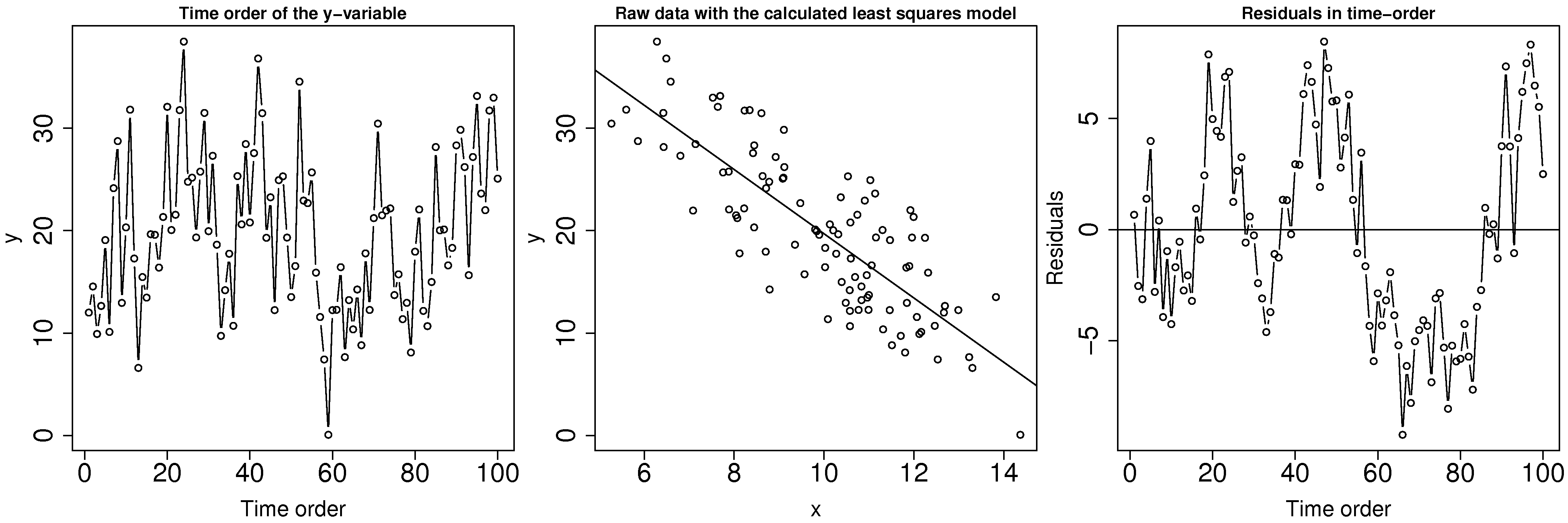
One way around the autocorrelation is to subsample - use only every acf(...) function in R, which will show how many significant lags there are between observations. Calculating the autocorrelation accurately requires a large data set, which is a requirement anyway if you need to subsample your data to obtain independence.
Here are some examples of the autocorrelation plot: in the first case you would have to leave at least 16 samples between each sub-sample, while the second and third cases require a gap of 1 sample, i.e. use only every second data point.

Another test for autocorrelation is the Durbin-Watson test. For more on this test see the book by Draper and Smith (Chapter 7, 3rd edition); in R you can use the durbinWatsonTest(model) function in library(car). Try generating autocorrelation of varying strength (positive, e.g. phi_long = 0.80 and negative, e.g. phi_long = -0.75) in the code below. Inspect the plots which are generated as a result, especially the time order plot: get a feeling for what a strong and weak positive/negative correlation looks like in the time order.
4.8.5. Linearity of the model (incorrect model specification)¶
Recall that the linear model is just a tool to either learn more about our data, or to make predictions. Many cases of practical interest are from systems where the general theory is either unknown, or too complex, or known to be non-linear.
Certain cases of non-linearity can be dealt with by simple transformations of the raw data: use a non-linear transformation of the raw data and then build a linear model as usual. An alternative method which fits the non-linear function, using concepts of optimization, by minimizing the sum of squares is covered in a section on non-linear regression. Again the book by Draper and Smith (Chapter 24, 3rd edition), may be consulted if this topic is of further interest to you. Let’s take a look at a few examples.
We saw earlier a case where a square-root transformation of the
When
goes from 1 and higher, say 1.5, 1.75, 2.0, etc, it compresses small values of and inflates larger values. When
goes down from 1, 0.5 ( ), 0.25, -0.5, -1.0 ( ), -1.5, -2.0, etc, it compresses large values of and inflates smaller values. The case of
approximates in terms of the severity of the transformation.
In other instances we may know from first-principles theory, or some other means, what the expected non-linear relationship is between an
In a distillation column the temperature,
is inversely proportional to the logarithm of the vapour pressure, . So fit a linear model, where and where . The slope coefficient will have a different interpretation and a different set of units as compared to the case when predicting vapour pressure directly from temperature. If
, then we can take logs and estimate this equivalent linear model: , which is of the form . So the slope coefficient will be an estimate of . If
, then invert both sides and estimate the model where , and . There are plenty of other examples, some classic cases being the non-linear models that arise during reactor design and biological growth rate models. With some ingenuity (taking logs, inverting the equation), these can often be simplified into linear models.
Some cases cannot be linearized and are best estimated by non-linear least squares methods. However, a make-shift approach which works quite well for simple cases is to perform a grid search. For example imagine the equation to fit is
, and you are given some data pairs . Then for example, create a set of trial values and . Build up a grid for each combination of and and calculate the sum of squares objective function for each point in the grid. By trial-and-error you can converge to an approximate value of and that best fit the data. You can then calculate , but not the confidence intervals for and .
Before launching into various transformations or non-linear least squares models, bear in mind that the linear model may be useful over the region of interest. In the figure we might only be concerned with using the model over the region shown, even though the system under observation is known to behave non-linearly over a wider region of operation.
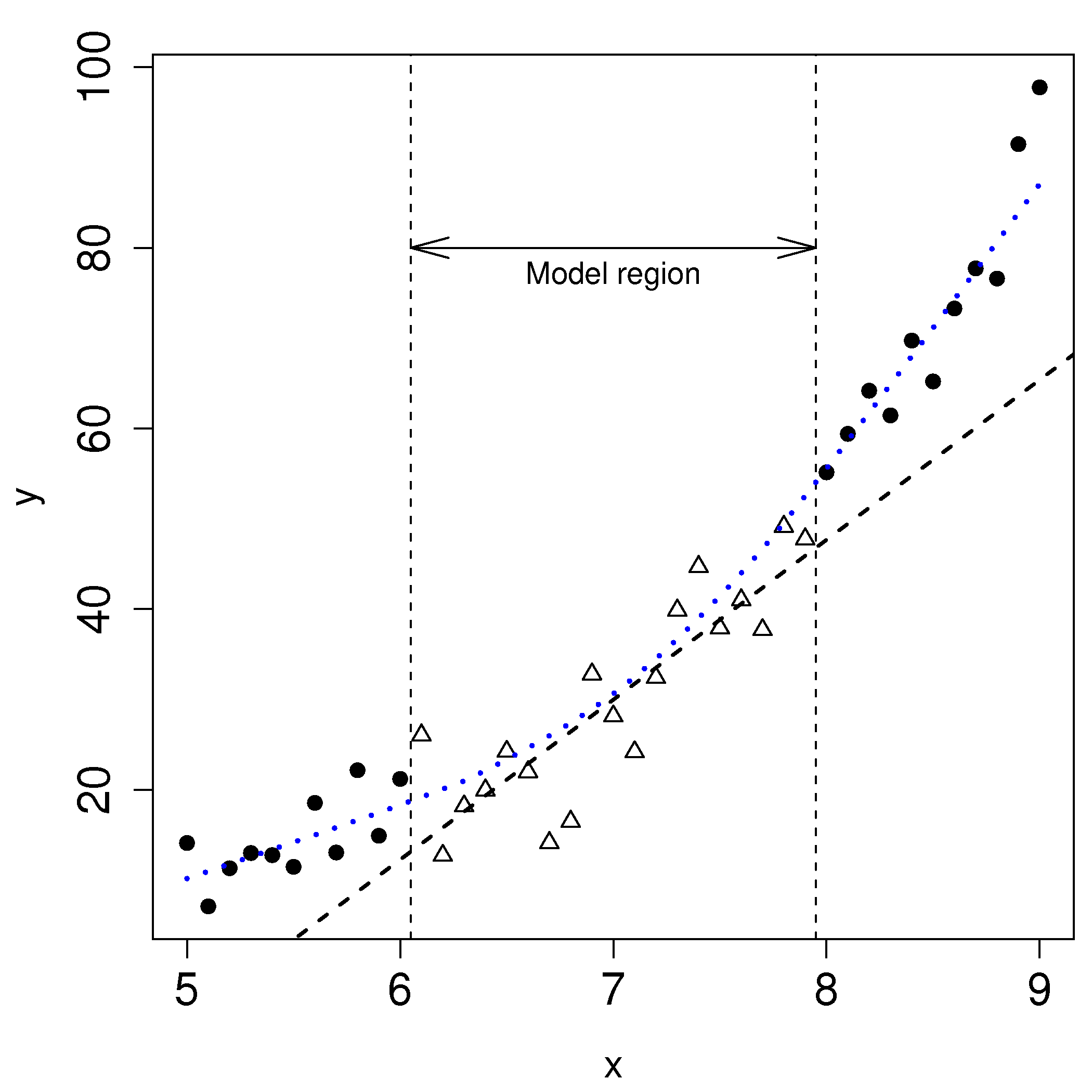
How can we detect when the linear model is not sufficient anymore? While a q-q plot might hint at problems, better plots are the same two plots for detecting non-constant error variance:
the predicted values of
(on the x-axis) against the residuals (y-axis) the
values against the residuals (y-axis)
Here we show both plots for the example just prior (where we used a linear model for a smaller sub-region). The last two plots look the same, because the predicted
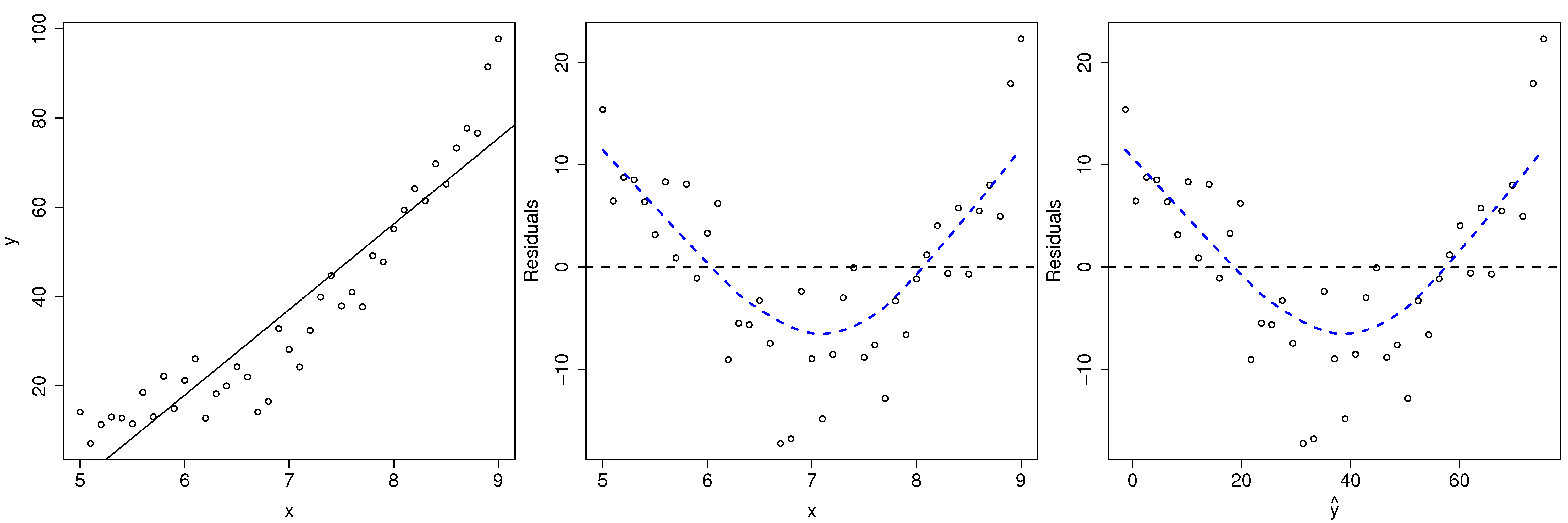
Transformations are considered successful once the residuals appear to have no more structure in them. Also bear in mind that structure in the residuals might indicate the model is missing an additional explanatory variable (see the section on multiple linear regression).
Another type of plot to diagnose non-linearity present in the linear model is called a component-plus-residual plot or a partial-residual plot. This is an advanced topic not covered here, but well covered in the Fox reference.