4.6. Least squares models with a single x-variable¶
The general linear least squares model is a very useful tool (in the right circumstances), and it is the workhorse for a number of algorithms in data analysis.
This part covers the relationship between two variables only:
We will follow these steps:
Model definition (this subsection)
Building the model
Interpretation of the model parameters and model outputs (coefficients,
Consider the effect of unusual and influential data
Assessment of model residuals
The least squares model postulates that there is a linear relationship between measurements in vector
The
We develop the least squares method to estimate these parameters; these estimates are defined as
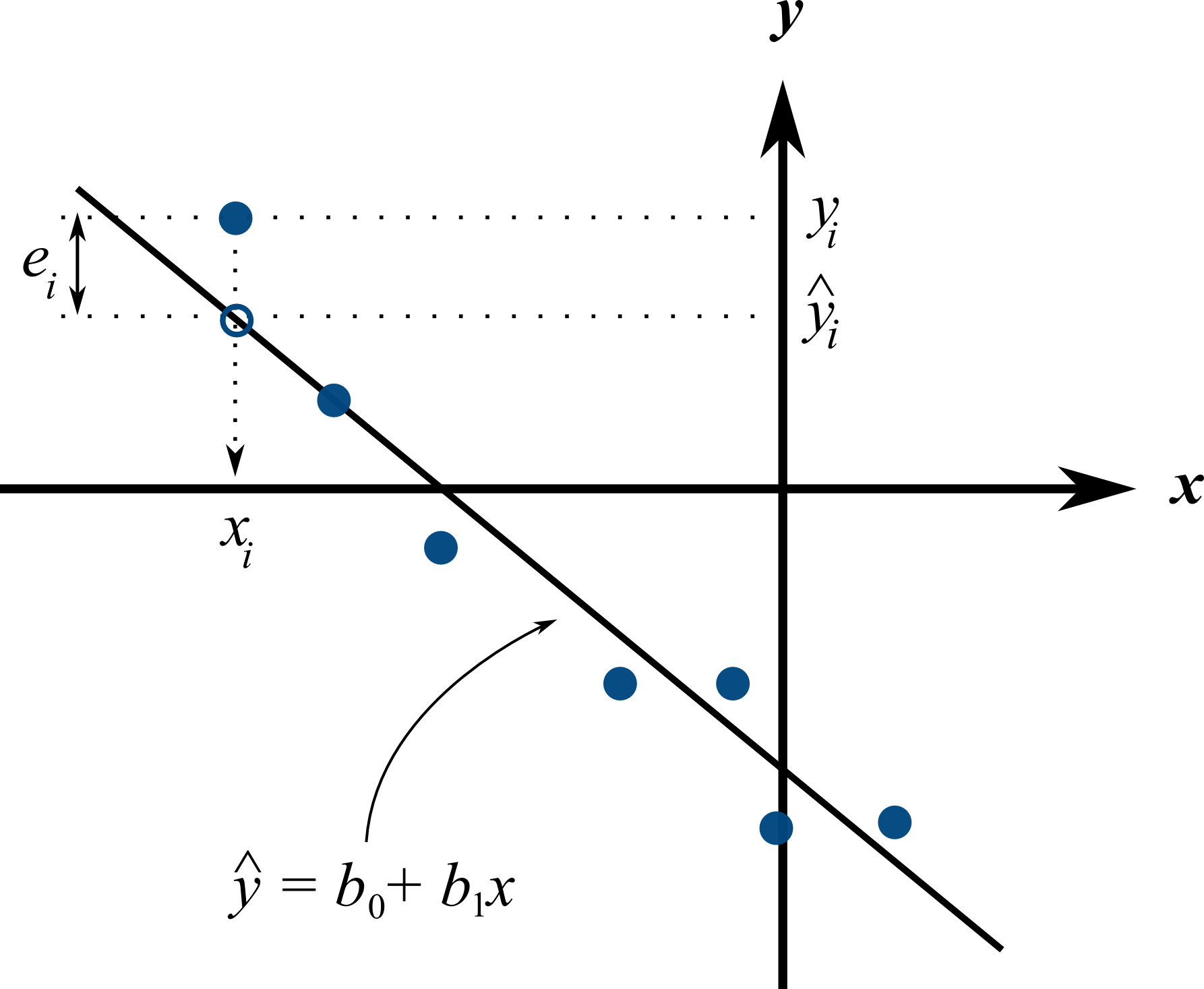
Presuming we have calculated estimates
4.6.1. Minimizing errors as an objective¶
Our immediate aim however is to calculate the
Here are some valid approaches, usually called objective functions for making the
, which leads to the least squares model
sum of perpendicular distances to the line
is known as the least absolute deviations model, or the -1 norm problem least median of squared error model, which a robust form of least squares that is far less sensitive to outliers.
The traditional least squares model, the first objective function listed, has the lowest possible variance for
Other reasons for so much focus on the least squares alternative is because it is computationally tractable by hand and very fast on computers, and it is easy to prove various mathematical properties. The other forms take much longer to calculate, almost always have to be done on a computer, may have multiple solutions, the solutions can change dramatically given small deviations in the data (unstable, high variance solutions), and the mathematical proofs are difficult. Also the interpretation of the least squares objective function is suitable in many situations: it penalizes deviations quadratically; i.e. large deviations much more than the smaller deviations.
You can read more about least squares alternatives in the book by Birkes and Dodge: “Alternative Methods of Regression”.
4.6.2. Solving the least squares problem and interpreting the model¶
Having settled on the least squares objective function, let’s construct the problem as an optimization problem and understand its characteristics.
The least squares problem can be posed as an unconstrained optimization problem:
Returning to our example of the gas cylinder. In this case we know that
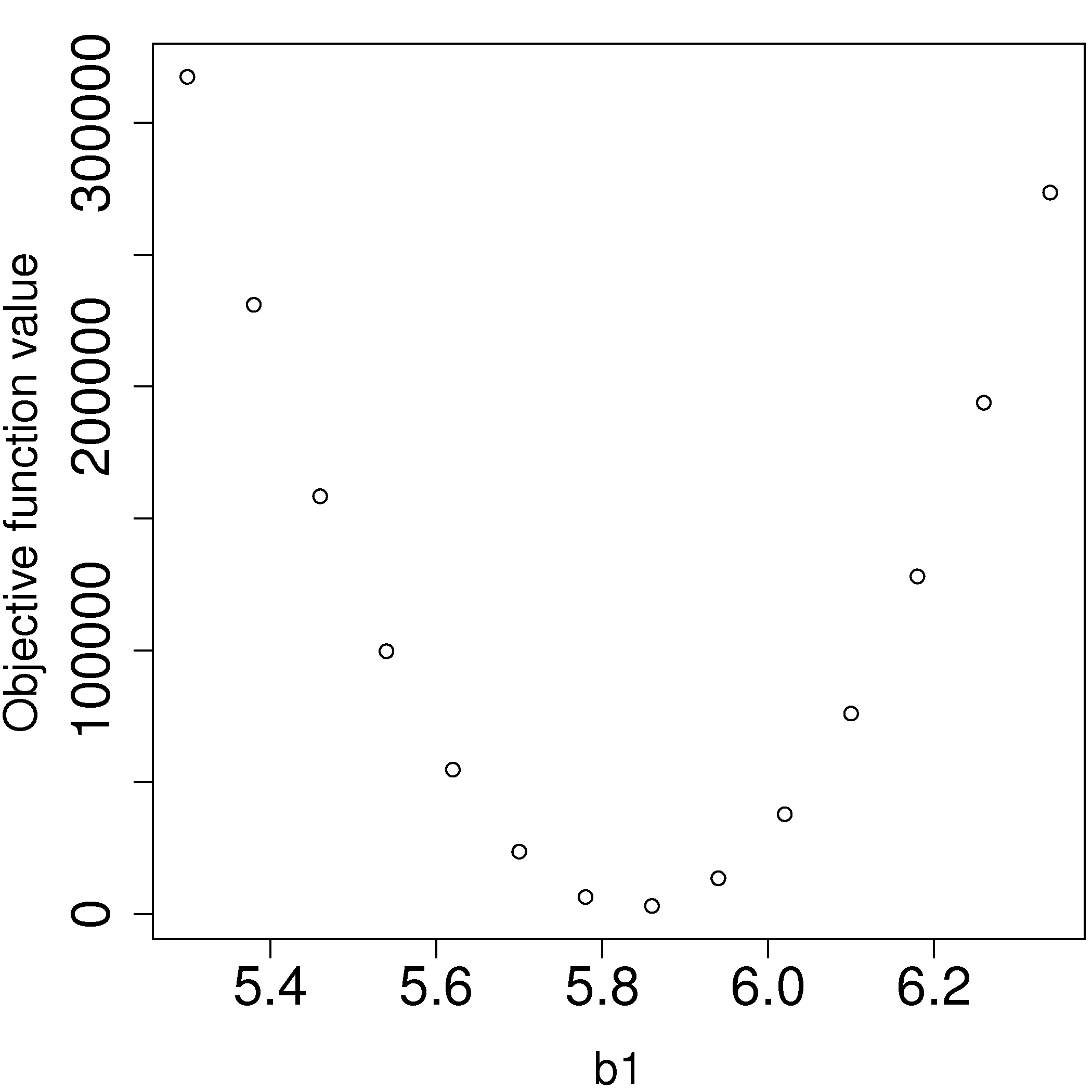
We find our best estimate for
For the case where we have both
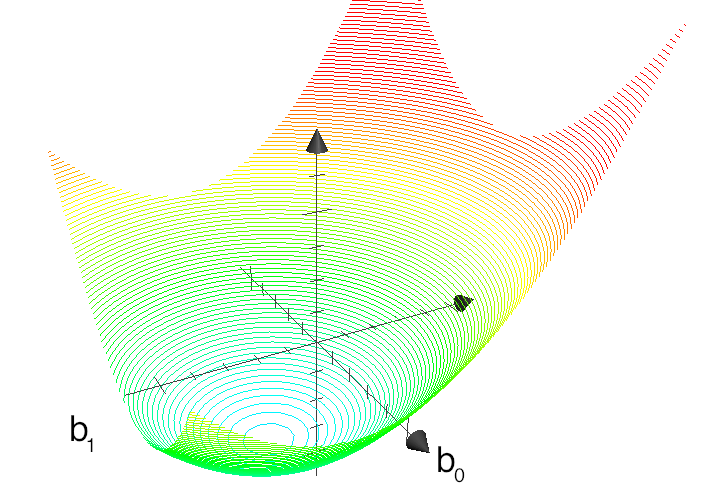
The above figure shows the general nature of the least-squares objective function where the two horizontal axes are for
The illustration highlights the quadratic nature of the objective function. To find the minimum analytically we start with equation (3) and take partial derivatives with respect to
Now divide the first line through by
Verify for yourself that:
The first part of equation (4) shows
The first part of equation (5) shows that the straight line equation passes through the mean of the data
From second part of equation (4) prove to yourself that
Also prove and interpret that
Notice that the parameter estimate for
You can also compute the second derivative of the objective function to confirm that the optimum is indeed a minimum.
Remarks:
What units does parameter estimate
The units of
Recall the temperature and pressure example: let
What is the interpretation of coefficient
A one Kelvin increase in temperature is associated, on average, with an increase of
What is the interpretation of coefficient
It is the expected pressure when temperature is zero. Note: often the data used to build the model are not close to zero, so this interpretation may have no meaning.
What does it mean that
The residuals are uncorrelated with the input variables,
What does it mean that
The fitted values are uncorrelated with the residuals.
How could the denominator term for
This shows that as long as there is variation in the
4.6.3. Example¶
We will refer back to the following example several times. Calculate the least squares estimates for the model
10.0 |
8.0 |
13.0 |
9.0 |
11.0 |
14.0 |
6.0 |
4.0 |
12.0 |
7.0 |
5.0 |
|
8.04 |
6.95 |
7.58 |
8.81 |
8.33 |
9.96 |
7.24 |
4.26 |
10.84 |
4.82 |
5.68 |
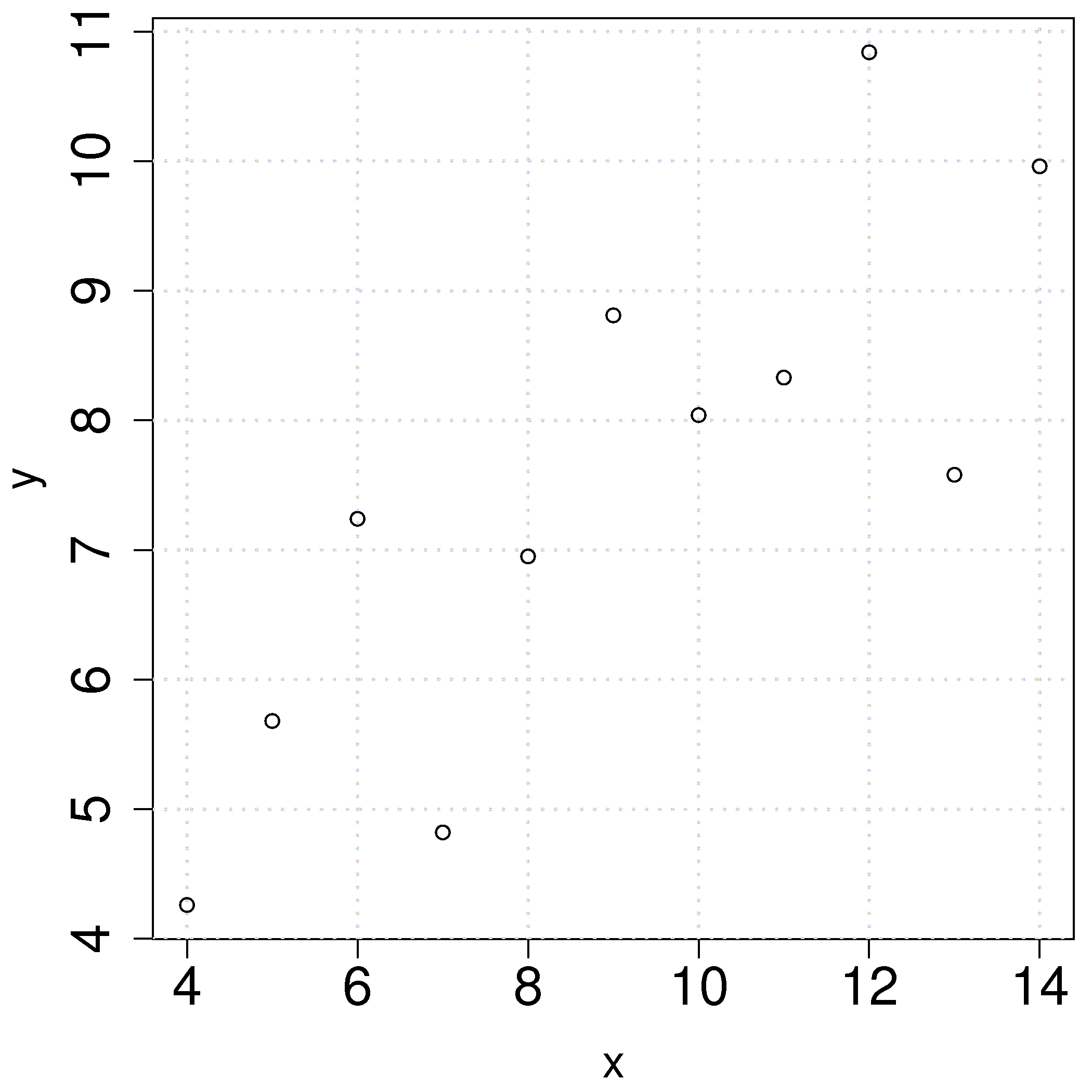
To calculate the least squares model in R:
When