2.16. Exercises¶
Question 1
Recall that
What is the expected value thrown of a fair 6-sided die? (Note: plural of die is dice)
What is the expected variance of a fair 6-sided die?
Question 2
Characterizing a distribution: Compute the mean, median, standard deviation and MAD for salt content for the various soy sauces given in this report (page 41) as described in the the article from the Globe and Mail on 24 September 2009. Plot a box plot of the data and report the interquartile range (IQR). Comment on the 3 measures of spread you have calculated: standard deviation, MAD, and interquartile range.
The raw data are given below in units of milligrams of salt per 15 mL serving:
[460, 520, 580, 700, 760, 770, 890, 910, 920, 940, 960, 1060, 1100]
Question 3
Give a reason why Statistics Canada reports the median income when reporting income by geographic area. Where would you expect the mean to lie, relative to the median? Use this table to look up the income for Hamilton. How does it compare to Toronto? And all of Canada?
Solution Click to show answerQuestion 4
Use the data set on raw materials.
Solution Click to show answer
How many variables in the data set?
How many observations?
The data are properties of a powder. Plot each variable, one at a time, and locate any outliers. R-users will benefit from the R tutorial (see the use of the
identifyfunction).
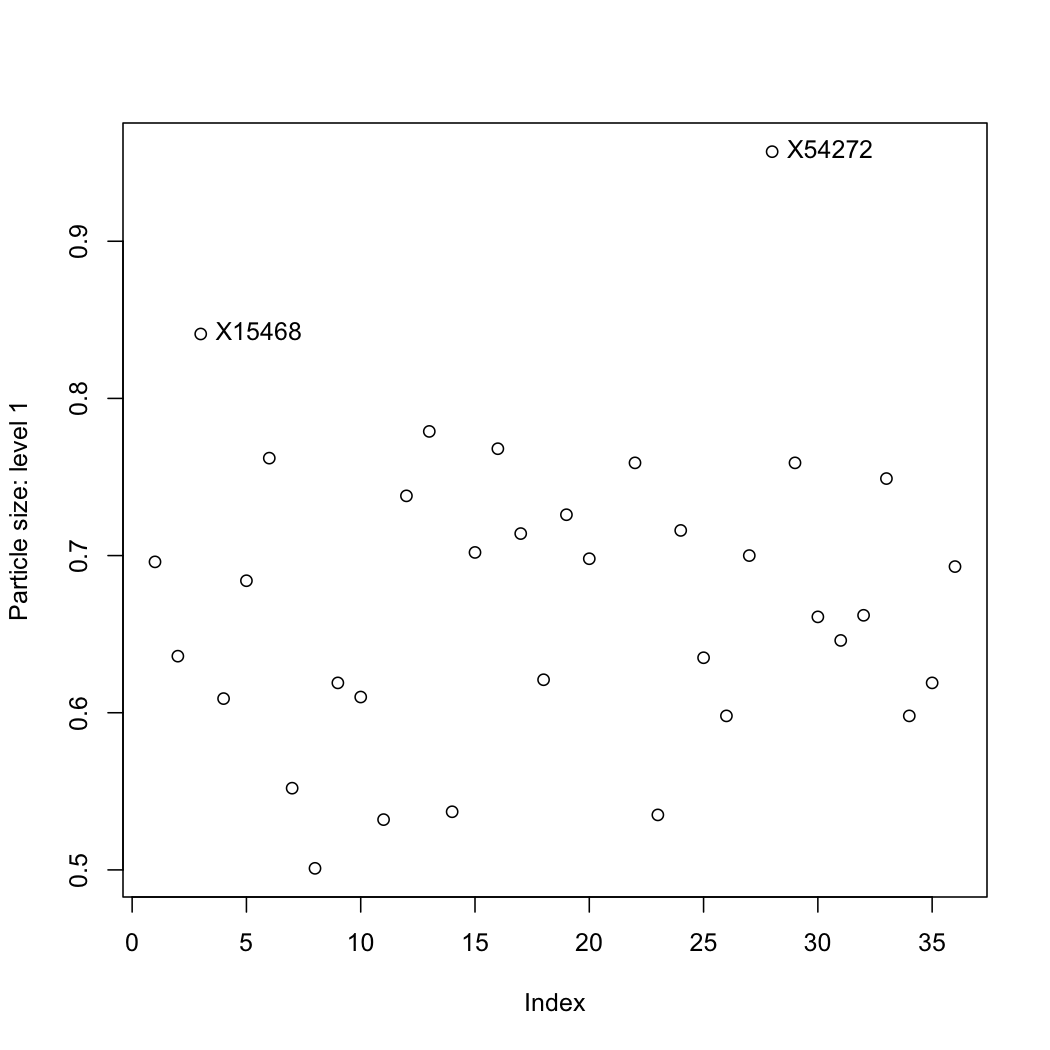
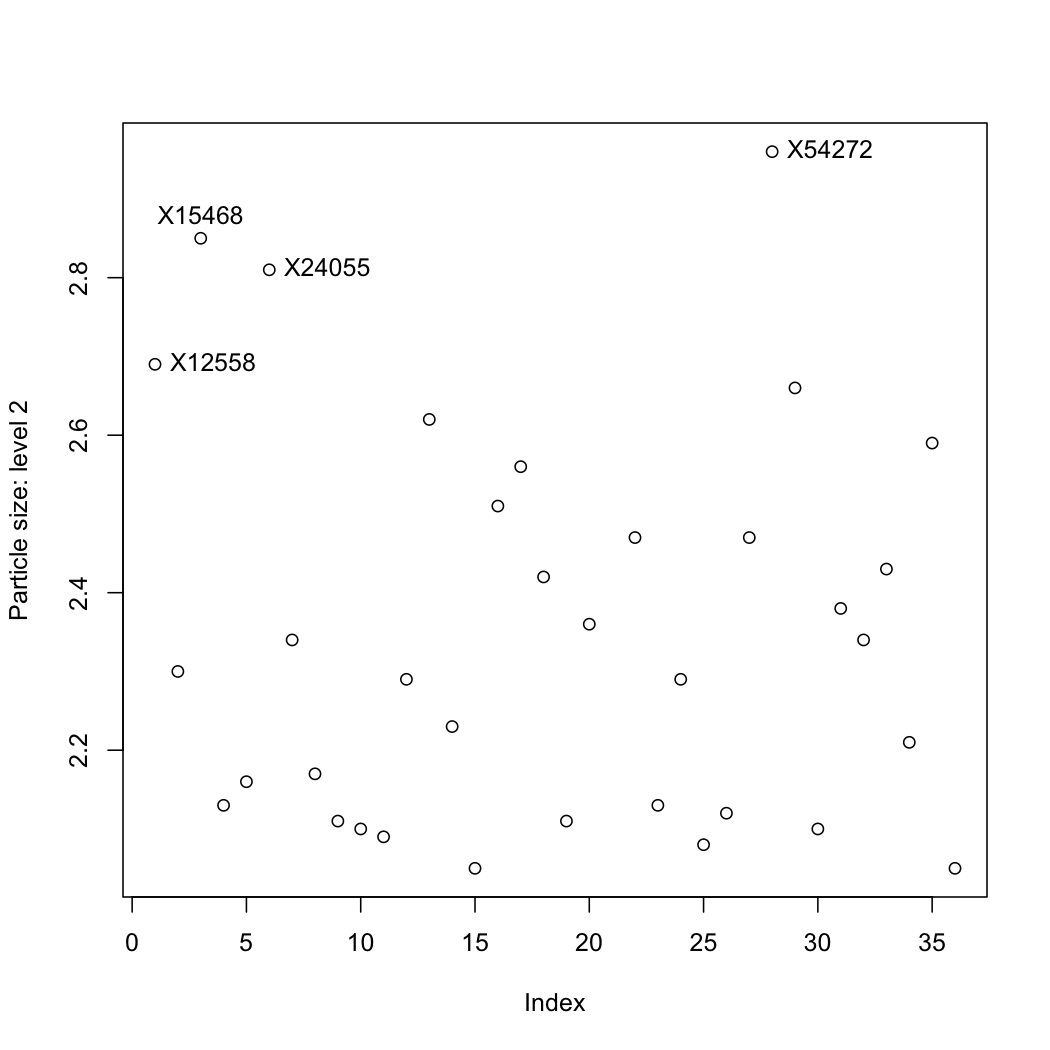
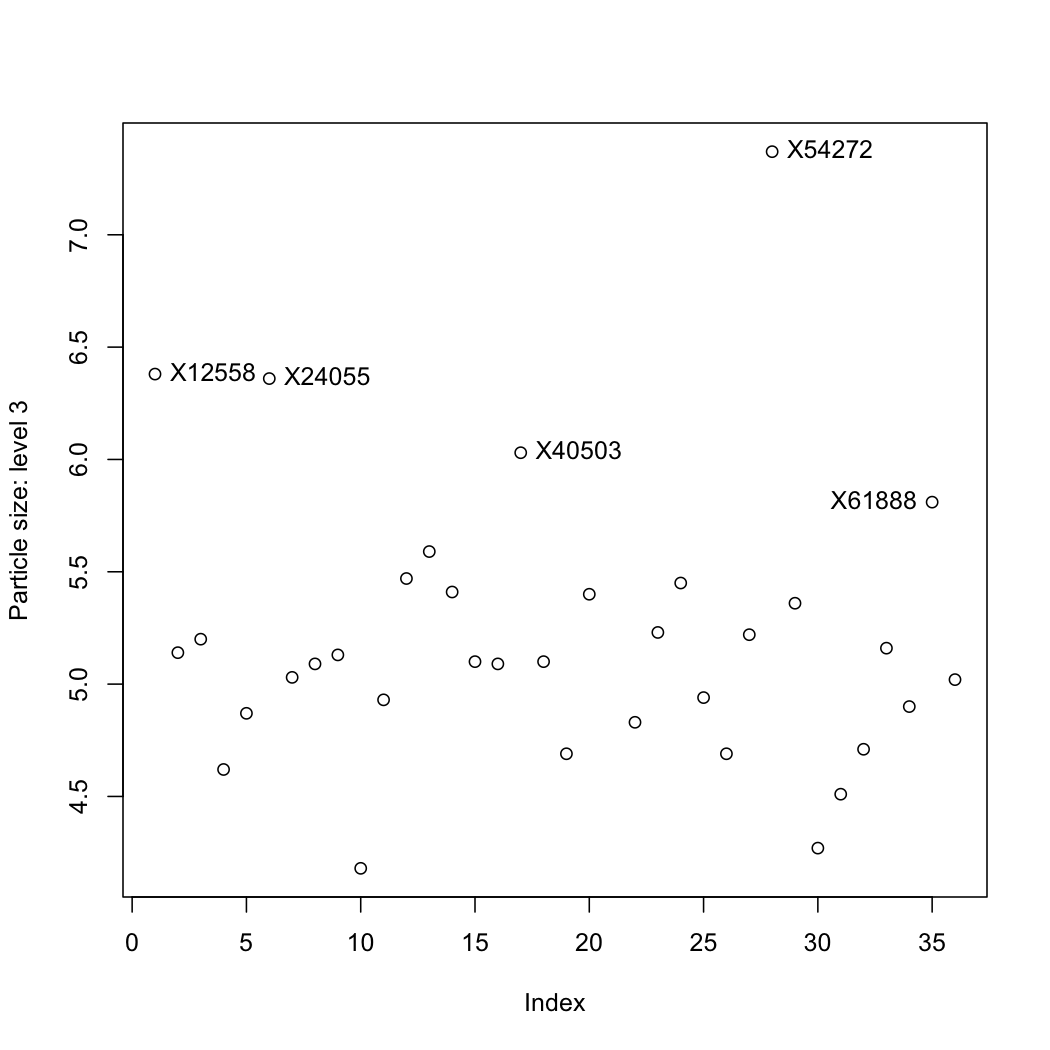
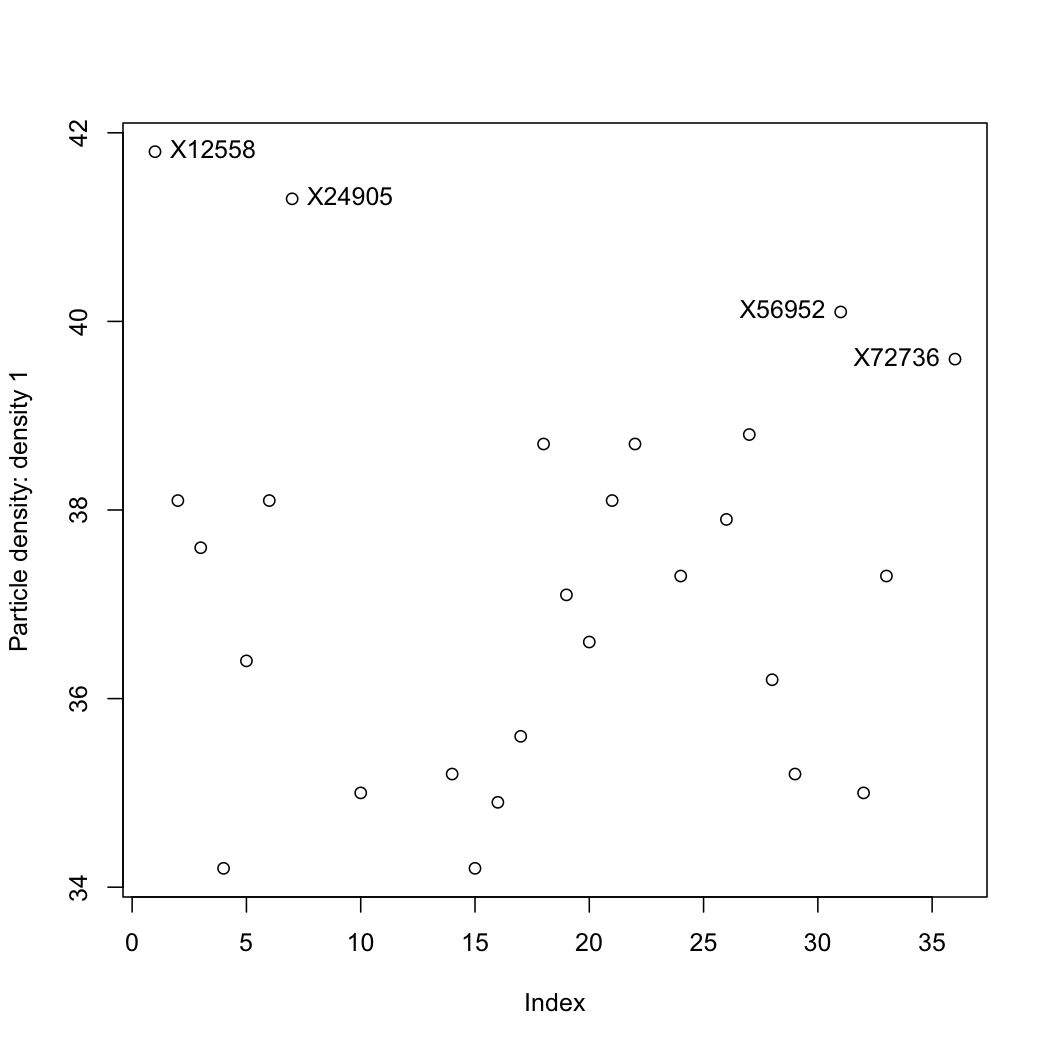
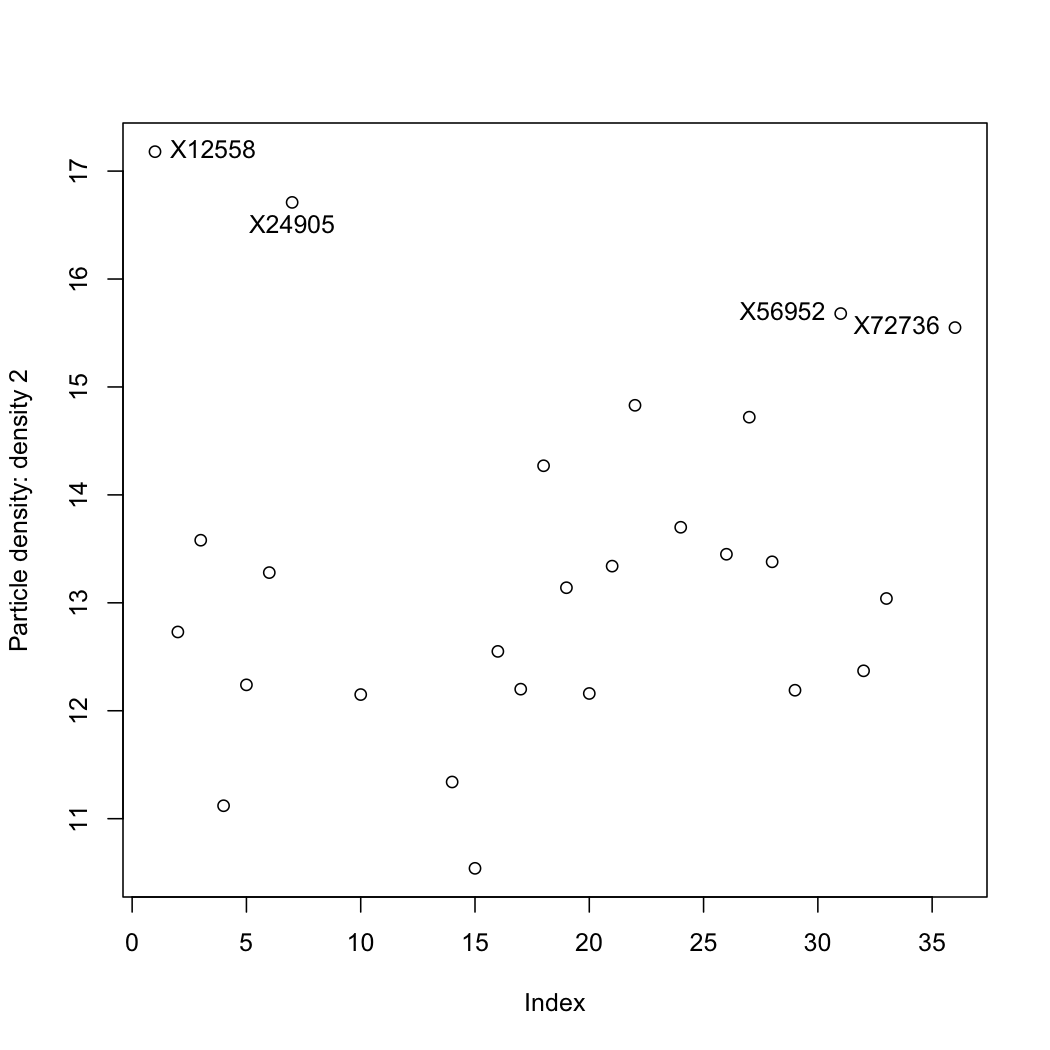
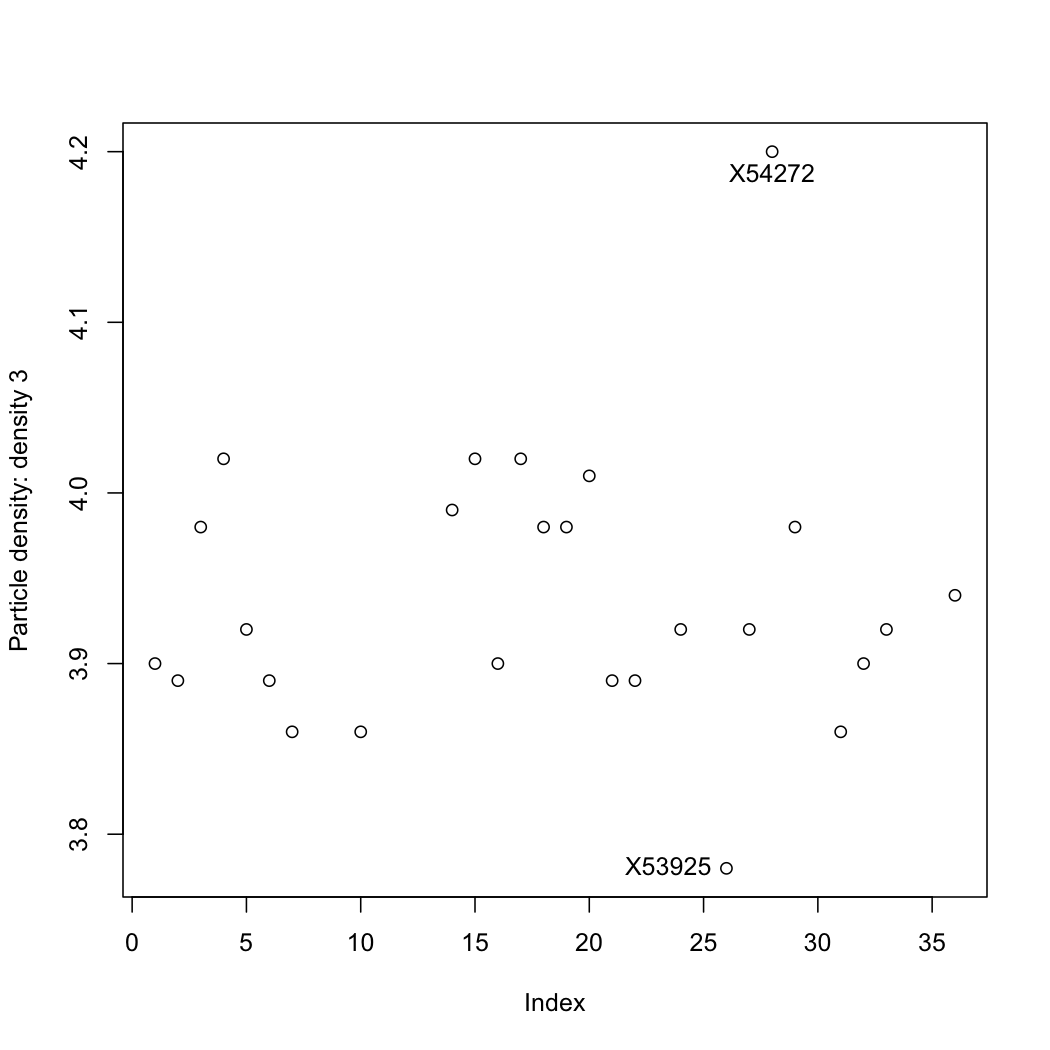
Question 5
Write a few notes on the purpose of feedback control, and its effect on variability of process quality.
Question 6
Use the section on Historical data from Environment Canada’s website and use the Customized Search option to obtain data for the HAMILTON A station from 2000 to 2009. Use the settings as Year=2000, and Data interval=Monthly and request the data for 2000, then click Next year to go to 2001 and so on.
For each year from 2000 to 2009, get the total snowfall and the average of the
Mean tempover the whole year (the sums and averages are reported at the bottom of the table).Plot these 2 variables against time
Now retrieve the long-term averages for these data from a different section of their website (use the same location,
HAMILTON A, and check that the data range is 1971 to 2000). Superimpose the long-term average as a horizontal line on your previous plot.Note: the purpose of this exercise is more for you to become comfortable with web-based data retrieval, which is common in most companies.
Note: please use any other city for this question if you prefer.
Question 7
Does the number of visits in the website traffic data set follow a normal distribution? If so, what are the parameters for the distribution? What is the likelihood that you will have between 10 and 30 visits to the website?
Short answer: Click to show answerQuestion 8
The ammonia concentration in your wastewater treatment plant is measured every 6 hours. The data for one year are available from the dataset website.
Use a visualization plot to hypothesize from which distribution the data might come. Which distribution do you think is most likely? Once you’ve decided on a distribution, use a qq-plot to test your decision.
Estimate location and spread statistics assuming the data are from a normal distribution. You can investigate using the
fitdistrfunction in R, in the MASS package.What if you were told the measured values are not independent. How does it affect your answer?
What is the probability of having an ammonia concentration greater than 40 mg/L when:
you may use only the data (do not use any estimated statistics)
you use the estimated statistics for the distribution?
Note: Answer this entire question using computer software to calculate values from the normal distribution. But also make sure you can answer the last part of the question by hand, (when given the mean and variance), and using a table of normal distributions.
Question 9
We take a large bale of polymer composite from our production line and using good sampling techniques, we take 9 samples from the bale and measure the viscosity in the lab for each sample. These samples are independent estimates of the population (bale) viscosity. We will believe these samples follow a normal distribution (we could confirm this in practice by running tests and verifying that samples from any bale are normally distributed). Here are 9 sampled values: 23, 19, 17, 18, 24, 26, 21, 14, 18.
Short answer: Click to show answer
The sample average
An estimate of the standard deviation
What is the distribution of the sample average,
? What are the parameters of that distribution? Additional information: I use a group of samples and calculate the mean,
, then I take another group of samples and calculate another , and so on. Those values of are not going to be the same, but they should be similar. In other words, the also has a distribution. So this question asks what that distribution is, and what its parameters are. Construct an interval, symbolically, that will contain, with 95% certainty (probability), the population mean of the viscosity.
Additional information: To answer this part, you should move everything to
-coordinates first. Then you need to find the points and in the following diagram that mark the boundary for a 95% of the total area under the distribution. This region is an interval that will contain, with 95% certainty, the population mean of the viscosity, . Write your answer in form: . 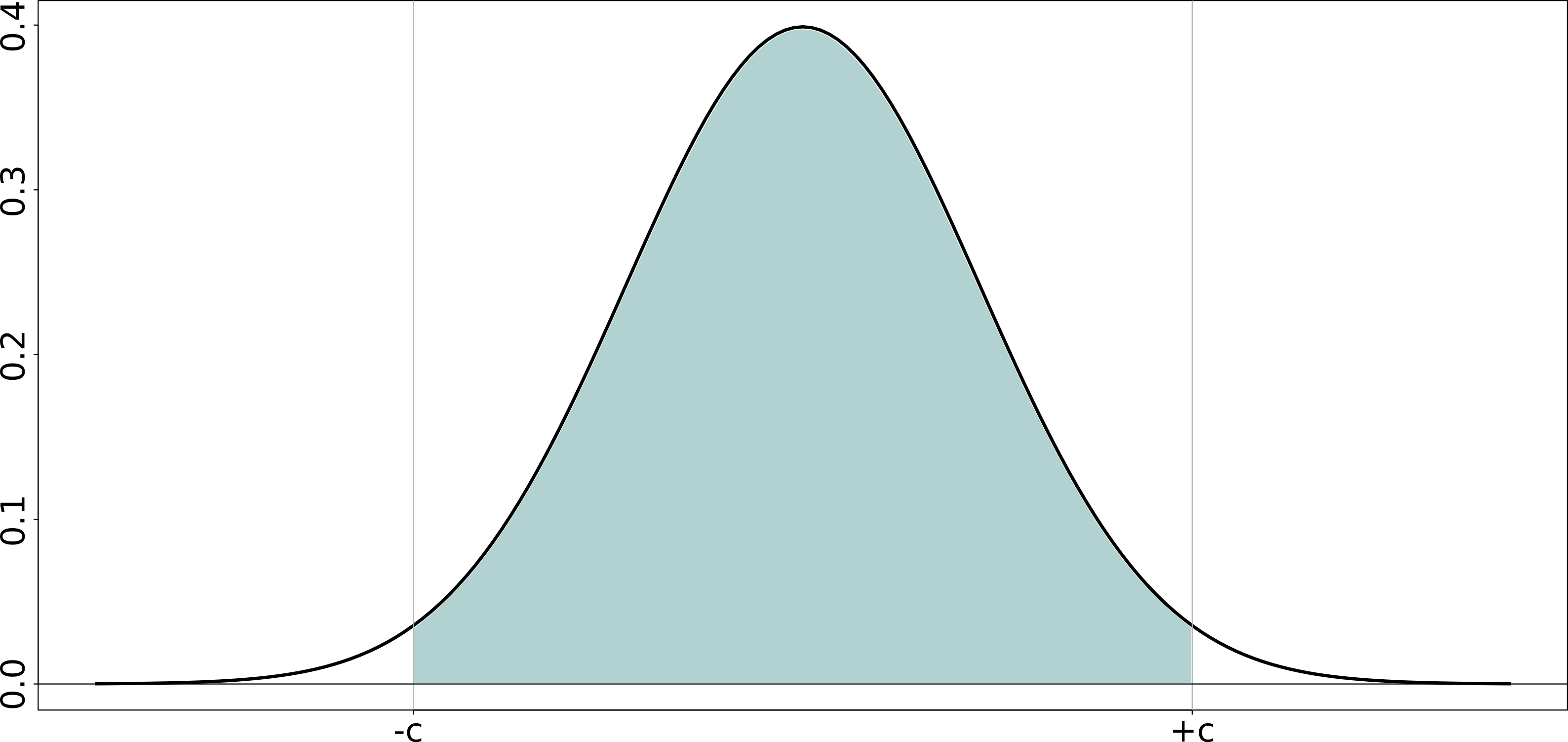
Now assume that for some hypothetical reason we know the standard deviation of the bale’s viscosity is
units, calculate the population mean’s interval numerically. Additional information: In this part you are just finding the values of
and
Question 10
You are responsible for the quality of maple syrup produced at your plant. Historical data show that the standard deviation of the syrup viscosity is 40 cP. How many lab samples of syrup must you measure so that an estimate of the syrup’s long-term average viscosity is inside a range of 60 cP, 95% of the time? This question is like the previous one: except this time you are given the range of the interval
Question 11
Your manager is asking for the average viscosity of a product that you produce in a batch process. Recorded below are the 12 most recent values, taken from consecutive batches. State any assumptions, and clearly show the calculations which are required to estimate a 95% confidence interval for the mean. Interpret that confidence interval for your manager, who is not sure what a confidence interval is.
Ensure you can also complete the question by hand, using statistical tables.
Question 12
A new wastewater treatment plant is being commissioned and part of the commissioning report requires a statement of the confidence interval of the biochemical oxygen demand (BOD). How many samples must you send to the lab to be sure the true BOD is within a range of 2 mg/L, centered about the sample average? If there isn’t enough information given here, specify your own numbers and assumptions and work with them to answer the question.
Question 13
One of the questions we posed at the start of this chapter was: Here are the yields from a batch bioreactor system for the last 3 years (300 data points; we run a new batch about every 3 to 4 days).
What sort of distribution do the yield data have?
A recorded yield value was less than 60%, what are the chances of that occurring? Express your answer as: there’s a 1 in n chance of it occurring.
Which assumptions do you have to make for the second part of this question?
Question 14
One aspect of your job responsibility is to reduce energy consumption on the plant floor. You ask the electrical supplier for the energy requirements (W.h) for running a particular light fixture for 24 hours. They won’t give you the raw data, only their histogram when they tested randomly selected bulbs (see the data and code below).
Short answer: Click to show answer> bin.centers <- c(4025, 4075, 4125, 4175, 4225, 4275, 4325, 4375) > bin.counts <- c(4, 19, 14, 5, 4, 1, 2, 1) > barplot(bin.counts, names.arg=bin.centers, ylab="Number of bulbs (N=50)", xlab="Energy required over 24 hours (W.h)", col="White", ylim=c(0,20))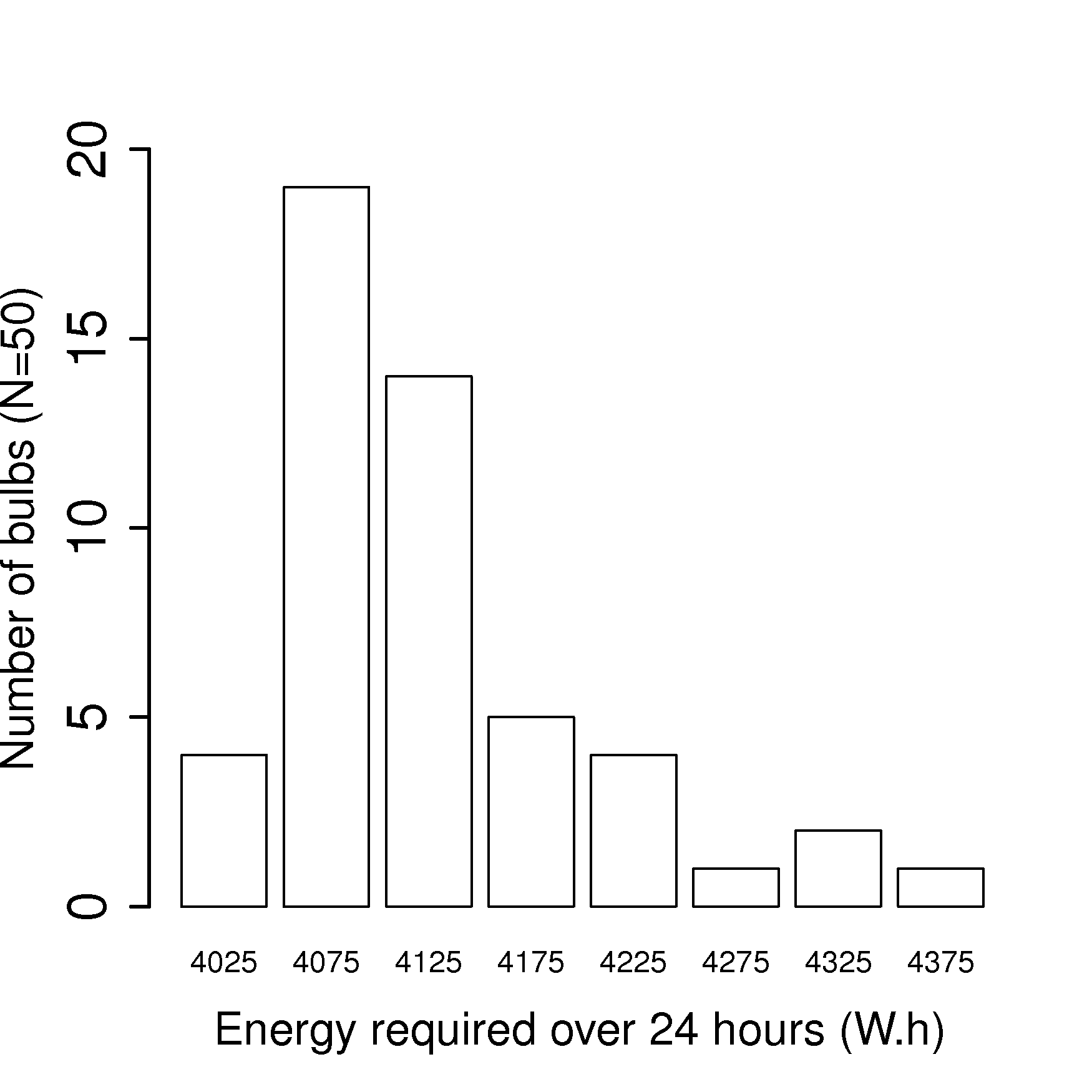
Calculate an estimate of the mean and standard deviation, even though you don’t have the original data.
What is a confidence interval for the mean at 95% probability, stating and testing any assumptions you need to make.
Question 15
The confidence interval for the population mean takes one of two forms below, depending on whether we know the variance or not. At the 90% confidence level, for a sample size of 13, compare and comment on the upper and lower bounds for the two cases. Assume that
Question 16
A major aim of many engineers is/will be to reduce the carbon footprint of their company’s high-profile products. Next week your boss wants you to evaluate a new raw material that requires 2.6
One idea you come up with is to use to your advantage the fact that your production line has three parallel reactors, TK104, TK105, and TK107. They were installed at the same time, they have the same geometry, the same instrumentation, etc; you have pretty much thought about every factor that might vary between them, and are confident the 3 reactors are identical. Typical production schedules split the raw material between the 3 reactors. Data on the website contain the brittleness values from the three reactors for the past few runs on the current raw material.
Short answer: Click to show answer
Which two reactors would you pick to run your comparative trial on next week?
Repeat your calculations assuming pairing.
Question 17
Use the website traffic data from the dataset website:
Write down, symbolically, the z-value for the difference in average visits on a Friday and Saturday.
Estimate a suitable value for the variance and justify your choice.
What is the probability of obtaining a z-value of this magnitude or smaller? Would you say the difference is significant?
Pick any other 2 days that you would find interesting to compare and repeat your analysis.
 Solution Click to show answer
Solution Click to show answerQuestion 18
You plan to run a series of 22 experiments to measure the economic advantage, if any, of switching to a corn-based raw material, rather than using your current sugar-based material. You can only run one experiment per day, and there is a high cost to change between raw material dispensing systems. Describe two important precautions you would implement when running these experiments, so you can be certain your results will be accurate.
Question 19
There are two analytical techniques for measuring biochemical oxygen demand (BOD). You wish to evaluate the two testing procedures, so that you can select the test which has lower cost, and fastest turn-around time, but without a compromise in accuracy. The table contains the results of the each test, performed on a sample that was split in half.
Is there a statistical difference in accuracy between the two methods?
Review the raw data and answer whether there is a practical difference in accuracy.
Dilution method
Manometric method
11
25
26
3
18
27
16
30
20
33
12
16
8
28
26
27
12
12
17
32
14
16
Question 20
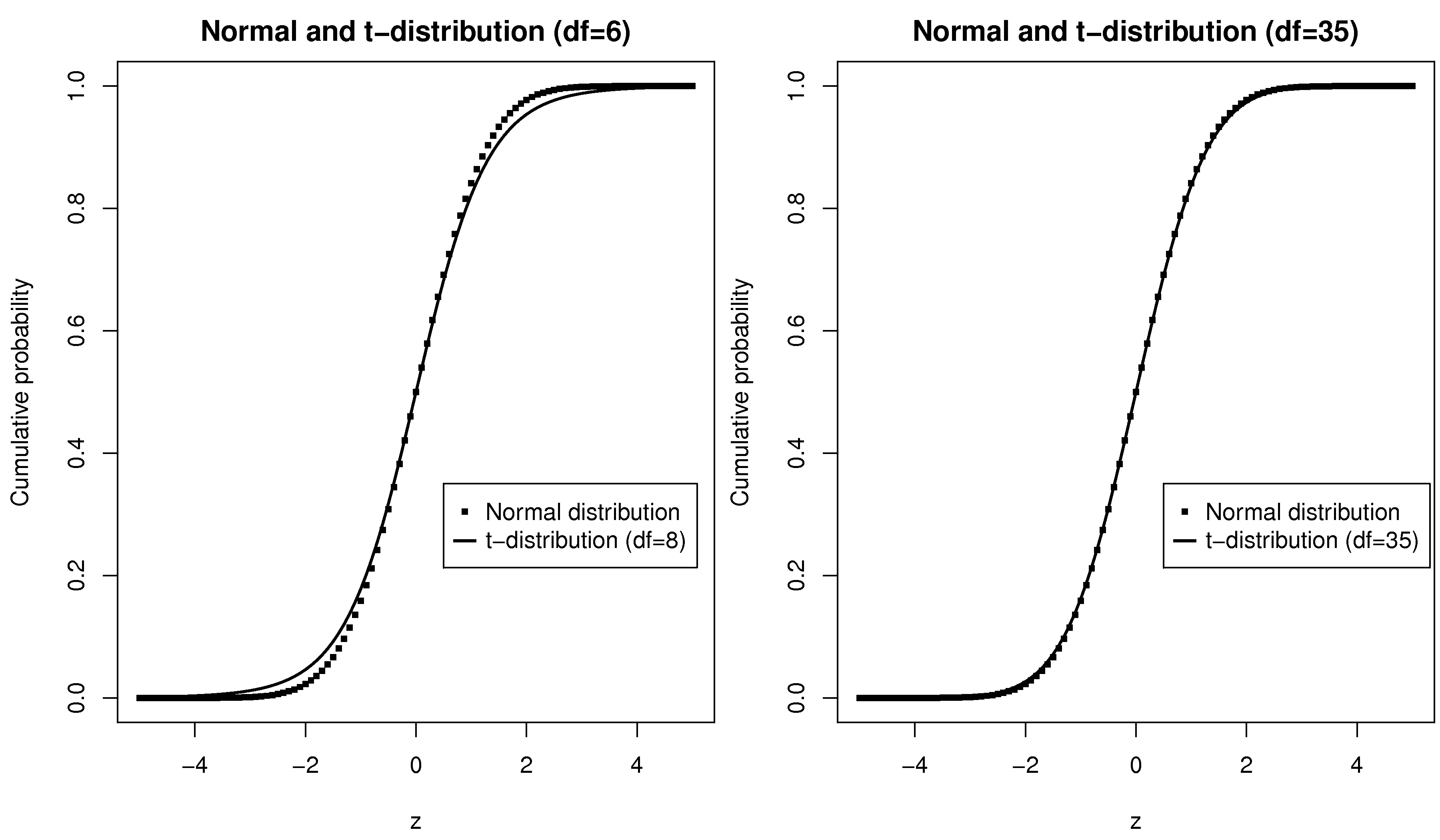
Plot the cumulative probability function for the normal distribution and the
Solution Click to show answer
Use 6 degrees of freedom for
-distribution. Repeat the plot for a larger number of degrees of freedom.
At which point is the
-distribution indistinguishable from the normal distribution? What is the practical implication of this result?
Question 21
Explain why tests of differences are insensitive to unit changes. If this were not the case, then one could show a significant difference for a weight-loss supplement when measuring waist size in millimetres, yet show no significant difference when measuring in inches!
Question 22
A food production facility fills bags with potato chips. The advertised bag weight is 35.0 grams. But, the current bagging system is set to fill bags with a mean weight of 37.4 grams, and this done so that only 1% of bags have a weight of 35.0 grams or less.
Short answer: Click to show answer
Back-calculate the standard deviation of the bag weights, assuming a normal distribution.
Out of 1000 customers, how many are lucky enough to get 40.0 grams or more of potato chips in their bags?
Question 23
A food production facility fills bags with potato chips with an advertised bag weight of 50.0 grams.
The government’s Weights and Measures Act requires that at most 1.5% of customers may receive a bag containing less than the advertised weight. At what setting should you put the target fill weight to meet this requirement exactly? The check-weigher on the bagging system shows the long-term standard deviation for weight is about 2.8 grams.
Out of 100 customers, how many are lucky enough to get 55.0 grams or more of potato chips in their bags?
Question 24
The following confidence interval is reported by our company for the amount of sulphur dioxide measured in parts per billion (ppb) that we send into the atmosphere.
Only
What assumptions were made about those 21 raw data points to compute the above confidence interval?
Which lower and upper critical values would have been used for
What is the standard deviation,
Today’s sulphur dioxide reading is 460 ppb and your manager wants to know what’s going on; you can quickly calculate the probability of seeing a value of 460 ppb, or greater, to help judge the severity of the pollution. How many days in a 365 calendar-day year are expected to show a sulphur dioxide value of 460 ppb or higher?
Explain clearly why a wide confidence interval is not desirable, from an environmental perspective.
{kind=link}
Question 25
A common unit operation in the pharmaceutical area is to uniformly blend powders for tablets. One such unit is illustrated below (figure taken from Wikipedia). In this question we consider blending an excipient (an inactive magnesium stearate base), a binder, and the active ingredient. The mixing process is tracked using a wireless near infrared (NIR) probe embedded in a V-blender. The mixer is stopped when the NIR spectra become stable. A new supplier of magnesium stearate is being considered that will save $ 294,000 per year.

The 15 most recent runs with the current magnesium stearate supplier had an average mixing time of 2715 seconds, and a standard deviation of 390 seconds. So far you have run 6 batches from the new supplier, and the average mixing time of these runs is 3115 seconds with a standard deviation of 452 seconds. Your manager is not happy with these results so far - this extra mixing time will actually cost you more money via lost production.
The manager wants to revert back to the original supplier, but is leaving the decision up to you; what would be your advice? Show all calculations and describe any additional assumptions, if required.
Short answer: Click to show answerQuestion 26
List an advantage of using a paired test over an unpaired test. Give an example, not from the notes, that illustrates your answer.
Question 27
An unpaired test to distinguish between group A and group B was performed with 18 runs: 9 samples for group A and 9 samples for group B. The pooled variance was 86 units.
Also, a paired test on group A and group B was performed with 9 runs. After calculating the paired differences, the variance of these differences was found to be 79 units.
Discuss, in the context of this example, an advantage of paired tests over unpaired tests. Assume 95% confidence intervals, and that the true result was one of “no significant difference between method A and method B”. Give numeric values from this example to substantiate your answer.
Question 28
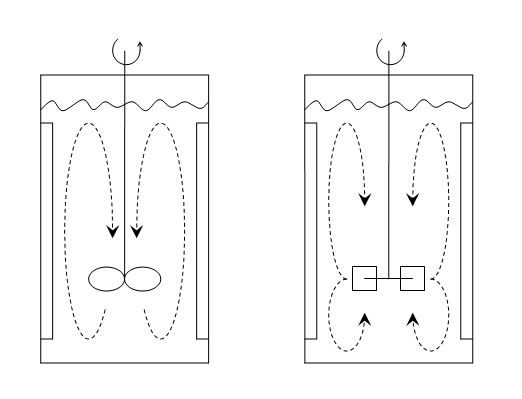
You are convinced that a different impeller (mixing blade) shape for your tank will lead to faster, i.e. shorter, mixing times. The choices are either an axial blade or a radial blade, as shown in this figure from Wikipedia.
Before obtaining approval to run some experiments, your team wants you to explain how you will interpret the experimental data. Your reply is that you will calculate the average mixing time from each blade type and then calculate a confidence interval for the difference. A team member asks you what the following 95% confidence intervals would mean:
For both cases (a) explain what the confidence interval means in the context of this experiment, and (b) whether the recommendation would be to use radial or axial impellers to get the shortest mixing time.
3. Now assume the result from your experimental test was
Question 29
The paper by PJ Rousseeuw, “Tutorial to Robust Statistics”, Journal of Chemometrics, 5, 1-20, 1991 discusses the breakdown point of a statistic.
Describe what the breakdown point is, and give two examples: one with a low breakdown point, and one with a high breakdown point. Use a vector of numbers to help illustrate your answer.
What is an advantage of using robust methods over their “classical” counterparts?
Question 30
Why are robust statistics, such as the median or MAD, important in the analysis of modern data sets? Explain, using an example, if necessary.
What is meant by the break-down point of a robust statistic? Give an example to explain your answer.
Question 31
Recall that
Solution Click to show answer
What is the expected value thrown of a fair, 12-sided dice?
What is the expected variance of a fair, 12-sided dice?
Simulate 10,000 throws in a software package (R, MATLAB, or Python) from this dice and see if your answers match those above. Record the average value from the 10,000 throws, call that average
. Repeat the simulation 10 times, calculating the average value of all the dice throws. Calculate the mean and standard deviation of the 10
values and comment whether the results match the theoretically expected values.
Question 32
Removed. Was a duplicate of a prior question (number 13).
Question 33
At the 95% confidence level, for a sample size of 7, compare and comment on the upper and lower bounds of the confidence interval that you would calculate if:
you know the population standard deviation
you have to estimate it for the sample.
Assume that the calculated standard deviation from the sample,
As a follow up, overlay the probability distribution curves for the normal and
Repeat part of this question, using larger sample sizes. At which point does the difference between the
What is the implication of this?
Question 34
Engineering data often violate the assumption of independence. In this question you will create (simulate) sequences of autocorrelated data, i.e. data that lack independence, and investigate how lack of independence affects our results.
The simplest form of autocorrelation is what is called lag-1 autocorrelation, when the series of values,
The
Create 3 sequences of autocorrelated data with:
A:
(positively correlated) B:
(uncorrelated data) C:
(negatively correlated)
For case A, B and C perform the following analysis. Repeat the following 1000 times (let
Create a vector of 100 autocorrelated
values using the above formula, using the current level of Calculate the mean of these 100 values, call it
and store the result
At this point you have 1000
Assuming independence, which is obviously not correct for 2 of the 3 cases, nevertheless, from which population should
Now, using your 1000 simulated means, estimate those two population parameters.
Compare your estimates to the theoretical values.
Comment on the results, and the implication of this regarding tests of significance (i.e. statistical tests to see if a significant change occurred or not).
Solution Click to show answerQuestion 35
Sulphur dioxide is a byproduct from ore smelting, coal-fired power stations, and other sources.
These 11 samples of sulphur dioxide, SO2, measured in parts per billion [ppb], were taken from our plant. Environmental regulations require us to report the 90% confidence interval for the mean SO2 value.
What is the confidence interval that must be reported, given that the sample average of these 11 points is 181.9 ppb and the sample standard deviation is 106.8 ppb?
Why might Environment Canada require you to report the confidence interval instead of the mean?
Question 36
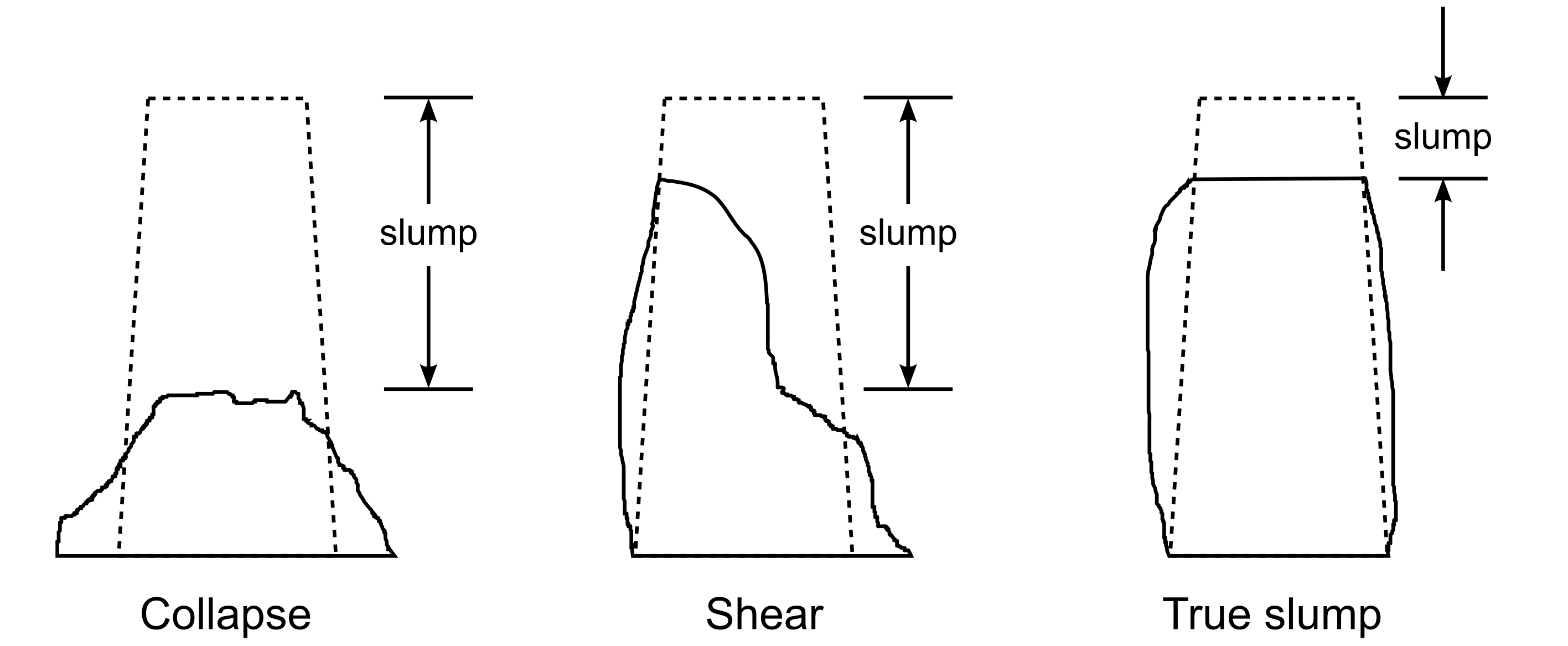
A concrete slump test is used to test for the fluidity, or workability, of concrete. It’s a crude, but quick test often used to measure the effect of polymer additives that are mixed with the concrete to improve workability.
The concrete mixture is prepared with a polymer additive. The mixture is placed in a mold and filled to the top. The mold is inverted and removed. The height of the mold minus the height of the remaining concrete pile is called the “slump”, as shown in this figure from Wikipedia.
{kind=link}
Your company provides the polymer additive, and you are developing an improved polymer formulation, call it B, that hopefully provides the same slump values as your existing polymer, call it A. Formulation B costs less money than A, but you don’t want to upset, or lose, customers by varying the slump value too much.
You have a single day to run your tests (experiments). Preparation, mixing times, measurement and clean up take 1 hour, only allowing you to run 10 experiments. Describe all precautions, and why you take these precautions, when planning and executing your experiment. Be very specific in your answer (use bullet points).
The following slump values were recorded over the course of the day:
Additive
Slump value [cm]
A
5.2
A
3.3
B
5.8
A
4.6
B
6.3
A
5.8
A
4.1
B
6.0
B
5.5
B
4.5
What is your conclusion on the performance of the new polymer formulation (system B)? Your conclusion must either be “send the polymer engineers back to the lab” or “let’s start making formulation B for our customers”. Explain your choice clearly.
To help you,
Note: In your answer you must be clear on which assumptions you are using and, where necessary, why you need to make those assumptions.
Describe the circumstances under which you would rather use a paired test for differences between polymer A and B.
What are the advantage(s) of the paired test over the unpaired test?
Clearly explain which assumptions are used for paired tests, and why they are likely to be true in this case?
The slump tests were actually performed in a paired manner, where pairing was performed based on the cement supplier. Five different cement suppliers were used:
Supplier
Slump value [cm] from A
Slump value [cm] from B
1
5.2
5.8
2
3.3
4.5
3
4.6
6.0
4
5.8
5.5
5
4.1
6.2
Use these data, and provide, if necessary, an updated recommendation to your manager.
Question 37
You are planning a series of experiments to test alternative conditions in a store and see which conditions lead to higher sales.
Which practical steps would you take to ensure independence in the experimental data, when investigating:
adjustable halogen lighting: A = soft and dim lighting and B = brighter lighting
alternative shelving: A = solid white metal shelves and B = commercial stainless steel racking
Question 38
This question gives you exposure to analyzing a larger data set than seen in the preceding questions.
Your manager has asked you to describe the flow rate characteristics of the overhead stream leaving the top of the distillation column at your plant. You are able to download one month of data, available from this website, from 1 March to 31 March, taken at one minute intervals to answer this question.