4.11. Outliers: discrepancy, leverage, and influence of the observations¶
Unusual observations will influence the model parameters and also influence the analysis from the model (standard errors and confidence intervals). In this section we will examine how these outliers influence the model.
Outliers are in many cases the most interesting data in a data table. They indicate whether there was a problem with the data recording system, they indicate sometimes when the system is operating really well, though more likely, they occur when the system is operating under poor conditions. Nevertheless, outliers should be carefully studied for (a) why they occurred and (b) whether they should be retained in the model.
4.11.1. Background¶
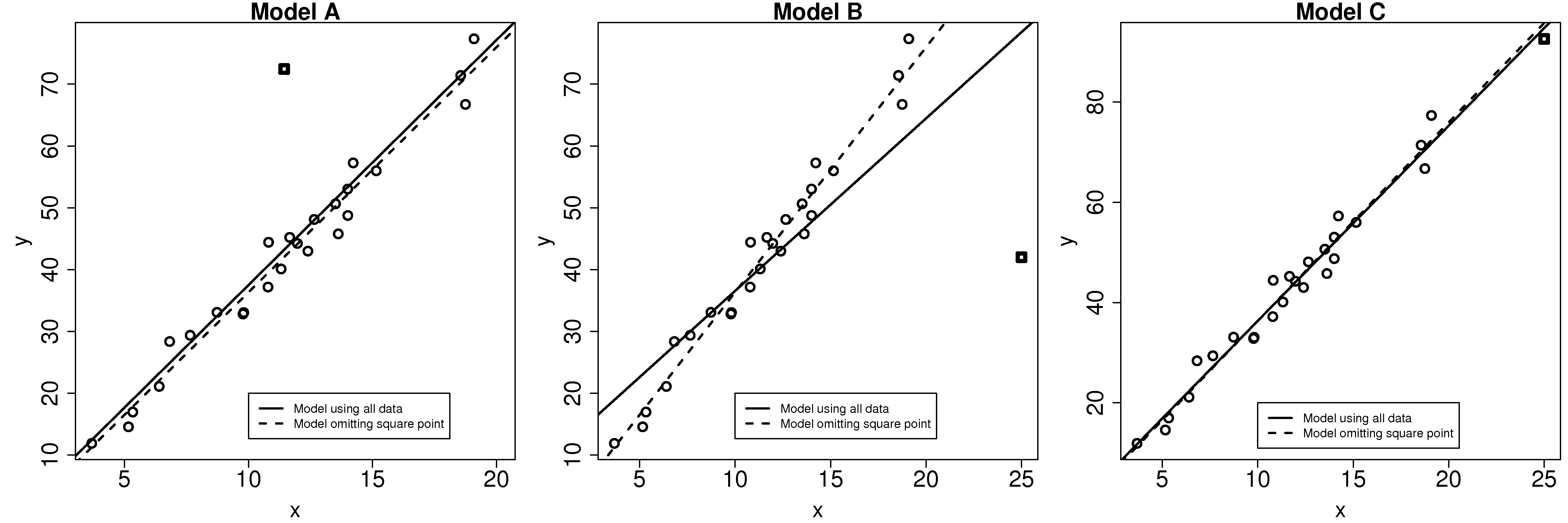
A discrepancy is a data point that is unusual in the context of the least squares model, as shown in the first figure here. On its own, from the perspective of either
The discrepant square point in model B has much more influence on the model. Given that the objective function aims to minimize the sum of squares of the deviations, it is not surprising that the slope is pulled towards this discrepant point. Removing that point gives a different dashed-line estimate of the slope and intercept.
In model C the square point is not discrepant in the context of the model. But it does have high leverage on the model: a small change in this point has the potential to be influential on the model.
Can we quantify how much influence these discrepancies have on the model; and what is leverage? The following general formula is helpful in the rest of this discussion:
4.11.2. Leverage¶
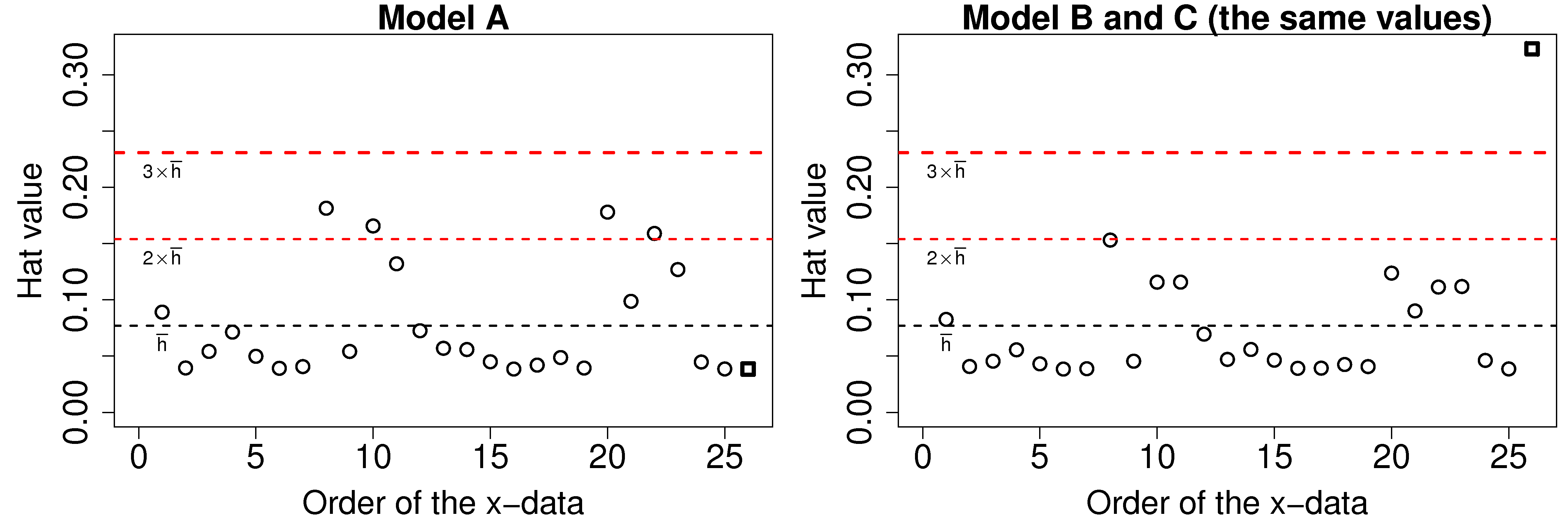
Leverage measures how much each observation contributes to the model’s prediction of
The average hat value can be calculated theoretically. While it is common to plot lines at 2 and 3 times the average hat value, always plot your data and judge for yourself what a large leverage means. Also notice that smallest hat value is always positive and greater or equal to
4.11.3. Discrepancy¶
Discrepancy can be measured by the residual distance. However the residual is not a complete measure of discrepancy. We can imagine cases where the point has such high leverage that it drags the entire model towards it, leaving it only with a small residual. One way then to isolate these points is to divide the residual by
Where rstudent(lm(y~x)) function in R to compute the studentized residuals from a given model.
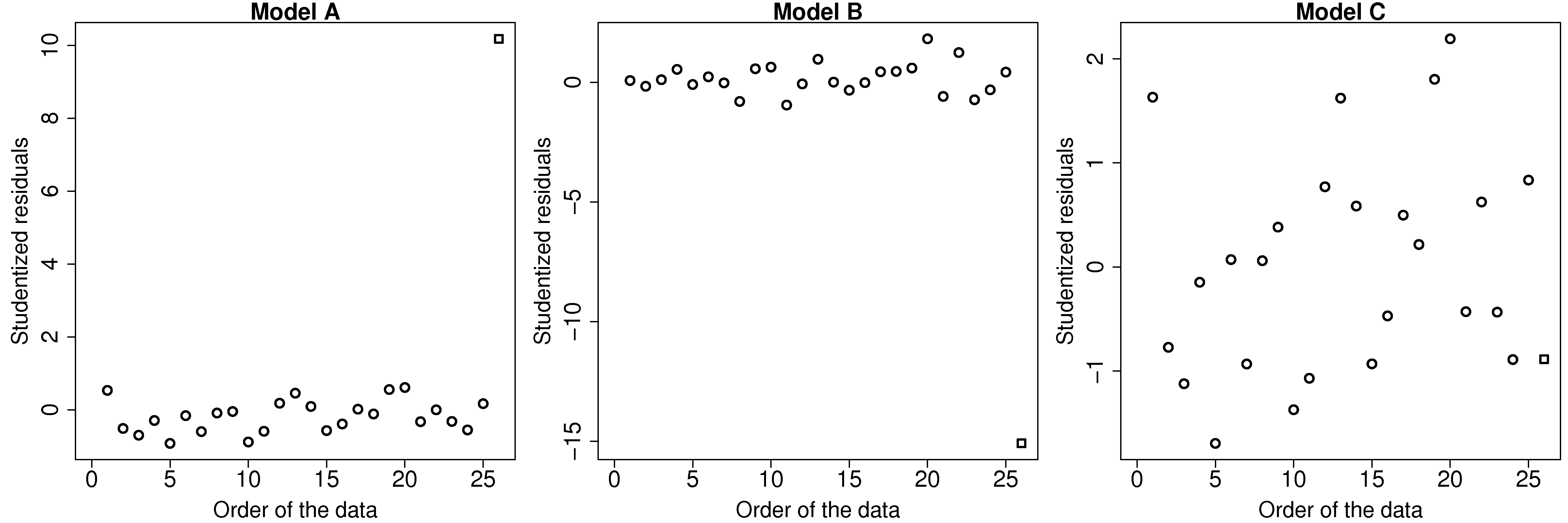
This figure illustrates how the square point in model A and B is highly discrepant, while in model C it does not have a high discrepancy.
4.11.4. Influence¶
The influence of each data point can be quantified by seeing how much the model changes when we omit that data point. The influence of a point is a combination its leverage and its discrepancy. In model A, the square point had large discrepancy but low leverage, so its influence on the model parameters (slope and intercept) was small. For model C, the square point had high leverage, but low discrepancy, so again the change in the slope and intercept of the model was small. However model B had both large discrepancy and high leverage, so its influence is large.
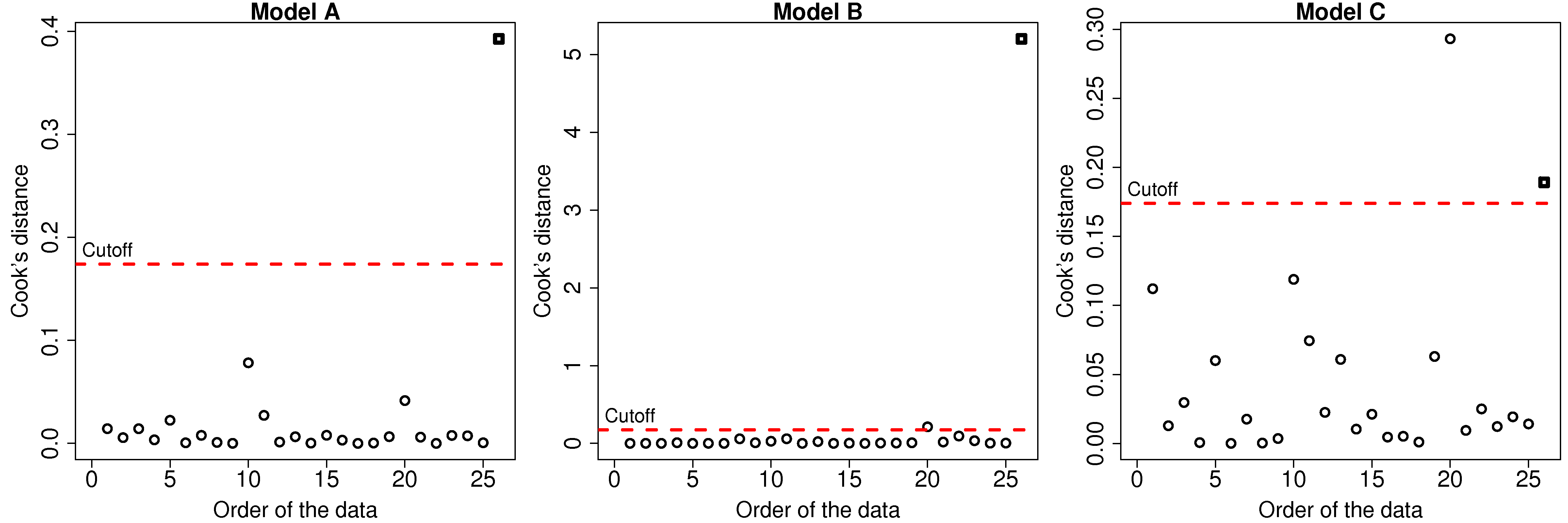
One measure is called Cook’s statistic, usually called
where
The values of cooks.distance(model) function. The results for the 3 models are shown. Interestingly for model C there is a point with even higher influence than the square point. Can you locate that point in the least squares plot?