6.5.17. Some properties of PCA models¶
We summarize various properties of the PCA model, most have been described in the previous sections. Some are only of theoretical interest, but others are more practical.
The model is defined by the direction vectors, or loadings vectors, called
These vectors form a line for one component, a plane for 2 components, and a hyperplane for 3 or more components. This line, plane or hyperplane define the latent variable model.
An equivalent interpretation of the model plane is that these direction vectors are oriented in such a way that the scores have maximal variance for that component. No other directions of the loading vector (i.e. no other hyperplane) will give a greater variance.
This plane is calculated with respect to a given data set,
where
In general we can illustrate this:
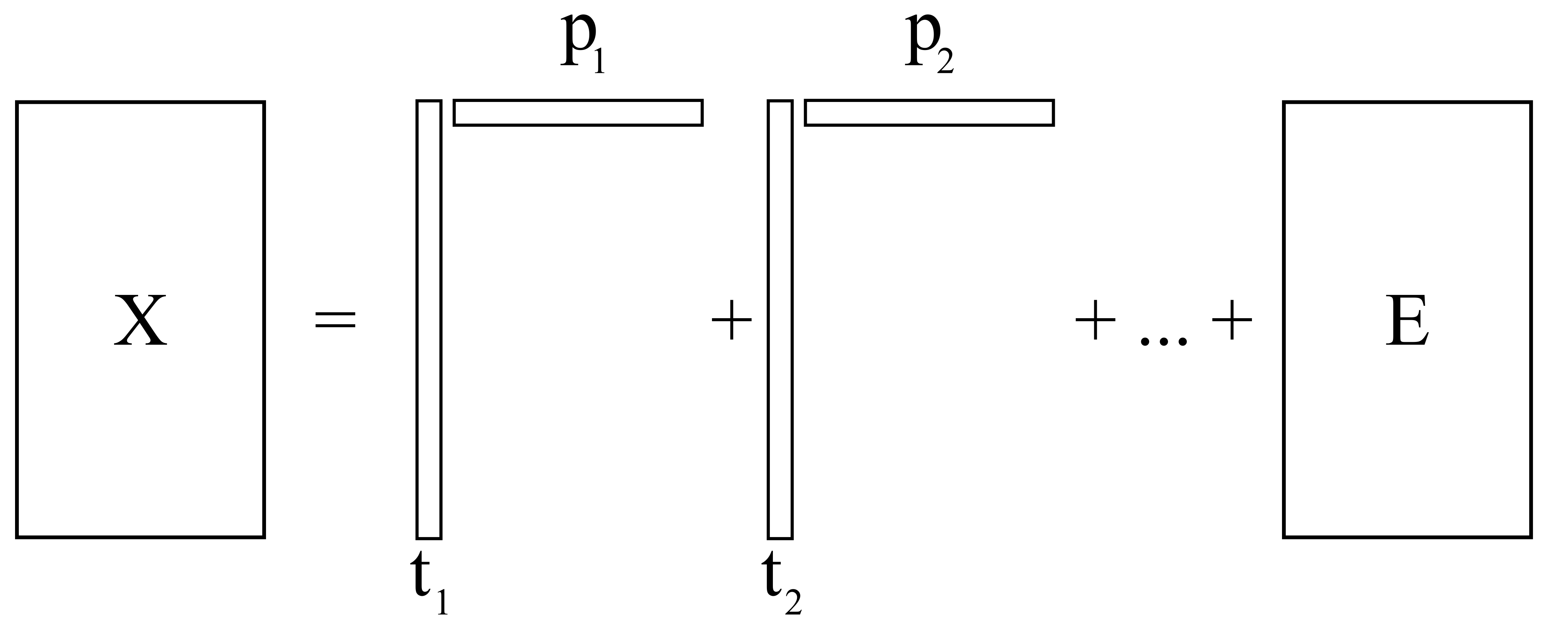
The loadings vectors are of unit length:
The loading vectors are independent or orthogonal to one another:
Orthonormal matrices have the property that
These last 3 properties imply that
The variance of the
The maximum number of components that can be extracted is the smaller of
The eigenvalue decomposition of
The singular value decomposition of
If there are no missing values in
Notice that some score values are positive and others negative. Each loading direction,