6.7.5. Interpreting the scores in PLS
Like in PCA, our scores in PLS are a summary of the data from both blocks. The reason for saying that, even though there are two sets of scores, and , for each of and respectively, is that they have maximal covariance. We can interpret one set of them. In this regard, the scores are more readily interpretable, since they are always available. The scores are not available until is known. We have the scores during model-building, but when we use the model on new data (e.g. when making predictions using PLS), then we only have the scores.
The scores for PLS are interpreted in exactly the same way as for PCA. Particularly, we look for clusters, outliers and interesting patterns in the line plots of the scores.
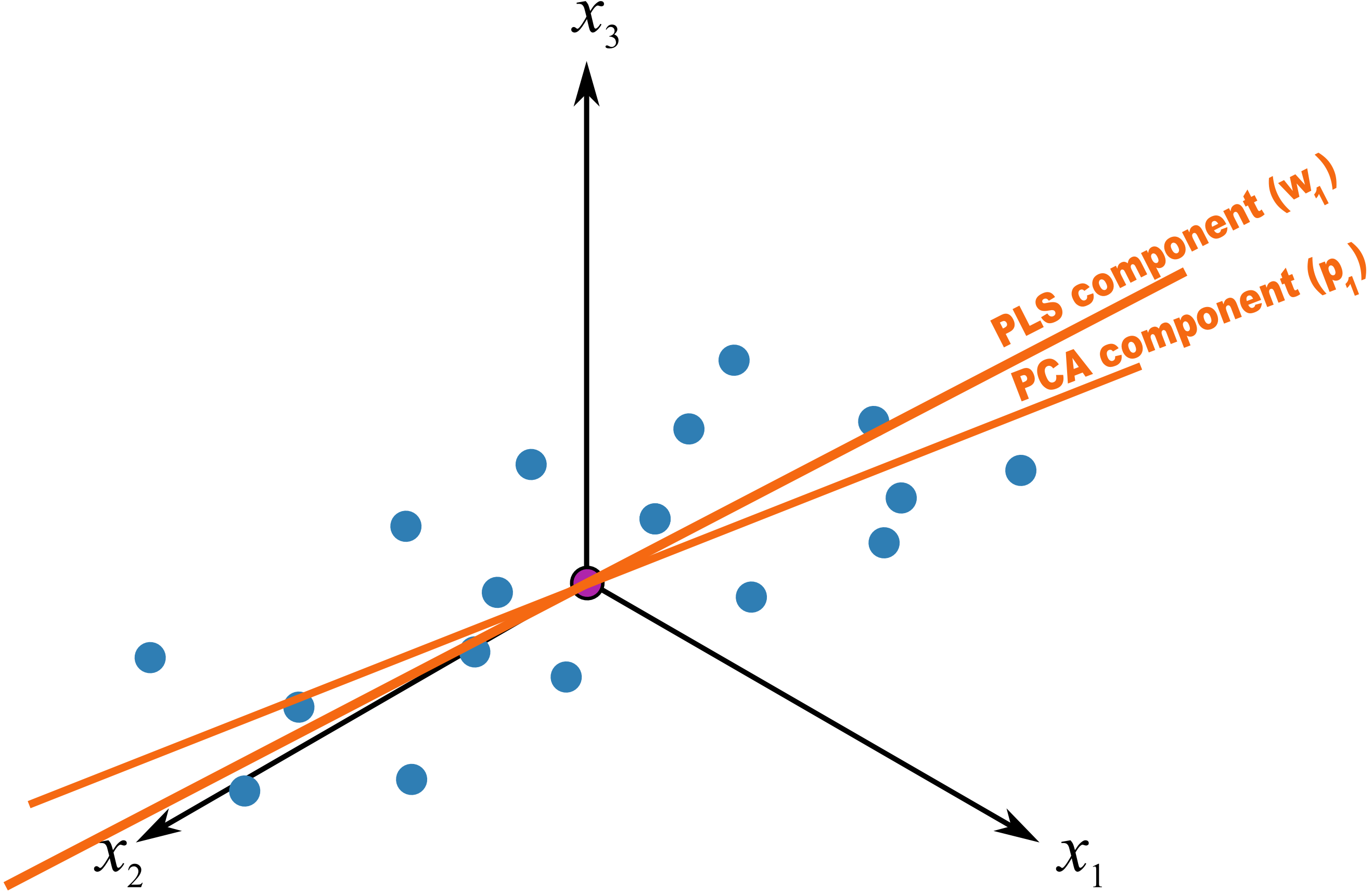
The only difference that must be remembered is that these scores have a different orientation to the PCA scores. As illustrated below, the PCA scores are found so that they only explain the variance in ; the PLS scores are calculated so that they also explain and have a maximum relationship between and . Most time these directions will be close together, but not identical.
6.7.6. Interpreting the loadings in PLS
Like with the loadings from PCA, ,we interpret the loadings from PLS in the same way. Highly correlated variables have similar weights in the loading vectors and appear close together in the loading plots of all dimensions.
We tend to refer to the PLS loadings, , as weights; this is for reasons that will be explained soon.
There are two important differences though when plotting the weights. The first is that we superimpose the loadings plots for the and space simultaneously. This is very powerful, because we not only see the relationship between the variables (from the vectors), we also see the relationship between the variables (from the vectors), and even more usefully, the relationship between all these variables.
This agrees again with our (engineering) intuition that the and variables are from the same system; they have been, somewhat arbitrarily, put into different blocks. The variables in could just have easily been in , but they are usually not available due to time delays, expense of measuring them frequently, etc. So it makes sense to consider the and weights simultaneously.
The second important difference is that we don’t actually look at the vectors directly, we consider rather what is called the vector, though much of the literature refers to it as the vector (w-star). The reason for the change of notation from existing literature is that is confusingly similar to the multiplication operator (e.g. : is frequently confused by newcomers, whereas would be cleaner). The notation gets especially messy when adding other superscript and subscript elements to it. Further, some of the newer literature on PLS, particularly SIMPLS, uses the notation.
The vectors show the effect of each of the original variables, in undeflated form, rather that using the vectors which are the deflated vectors. This is explained next.