The two previous charts highlight 2 extremes of monitoring charts. On the one hand, a Shewhart chart assumes each subgroup sample is independent (unrelated) to the next - implying there is no “memory” in the chart. On the other hand, a CUSUM chart has an infinite memory, all the way back to the time the chart was started or reset at (see the equation in the prior section).
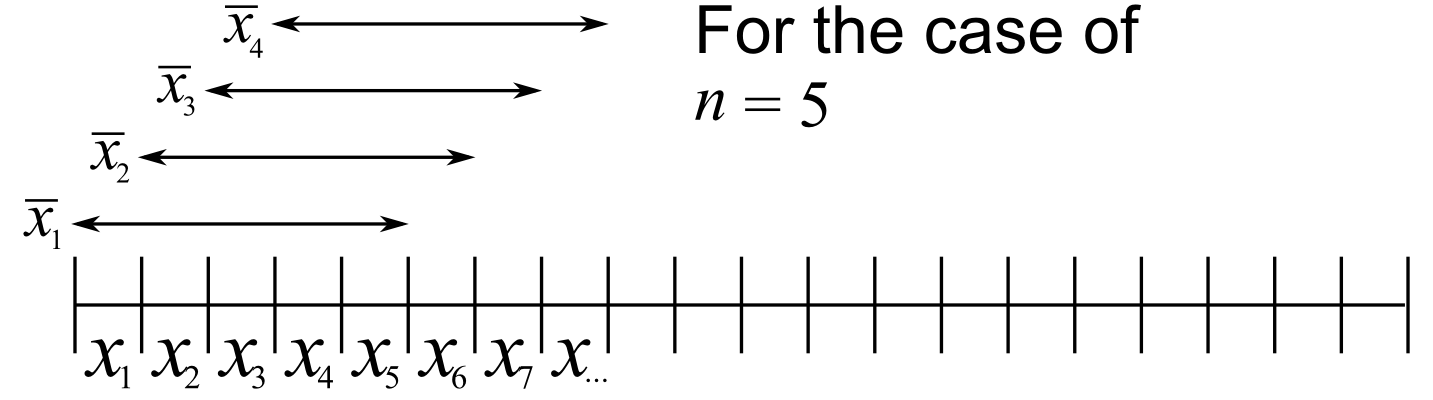
As an introduction to the exponentially weighted moving average (EWMA) chart, consider first the simple moving average (MA) chart. This chart is used just like a Shewhart chart, except the samples that make up each subgroup are calculated using a moving window of width . The case of is shown below.
The MA chart plots values of , calculated from groups of size , using equal weight for each of the most recent raw data.
The EWMA chart is similar to the MA chart, but uses different weights; heavier weights for more recent observations, tailing off exponentially to very small weights further back in history. Let’s take a look at a derivation.
Define the process target as and define as a new data measurement arriving now. We then try to create an estimate of that incoming value, giving some weight, , to the actual measured value, and the rest of the weight, , to the prior estimate.
Let us write the estimate of as , with the mark above the to indicate that it is a prediction of the actual measured value. The prior estimate is therefore written as .
So putting into equation form that “an estimate of that incoming value, is given by some weight, and the rest of the weight, , to the prior estimate”:
To start the EWMA sequence we define the value for and . A worked example is given further on in this section.
The last line in the equation group above shows that a 1-step-ahead prediction for at time is a weighted sum of two components: the current measured value, , and secondly the predicted value, , with the weights summing up to 1. This gives a way to experimentally find a suitable value from historical data: adjust it up and down until the differences between and the actual measured values of are small.
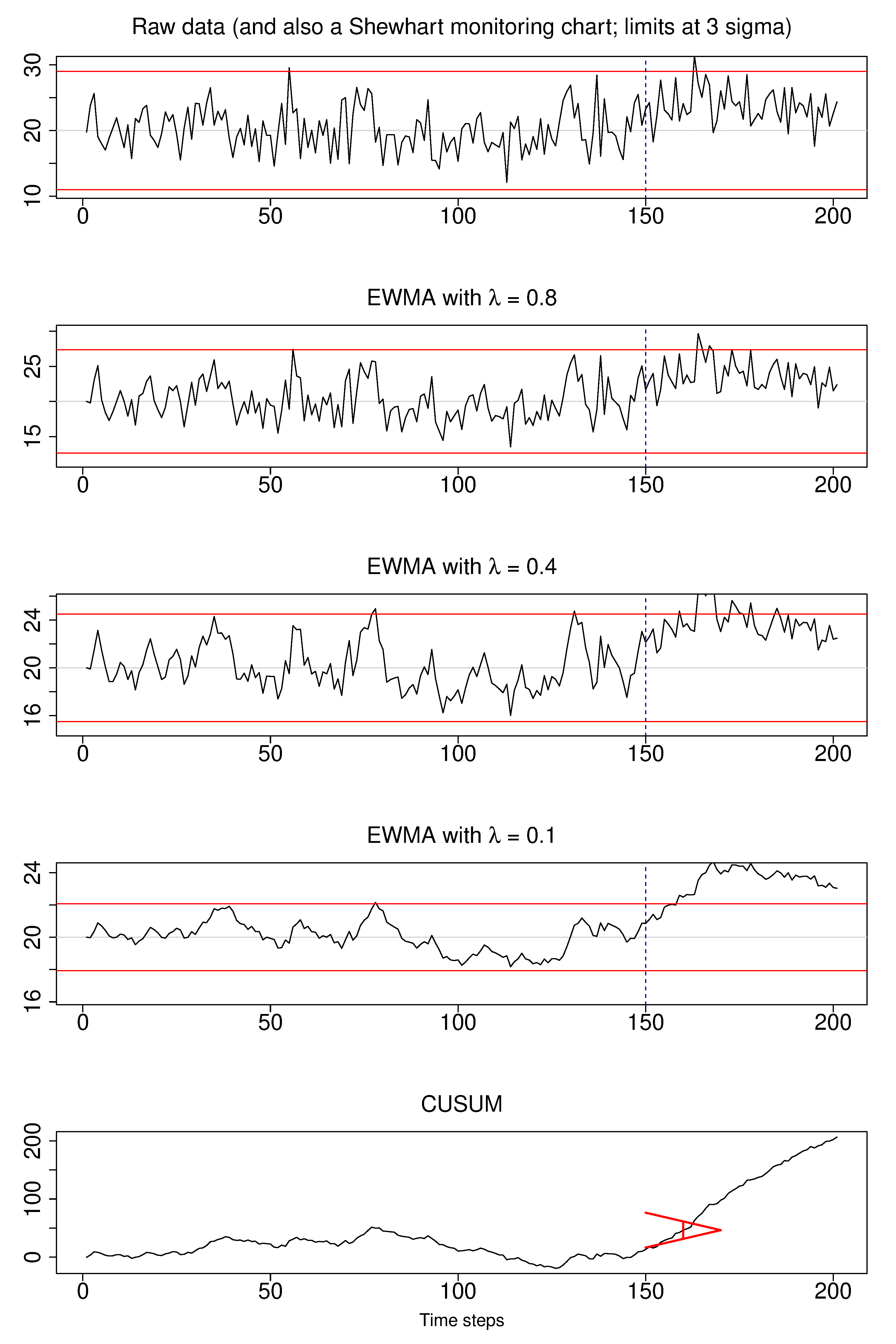
The next plot shows visually what happens as the weight of is changed. In this example a shift of units occurs abruptly at . This is of course not known in practice, but the purpose here is to illustrate the effects of choosing . Prior to that change the process mean is and the raw data has .
The first chart is the raw data and also a Shewhart chart with subgroup size of 1; the control limits are at time the standard deviation, so at 11.0 and 19.0 units. This control chart barely picks up the shift, as was explained in a prior section.
The second, third and fourth charts are EWMA charts with different values of ; the line is the value on the left-hand side of equation (1), in other words it is , the EWMA value at time . We see that as decreases, the charts are smoother, since the averaging effect is greater: more and more weight is given to the history, , and less weight to the current data point, . See equation (1) to understand that interpretation. Also note carefully how the control limits become narrower as the decreases, as is explained shortly below.
To see why represents historical data, you can recursively substitute and show that:
which emphasizes that the prediction is a just a weighted sum of the raw measurements, with weights declining in time.
The final chart of the sequence of 5 charts is a CUSUM chart, which is the ideal chart for picking up such an abrupt shift in the level.
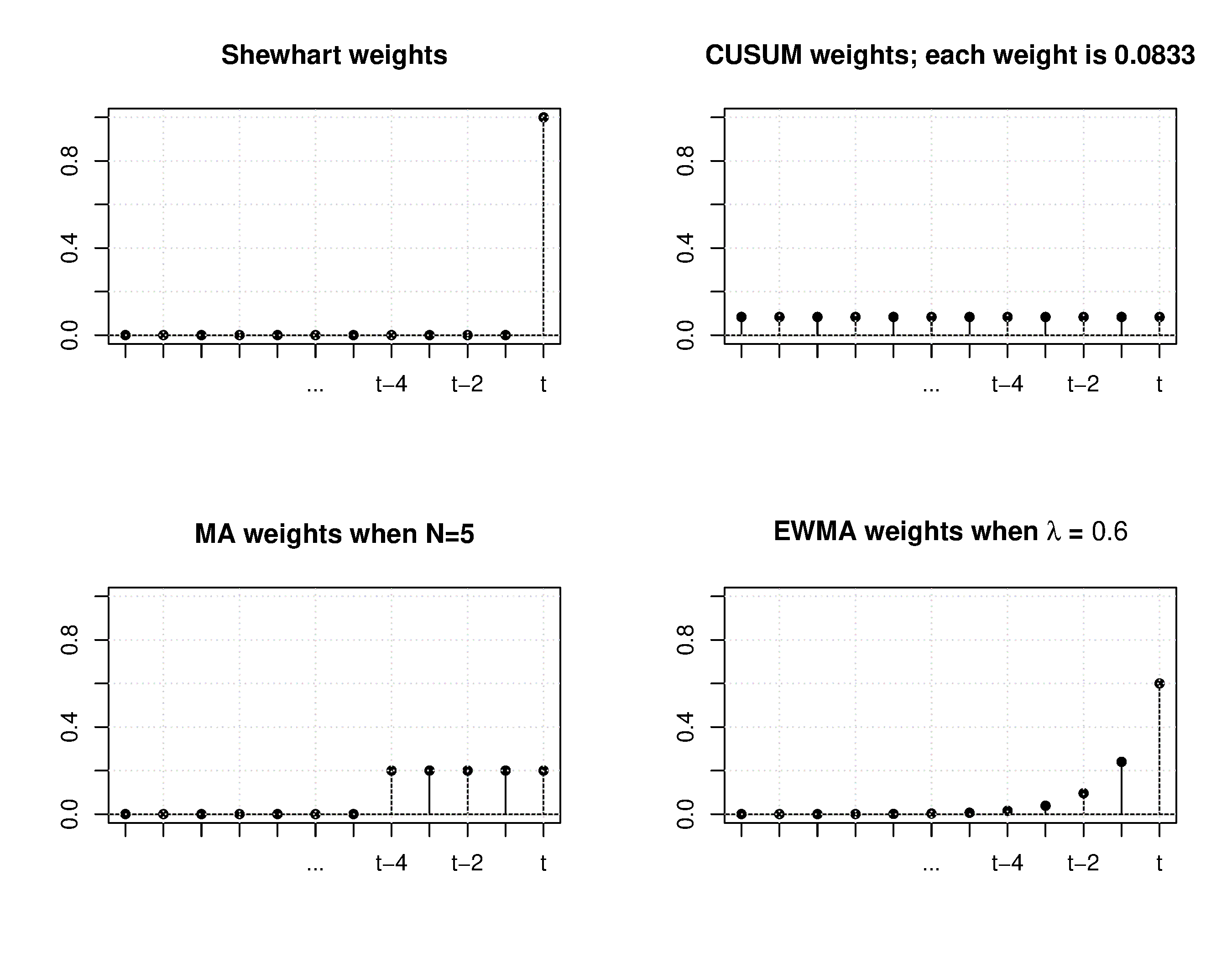
In the next figure, we show a comparison of the weights used in different monitoring charts studied so far.
From the above discussion and the weights shown for the 4 different charts, it should be clear now how an EWMA chart is a tradeoff between a Shewhart chart and a CUSUM chart. As , the EWMA chart behaves more as a Shewhart chart, giving only weight to the most recent observation. While as the EWMA chart starts to have an infinite memory (like a CUSUM chart). There are 12 data points used in the example, so the CUSUM ‘weight’ is one twelfth or .
The upper and lower control limits for the EWMA plot are plotted in the same way as the Shewhart limits, but calculated differently:
where represents the standard deviation as calculated for the Shewhart chart. is usually a value of 3, similar to the 3 standard deviations used in a Shewhart chart, but can of course be set to any level that balances the type I (false alarms) and type II errors (not detecting a deviation which is present already).
An interesting implementation can be to show both the Shewhart and EWMA plot on the same chart, with both sets of limits. The EWMA value plotted is actually the one-step ahead prediction of the next -value, which can be informative for slow-moving processes.
The R code here shows one way of calculating the EWMA values for a vector of data. Once you have pasted this function into R, use it as ewma(x,lambda=...,target=...).
Here is a worked example, starting with the assumption the process is at the target value of units, and . We intentionally show what happens if the new value stays fixed at 190: you see the value plotted gets only a weight of 0.3, while the 0.7 weight is for the prior historical value. Slowly the value plotted catches up, but there is always a lag. The value plotted on the chart is from the last equation in the set of (1).